From Wikipedia, the free encyclopedia
Advanced Vector Extensions (AVX, also known as Gesher New Instructions and then Sandy Bridge New Instructions) are SIMD extensions to the x86 instruction set architecture for microprocessors from Intel and Advanced Micro Devices (AMD). They were proposed by Intel in March 2008 and first supported by Intel with the Sandy Bridge[1] microarchitecture shipping in Q1 2011 and later by AMD with the Bulldozer[2] microarchitecture shipping in Q4 2011. AVX provides new features, new instructions, and a new coding scheme.
AVX2 (also known as Haswell New Instructions) expands most integer commands to 256 bits and introduces new instructions. They were first supported by Intel with the Haswell microarchitecture, which shipped in 2013.
AVX-512 expands AVX to 512-bit support using a new EVEX prefix encoding proposed by Intel in July 2013 and first supported by Intel with the Knights Landing co-processor, which shipped in 2016.[3][4] In conventional processors, AVX-512 was introduced with Skylake server and HEDT processors in 2017.
Advanced Vector Extensions
[edit]
AVX uses sixteen YMM registers to perform a single instruction on multiple pieces of data (see SIMD). Each YMM register can hold and do simultaneous operations (math) on:
- eight 32-bit single-precision floating-point numbers or
- four 64-bit double-precision floating-point numbers.
The width of the SIMD registers is increased from 128 bits to 256 bits, and renamed from XMM0–XMM7 to YMM0–YMM7 (in x86-64 mode, from XMM0–XMM15 to YMM0–YMM15). The legacy SSE instructions can still be utilized via the VEX prefix to operate on the lower 128 bits of the YMM registers.
AVX-512 register scheme as extension from the AVX (YMM0-YMM15) and SSE (XMM0-XMM15) registers
| 511 256 | 255 128 | 127 0 |
| ZMM0 | YMM0 | XMM0 |
| ZMM1 | YMM1 | XMM1 |
| ZMM2 | YMM2 | XMM2 |
| ZMM3 | YMM3 | XMM3 |
| ZMM4 | YMM4 | XMM4 |
| ZMM5 | YMM5 | XMM5 |
| ZMM6 | YMM6 | XMM6 |
| ZMM7 | YMM7 | XMM7 |
| ZMM8 | YMM8 | XMM8 |
| ZMM9 | YMM9 | XMM9 |
| ZMM10 | YMM10 | XMM10 |
| ZMM11 | YMM11 | XMM11 |
| ZMM12 | YMM12 | XMM12 |
| ZMM13 | YMM13 | XMM13 |
| ZMM14 | YMM14 | XMM14 |
| ZMM15 | YMM15 | XMM15 |
| ZMM16 | YMM16 | XMM16 |
| ZMM17 | YMM17 | XMM17 |
| ZMM18 | YMM18 | XMM18 |
| ZMM19 | YMM19 | XMM19 |
| ZMM20 | YMM20 | XMM20 |
| ZMM21 | YMM21 | XMM21 |
| ZMM22 | YMM22 | XMM22 |
| ZMM23 | YMM23 | XMM23 |
| ZMM24 | YMM24 | XMM24 |
| ZMM25 | YMM25 | XMM25 |
| ZMM26 | YMM26 | XMM26 |
| ZMM27 | YMM27 | XMM27 |
| ZMM28 | YMM28 | XMM28 |
| ZMM29 | YMM29 | XMM29 |
| ZMM30 | YMM30 | XMM30 |
| ZMM31 | YMM31 | XMM31 |
AVX introduces a three-operand SIMD instruction format called VEX coding scheme, where the destination register is distinct from the two source operands. For example, an SSE instruction using the conventional two-operand form a ← a + b can now use a non-destructive three-operand form c ← a + b, preserving both source operands. Originally, AVX’s three-operand format was limited to the instructions with SIMD operands (YMM), and did not include instructions with general purpose registers (e.g. EAX). It was later used for coding new instructions on general purpose registers in later extensions, such as BMI. VEX coding is also used for instructions operating on the k0-k7 mask registers that were introduced with AVX-512.
The alignment requirement of SIMD memory operands is relaxed.[5] Unlike their non-VEX coded counterparts, most VEX coded vector instructions no longer require their memory operands to be aligned to the vector size. Notably, the VMOVDQA instruction still requires its memory operand to be aligned.
The new VEX coding scheme introduces a new set of code prefixes that extends the opcode space, allows instructions to have more than two operands, and allows SIMD vector registers to be longer than 128 bits. The VEX prefix can also be used on the legacy SSE instructions giving them a three-operand form, and making them interact more efficiently with AVX instructions without the need for VZEROUPPER and VZEROALL.
The AVX instructions support both 128-bit and 256-bit SIMD. The 128-bit versions can be useful to improve old code without needing to widen the vectorization, and avoid the penalty of going from SSE to AVX, they are also faster on some early AMD implementations of AVX. This mode is sometimes known as AVX-128.[6]
These AVX instructions are in addition to the ones that are 256-bit extensions of the legacy 128-bit SSE instructions; most are usable on both 128-bit and 256-bit operands.
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD, VBROADCASTF128
|
Copy a 32-bit, 64-bit or 128-bit memory operand to all elements of a XMM or YMM vector register. |
VINSERTF128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTF128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VMASKMOVPS, VMASKMOVPD
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. On the AMD Jaguar processor architecture, this instruction with a memory source operand takes more than 300 clock cycles when the mask is zero, in which case the instruction should do nothing. This appears to be a design flaw.[7] |
VPERMILPS, VPERMILPD
|
Permute In-Lane. Shuffle the 32-bit or 64-bit vector elements of one input operand. These are in-lane 256-bit instructions, meaning that they operate on all 256 bits with two separate 128-bit shuffles, so they can not shuffle across the 128-bit lanes.[8] |
VPERM2F128
|
Shuffle the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VTESTPS, VTESTPD
|
Packed bit test of the packed single-precision or double-precision floating-point sign bits, setting or clearing the ZF flag based on AND and CF flag based on ANDN. |
VZEROALL
|
Set all YMM registers to zero and tag them as unused. Used when switching between 128-bit use and 256-bit use. |
VZEROUPPER
|
Set the upper half of all YMM registers to zero. Used when switching between 128-bit use and 256-bit use. |
- Intel
- Sandy Bridge processors (Q1 2011) and newer, except models branded as Celeron and Pentium.[9]
- Pentium and Celeron branded processors starting with Tiger Lake (Q3 2020) and newer.[10]
- AMD:
- Bulldozer processors (Q4 2011) and newer.[11]
Issues regarding compatibility between future Intel and AMD processors are discussed under XOP instruction set.
- VIA:
- Nano QuadCore
- Eden X4
- Zhaoxin:
- WuDaoKou-based processors (KX-5000 and KH-20000)
Compiler and assembler support
[edit]
- Absoft supports with -mavx flag.
- The Free Pascal compiler supports AVX and AVX2 with the -CfAVX and -CfAVX2 switches from version 2.7.1.
- RAD studio (v11.0 Alexandria) supports AVX2 and AVX512.[12]
- The GNU Assembler (GAS) inline assembly functions support these instructions (accessible via GCC), as do Intel primitives and the Intel inline assembler (closely compatible to GAS, although more general in its handling of local references within inline code). GAS supports AVX starting with binutils version 2.19.[13]
- GCC starting with version 4.6 (although there was a 4.3 branch with certain support) and the Intel Compiler Suite starting with version 11.1 support AVX.
- The Open64 compiler version 4.5.1 supports AVX with -mavx flag.
- PathScale supports via the -mavx flag.
- The Vector Pascal compiler supports AVX via the -cpuAVX32 flag.
- The Visual Studio 2010/2012 compiler supports AVX via intrinsic and /arch:AVX switch.
- NASM starting with version 2.03 and newer. There were numerous bug fixes and updates related to AVX in version 2.04.[14]
- Other assemblers such as MASM VS2010 version, YASM,[15] FASM and JWASM.
Operating system support
[edit]
AVX adds new register-state through the 256-bit wide YMM register file, so explicit operating system support is required to properly save and restore AVX’s expanded registers between context switches. The following operating system versions support AVX:
- DragonFly BSD: support added in early 2013.
- FreeBSD: support added in a patch submitted on January 21, 2012,[16] which was included in the 9.1 stable release.[17]
- Linux: supported since kernel version 2.6.30,[18] released on June 9, 2009.[19]
- macOS: support added in 10.6.8 (Snow Leopard) update[20][unreliable source?] released on June 23, 2011. In fact, macOS Ventura does not support x86 processors without the AVX2 instruction set.[21]
- OpenBSD: support added on March 21, 2015.[22]
- Solaris: supported in Solaris 10 Update 10 and Solaris 11.
- Windows: supported in Windows 7 SP1, Windows Server 2008 R2 SP1,[23] Windows 8, Windows 10.
- Windows Server 2008 R2 SP1 with Hyper-V requires a hotfix to support AMD AVX (Opteron 6200 and 4200 series) processors, KB2568088
- Windows XP and Windows Server 2003 do not support AVX in both kernel drivers and user applications.
Advanced Vector Extensions 2
[edit]
Advanced Vector Extensions 2 (AVX2), also known as Haswell New Instructions,[24] is an expansion of the AVX instruction set introduced in Intel’s Haswell microarchitecture. AVX2 makes the following additions:
- expansion of most vector integer SSE and AVX instructions to 256 bits
- Gather support, enabling vector elements to be loaded from non-contiguous memory locations
- DWORD- and QWORD-granularity any-to-any permutes
- vector shifts.
Sometimes three-operand fused multiply-accumulate (FMA3) extension is considered part of AVX2, as it was introduced by Intel in the same processor microarchitecture. This is a separate extension using its own CPUID flag and is described on its own page and not below.
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD
|
Copy a 32-bit or 64-bit register operand to all elements of a XMM or YMM vector register. These are register versions of the same instructions in AVX1. There is no 128-bit version, but the same effect can be simply achieved using VINSERTF128. |
VPBROADCASTB, VPBROADCASTW, VPBROADCASTD, VPBROADCASTQ
|
Copy an 8, 16, 32 or 64-bit integer register or memory operand to all elements of a XMM or YMM vector register. |
VBROADCASTI128
|
Copy a 128-bit memory operand to all elements of a YMM vector register. |
VINSERTI128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTI128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VGATHERDPD, VGATHERQPD, VGATHERDPS, VGATHERQPS
|
Gathers single- or double-precision floating-point values using either 32- or 64-bit indices and scale. |
VPGATHERDD, VPGATHERDQ, VPGATHERQD, VPGATHERQQ
|
Gathers 32 or 64-bit integer values using either 32- or 64-bit indices and scale. |
VPMASKMOVD, VPMASKMOVQ
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. |
VPERMPS, VPERMD
|
Shuffle the eight 32-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERMPD, VPERMQ
|
Shuffle the four 64-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERM2I128
|
Shuffle (two of) the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VPBLENDD
|
Doubleword immediate version of the PBLEND instructions from SSE4. |
VPSLLVD, VPSLLVQ
|
Shift left logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRLVD, VPSRLVQ
|
Shift right logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRAVD
|
Shift right arithmetically. Allows variable shifts where each element is shifted according to the packed input. |
- Intel
- Haswell processors (Q2 2013) and newer, except models branded as Celeron and Pentium.
- Celeron and Pentium branded processors starting with Tiger Lake (Q3 2020) and newer.[10]
- AMD
- Excavator processors (Q2 2015) and newer.
- VIA:
- Nano QuadCore
- Eden X4
AVX-512 are 512-bit extensions to the 256-bit Advanced Vector Extensions SIMD instructions for x86 instruction set architecture proposed by Intel in July 2013.[3]
AVX-512 instructions are encoded with the new EVEX prefix. It allows 4 operands, 8 new 64-bit opmask registers, scalar memory mode with automatic broadcast, explicit rounding control, and compressed displacement memory addressing mode. The width of the register file is increased to 512 bits and total register count increased to 32 (registers ZMM0-ZMM31) in x86-64 mode.
AVX-512 consists of multiple instruction subsets, not all of which are meant to be supported by all processors implementing them. The instruction set consists of the following:
- AVX-512 Foundation (F) – adds several new instructions and expands most 32- and 64-bit floating-point SSE-SSE4.1 and AVX/AVX2 instructions with EVEX coding scheme to support the 512-bit registers, operation masks, parameter broadcasting, and embedded rounding and exception control
- AVX-512 Conflict Detection Instructions (CD) – efficient conflict detection to allow more loops to be vectorized, supported by Knights Landing[3]
- AVX-512 Exponential and Reciprocal Instructions (ER) – exponential and reciprocal operations designed to help implement transcendental operations, supported by Knights Landing[3]
- AVX-512 Prefetch Instructions (PF) – new prefetch capabilities, supported by Knights Landing[3]
- AVX-512 Vector Length Extensions (VL) – extends most AVX-512 operations to also operate on XMM (128-bit) and YMM (256-bit) registers (including XMM16-XMM31 and YMM16-YMM31 in x86-64 mode)[25]
- AVX-512 Byte and Word Instructions (BW) – extends AVX-512 to cover 8-bit and 16-bit integer operations[25]
- AVX-512 Doubleword and Quadword Instructions (DQ) – enhanced 32-bit and 64-bit integer operations[25]
- AVX-512 Integer Fused Multiply Add (IFMA) – fused multiply add for 512-bit integers.[26]: 746
- AVX-512 Vector Byte Manipulation Instructions (VBMI) adds vector byte permutation instructions which are not present in AVX-512BW.
- AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW) – vector instructions for deep learning.
- AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS) – vector instructions for deep learning.
- VPOPCNTDQ – count of bits set to 1.[27]
- VPCLMULQDQ – carry-less multiplication of quadwords.[27]
- AVX-512 Vector Neural Network Instructions (VNNI) – vector instructions for deep learning.[27]
- AVX-512 Galois Field New Instructions (GFNI) – vector instructions for calculating Galois field.[27]
- AVX-512 Vector AES instructions (VAES) – vector instructions for AES coding.[27]
- AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2) – byte/word load, store and concatenation with shift.[27]
- AVX-512 Bit Algorithms (BITALG) – byte/word bit manipulation instructions expanding VPOPCNTDQ.[27]
- AVX-512 Bfloat16 Floating-Point Instructions (BF16) – vector instructions for AI acceleration.
- AVX-512 Half-Precision Floating-Point Instructions (FP16) – vector instructions for operating on floating-point and complex numbers with reduced precision.
Only the core extension AVX-512F (AVX-512 Foundation) is required by all implementations, though all current implementations also support CD (conflict detection). All central processors with AVX-512 also support VL, DQ and BW. The ER, PF, 4VNNIW and 4FMAPS instruction set extensions are currently only implemented in Intel computing coprocessors.
The updated SSE/AVX instructions in AVX-512F use the same mnemonics as AVX versions; they can operate on 512-bit ZMM registers, and will also support 128/256 bit XMM/YMM registers (with AVX-512VL) and byte, word, doubleword and quadword integer operands (with AVX-512BW/DQ and VBMI).[26]: 23
AVX-512 CPU compatibility table
[edit]
|
Subset |
F |
CD |
ER |
PF |
4FMAPS |
4VNNIW |
VPOPCNTDQ |
VL |
DQ |
BW |
IFMA |
VBMI |
VBMI2 |
BITALG |
VNNI |
BF16 |
VPCLMULQDQ |
GFNI |
VAES |
VP2INTERSECT |
FP16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intel Knights Landing (2016) | Yes | Yes | No | ||||||||||||||||||
| Intel Knights Mill (2017) | Yes | No | |||||||||||||||||||
| Intel Skylake-SP, Skylake-X (2017) | No | No | Yes | No | |||||||||||||||||
| Intel Cannon Lake (2018) | Yes | No | |||||||||||||||||||
| Intel Cascade Lake-SP (2019) | No | Yes | No | ||||||||||||||||||
| Intel Cooper Lake (2020) | No | Yes | No | ||||||||||||||||||
| Intel Ice Lake (2019) | Yes | No | Yes | No | |||||||||||||||||
| Intel Tiger Lake (2020) | Yes | No | |||||||||||||||||||
| Intel Rocket Lake (2021) | No | ||||||||||||||||||||
| Intel Alder Lake (2021) | PartialNote 1 | PartialNote 1 | |||||||||||||||||||
| AMD Zen 4 (2022) | Yes | Yes | No | ||||||||||||||||||
| Intel Sapphire Rapids (2023) | No | Yes | |||||||||||||||||||
| AMD Zen 5 (2024) | Yes | No |
[28]
^Note 1 : Intel does not officially support AVX-512 family of instructions on the Alder Lake microprocessors. In early 2022, Intel began disabling in silicon (fusing off) AVX-512 in Alder Lake microprocessors to prevent customers from enabling AVX-512.[29]
In older Alder Lake family CPUs with some legacy combinations of BIOS and microcode revisions, it was possible to execute AVX-512 family instructions when disabling all the efficiency cores which do not contain the silicon for AVX-512.[30][31][32]
Compilers supporting AVX-512
[edit]
- Clang 3.9 and newer[33]
- GCC 4.9 and newer[34]
- ICC 15.0.1 and newer[35]
- Microsoft Visual Studio 2017 C++ Compiler[36]
Assemblers supporting AVX-512
[edit]
- FASM
- NASM 2.11 and newer[14]
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. Similarly, AVX-IFMA is a VEX-coded variant of AVX512-IFMA. These extensions provide the same sets of operations as their AVX-512 counterparts, but are limited to 256-bit vectors and do not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. These extensions allow support of VNNI and IFMA operations even when full AVX-512 support is not implemented in the processor.
- Intel
- Alder Lake processors (Q4 2021) and newer.
- AMD
- Zen 5 processors (Q3 2024) and newer.[37]
- Intel
- Sierra Forest E-core-only Xeon processors (Q2 2024) and newer.
- Grand Ridge special-purpose processors and newer.
- Meteor Lake mobile processors (Q4 2023) and newer.
- Arrow Lake desktop processors (Q4 2024) and newer.
AVX10, announced in July 2023,[38] is a new, «converged» AVX instruction set. It addresses several issues of AVX-512, in particular that it is split into too many parts[39] (20 feature flags). The initial technical paper also made 512-bit vectors optional to support, but as of revision 3.0 vector length enumeration is removed and 512-bit vectors are mandatory.[40]
AVX10 presents a simplified CPUID interface to test for instruction support, consisting of the AVX10 version number (indicating the set of instructions supported, with later versions always being a superset of an earlier one).[41] For example, AVX10.2 indicates that a CPU is capable of the second version of AVX10.[42] Initial revisions of the AVX10 technical specifications also included maximum supported vector length as part of the ISA extension name, e.g. AVX10.2/256 would mean a second version of AVX10 with vector length up to 256 bits, but later revisions made that unnecessary.
The first version of AVX10, notated AVX10.1, does not introduce any instructions or encoding features beyond what is already in AVX-512 (specifically, in Intel Sapphire Rapids: AVX-512F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, BITALG, VNNI, GFNI, VPOPCNTDQ, VPCLMULQDQ, VAES, BF16, FP16). For CPUs supporting AVX10 and 512-bit vectors, all legacy AVX-512 feature flags will remain set to facilitate applications supporting AVX-512 to continue using AVX-512 instructions.[42]
AVX10.1 was first released in Intel Granite Rapids[42] (Q3 2024) and AVX10.2 will be available in Diamond Rapids.[43]
APX is a new extension. It is not focused on vector computation, but provides RISC-like extensions to the x86-64 architecture by doubling the number of general-purpose registers to 32 and introducing three-operand instruction formats. AVX is only tangentially affected as APX introduces extended operands.[44][45]
- Suitable for floating-point-intensive calculations in multimedia, scientific and financial applications (AVX2 adds support for integer operations).
- Increases parallelism and throughput in floating-point SIMD calculations.
- Reduces register load due to the non-destructive instructions.
- Improves Linux RAID software performance (requires AVX2, AVX is not sufficient)[46]
- Cryptography
- BSAFE C toolkits uses AVX and AVX2 where appropriate to accelerate various cryptographic algorithms.[47]
- OpenSSL uses AVX- and AVX2-optimized cryptographic functions since version 1.0.2.[48] Support for AVX-512 was added in version 3.0.0.[49] Some of these optimizations are also present in various clones and forks, like LibreSSL.
- Multimedia
- Blender uses AVX, AVX2 and AVX-512 in the Cycles render engine.[50]
- Native Instruments’ Massive X softsynth requires AVX.[51]
- dav1d AV1 decoder can use AVX2 and AVX-512 on supported CPUs.[52][53]
- SVT-AV1 AV1 encoder can use AVX2 and AVX-512 to accelerate video encoding.[54]
- Science, engineering an others
- Esri ArcGIS Data Store uses AVX2 for graph storage.[55]
- Prime95/MPrime, the software used for GIMPS, started using the AVX instructions since version 27.1, AVX2 since 28.6 and AVX-512 since 29.1.[56]
- Einstein@Home uses AVX in some of their distributed applications that search for gravitational waves.[57]
- TensorFlow since version 1.6 and tensorflow above versions requires CPU supporting at least AVX.[58]
- EmEditor 19.0 and above uses AVX2 to speed up processing.[59]
- Microsoft Teams uses AVX2 instructions to create a blurred or custom background behind video chat participants,[60] and for background noise suppression.[61]
- simdjson, a JSON parsing library, uses AVX2 and AVX-512 to achieve improved decoding speed.[62][63]
- x86-simd-sort, a library with sorting algorithms for 16, 32 and 64-bit numeric data types, uses AVX2 and AVX-512. The library is used in NumPy and OpenJDK to accelerate sorting algorithms.[64]
- Tesseract OCR engine uses AVX, AVX2 and AVX-512 to accelerate character recognition.[65]
Since AVX instructions are wider, they consume more power and generate more heat. Executing heavy AVX instructions at high CPU clock frequencies may affect CPU stability due to excessive voltage droop during load transients. Some Intel processors have provisions to reduce the Turbo Boost frequency limit when such instructions are being executed. This reduction happens even if the CPU hasn’t reached its thermal and power consumption limits.
On Skylake and its derivatives, the throttling is divided into three levels:[66][67]
- L0 (100%): The normal turbo boost limit.
- L1 (~85%): The «AVX boost» limit. Soft-triggered by 256-bit «heavy» (floating-point unit: FP math and integer multiplication) instructions. Hard-triggered by «light» (all other) 512-bit instructions.
- L2 (~60%):[dubious – discuss] The «AVX-512 boost» limit. Soft-triggered by 512-bit heavy instructions.
The frequency transition can be soft or hard. Hard transition means the frequency is reduced as soon as such an instruction is spotted; soft transition means that the frequency is reduced only after reaching a threshold number of matching instructions. The limit is per-thread.[66]
In Ice Lake, only two levels persist:[68]
- L0 (100%): The normal turbo boost limit.
- L1 (~97%): Triggered by any 512-bit instructions, but only when single-core boost is active; not triggered when multiple cores are loaded.
Rocket Lake processors do not trigger frequency reduction upon executing any kind of vector instructions regardless of the vector size.[68] However, downclocking can still happen due to other reasons, such as reaching thermal and power limits.
Downclocking means that using AVX in a mixed workload with an Intel processor can incur a frequency penalty. Avoiding the use of wide and heavy instructions help minimize the impact in these cases. AVX-512VL allows for using 256-bit or 128-bit operands in AVX-512 instructions, making it a sensible default for mixed loads.[69]
On supported and unlocked variants of processors that down-clock, the clock ratio reduction offsets (typically called AVX and AVX-512 offsets) are adjustable and may be turned off entirely (set to 0x) via Intel’s Overclocking / Tuning utility or in BIOS if supported there.[70]
- F16C instruction set extension
- Memory Protection Extensions
- Scalable Vector Extension for ARM — a new vector instruction set (supplementing VFP and NEON) similar to AVX-512, with some additional features.
- ^ Kanter, David (September 25, 2010). «Intel’s Sandy Bridge Microarchitecture». www.realworldtech.com. Retrieved February 17, 2018.
- ^ Hruska, Joel (October 24, 2011). «Analyzing Bulldozer: Why AMD’s chip is so disappointing — Page 4 of 5 — ExtremeTech». ExtremeTech. Retrieved February 17, 2018.
- ^ a b c d e James Reinders (July 23, 2013), AVX-512 Instructions, Intel, retrieved August 20, 2013
- ^ «Intel Xeon Phi Processor 7210 (16GB, 1.30 GHz, 64 core) Product Specifications». Intel ARK (Product Specs). Retrieved March 16, 2018.
- ^ «14.9». Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture (PDF) (-051US ed.). Intel Corporation. p. 349. Retrieved August 23, 2014.
Memory arguments for most instructions with VEX prefix operate normally without causing #GP(0) on any byte-granularity alignment (unlike Legacy SSE instructions).
- ^ «i386 and x86-64 Options — Using the GNU Compiler Collection (GCC)». Retrieved February 9, 2014.
- ^ «The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers» (PDF). Retrieved October 17, 2016.
- ^ «Chess programming AVX2». Archived from the original on July 10, 2017. Retrieved October 17, 2016.
- ^ «Intel Offers Peek at Nehalem and Larrabee». ExtremeTech. March 17, 2008.
- ^ a b «Intel® Celeron® 6305 Processor (4M Cache, 1.80 GHz, with IPU) Product Specifications». ark.intel.com. Retrieved November 10, 2020.
- ^ Butler, Michael; Barnes, Leslie; Das Sarma, Debjit; Gelinas, Bob (March–April 2011). «Bulldozer: An Approach to Multithreaded Compute Performance» (PDF). IEEE Micro. 31 (2): 6–15. doi:10.1109/MM.2011.23. S2CID 28236214. Archived from the original (PDF) on May 19, 2024.
- ^ «What’s New — RAD Studio». docwiki.embarcadero.com. Retrieved September 17, 2021.
- ^ «GAS Changes». sourceware.org. Retrieved May 3, 2024.
- ^ a b «NASM — The Netwide Assembler, Appendix C: NASM Version History». nasm.us. Retrieved May 3, 2024.
- ^ «YASM 0.7.0 Release Notes». yasm.tortall.net.
- ^ Add support for the extended FPU states on amd64, both for native 64bit and 32bit ABIs, svnweb.freebsd.org, January 21, 2012, retrieved January 22, 2012
- ^ «FreeBSD 9.1-RELEASE Announcement». Retrieved May 20, 2013.
- ^ x86: add linux kernel support for YMM state, retrieved July 13, 2009
- ^ Linux 2.6.30 — Linux Kernel Newbies, retrieved July 13, 2009
- ^ Twitter, retrieved June 23, 2010
- ^ «Devs are making progress getting macOS Ventura to run on unsupported, decade-old Macs». August 23, 2022.
- ^ Add support for saving/restoring FPU state using the XSAVE/XRSTOR., retrieved March 25, 2015
- ^ Floating-Point Support for 64-Bit Drivers, retrieved December 6, 2009
- ^ Haswell New Instruction Descriptions Now Available, Software.intel.com, retrieved January 17, 2012
- ^ a b c James Reinders (July 17, 2014). «Additional AVX-512 instructions». Intel. Retrieved August 3, 2014.
- ^ a b «Intel Architecture Instruction Set Extensions Programming Reference» (PDF). Intel. Retrieved January 29, 2014.
- ^ a b c d e f g «Intel® Architecture Instruction Set Extensions and Future Features Programming Reference». Intel. Retrieved October 16, 2017.
- ^ «Intel® Software Development Emulator | Intel® Software». software.intel.com. Retrieved June 11, 2016.
- ^ Alcorn, Paul (March 2, 2022). «Intel Nukes Alder Lake’s AVX-512 Support, Now Fuses It Off in Silicon». Tom’s Hardware. Retrieved March 7, 2022.
- ^ Cutress, Ian; Frumusanu, Andrei (August 19, 2021). «Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed». AnandTech. Retrieved August 25, 2021.
- ^ Alcorn, Paul (August 19, 2021). «Intel Architecture Day 2021: Alder Lake Chips, Golden Cove and Gracemont Cores». Tom’s Hardware. Retrieved August 21, 2021.
- ^ Cutress, Ian; Frumusanu, Andrei. «The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity». www.anandtech.com. Retrieved November 5, 2021.
- ^ «LLVM 3.9 Release Notes — LLVM 3.9 documentation». releases.llvm.org. Retrieved April 3, 2017.
- ^ «GCC 4.9 Release Series — Changes, New Features, and Fixes – GNU Project — Free Software Foundation (FSF)». gcc.gnu.org. Retrieved April 3, 2017.
- ^ «Intel® Parallel Studio XE 2015 Composer Edition C++ Release Notes | Intel® Software». software.intel.com. Retrieved April 3, 2017.
- ^ «Microsoft Visual Studio 2017 Supports Intel® AVX-512». July 11, 2017.
- ^ «AMD Zen 5 Compiler Support Posted For GCC — Confirms New AVX Features & More». www.phoronix.com. Retrieved February 10, 2024.
- ^ Bonshor, Gavin (July 25, 2023). «Intel Unveils AVX10 and APX Instruction Sets: Unifying AVX-512 For Hybrid Architectures». AnandTech. Retrieved August 21, 2024.
- ^ Mann, Tobias (August 15, 2023). «Intel’s AVX10 promises benefits of AVX-512 without baggage». www.theregister.com. Retrieved August 20, 2023.
- ^ Larabel, Michael (March 19, 2025). «Intel AVX10 Drops Optional 512-bit: No AVX10 256-bit Only E-Cores In The Future». Phoronix. Retrieved March 19, 2025.
- ^ «The Converged Vector ISA: Intel® Advanced Vector Extensions 10 Technical Paper». Intel.
- ^ a b c «Intel® Advanced Vector Extensions 10 (Intel® AVX10) Architecture Specification». Intel.
- ^ Larabel, Michael (October 23, 2024). «Intel Preps GCC Compiler For New AMX & ISA Features Ahead Of Diamond Rapids». Phoronix. Retrieved October 23, 2024.
- ^ «Intel® Advanced Performance Extensions (Intel® APX) Architecture Specification». Intel.
- ^ Robinson, Dan (July 26, 2023). «Intel discloses x86 and vector instructions for future chips». www.theregister.com. Retrieved August 20, 2023.
- ^ «Linux RAID». LWN. February 17, 2013. Archived from the original on April 15, 2013.
- ^ «Comparison of BSAFE cryptographic library implementations». July 25, 2023.
- ^ «Improving OpenSSL Performance». May 26, 2015. Retrieved February 28, 2017.
- ^ «OpenSSL 3.0.0 release notes». GitHub. September 7, 2021.
- ^ Jaroš, Milan; Strakoš, Petr; Říha, Lubomír (May 28, 2022). «Rendering in Blender using AVX-512 Vectorization» (PDF). Intel eXtreme Performance Users Group. Technical University of Ostrava. Retrieved October 28, 2022.
- ^ «MASSIVE X Requires AVX Compatible Processor». Native Instruments. Retrieved November 29, 2019.
- ^ «dav1d: performance and completion of the first release». November 21, 2018. Retrieved November 22, 2018.
- ^ «dav1d 0.6.0 release notes». March 6, 2020.
- ^ «SVT-AV1 0.7.0 release notes». September 26, 2019.
- ^ «ArcGIS Data Store 11.2 System Requirements». ArcGIS Enterprise. Retrieved January 24, 2024.
- ^ «Prime95 release notes». Retrieved July 10, 2022.
- ^ «Einstein@Home Applications».
- ^ «Tensorflow 1.6». GitHub.
- ^ New in Version 19.0 – EmEditor (Text Editor)
- ^ «Hardware requirements for Microsoft Teams». Microsoft. Retrieved April 17, 2020.
- ^ «Reduce background noise in Teams meetings». Microsoft Support. Retrieved January 5, 2021.
- ^ Langdale, Geoff; Lemire, Daniel (2019). «Parsing Gigabytes of JSON per Second». The VLDB Journal. 28 (6): 941–960. arXiv:1902.08318. doi:10.1007/s00778-019-00578-5. S2CID 67856679.
- ^ «simdjson 2.1.0 release notes». GitHub. June 30, 2022.
- ^ Larabel, Michael (October 6, 2023). «OpenJDK Merges Intel’s x86-simd-sort For Speeding Up Data Sorting 7~15x». Phoronix.
- ^ Larabel, Michael (July 7, 2022). «Tesseract OCR 5.2 Engine Finds Success With AVX-512F». Phoronix.
- ^ a b Lemire, Daniel (September 7, 2018). «AVX-512: when and how to use these new instructions». Daniel Lemire’s blog.
- ^ BeeOnRope. «SIMD instructions lowering CPU frequency». Stack Overflow.
- ^ a b Downs, Travis (August 19, 2020). «Ice Lake AVX-512 Downclocking». Performance Matters blog.
- ^ «x86 — AVX 512 vs AVX2 performance for simple array processing loops». Stack Overflow.
- ^ «Intel® Extreme Tuning Utility (Intel® XTU) Guide to Overclocking : Advanced Tuning». Intel. Retrieved July 18, 2021.
See image in linked section, where AVX2 ratio has been set to 0.
- Intel Intrinsics Guide
- x86 Assembly Language Reference Manual
Modern CPUs are constantly evolving to provide faster and more efficient processing power. One significant advancement is the introduction of CPUs that support AVX instructions. AVX, or Advanced Vector Extensions, is a set of instructions that allows for enhanced parallelism and increased performance in tasks that involve large amounts of data processing. With AVX, CPUs can handle complex calculations and data manipulation more efficiently, resulting in improved performance and faster execution times.
CPU architectures that support AVX instructions have become increasingly important in various fields, such as scientific research, data analysis, and multimedia applications. These instructions enable CPUs to perform simultaneous operations on multiple data elements, known as SIMD (Single Instruction, Multiple Data) operations. By utilizing SIMD, AVX-enabled CPUs can process multiple data elements at once, significantly increasing the efficiency of tasks like image and video editing, scientific simulations, and encryption algorithms. This improved performance translates into faster rendering times, quicker data analysis, and a more seamless user experience across a wide range of applications.
A CPU that supports AVX instructions is essential for running highly optimized software applications and tasks. AVX (Advanced Vector Extensions) is a set of instructions that accelerates floating-point and certain integer operations. With AVX support, you can experience enhanced performance in areas such as numerical computations, multimedia processing, and scientific simulations. It enables faster data processing and improved efficiency, making it an ideal choice for professionals in fields like video editing, 3D rendering, and financial modeling.
Introduction to AVX Instructions in CPU
Modern CPUs are packed with advanced features and instructions to optimize performance in various applications. One such crucial instruction set is AVX (Advanced Vector Extensions). AVX instructions offer enhanced capabilities for performing parallel operations on large amounts of data simultaneously, making them particularly valuable for tasks involving multimedia, scientific calculations, and artificial intelligence. In this article, we will explore the concept of CPUs that support AVX instructions, their benefits, and some popular examples in the market.
What are AVX Instructions?
AVX (Advanced Vector Extensions) is a set of instructions introduced by Intel in 2011 and later adopted by AMD processors. These instructions extend the capabilities of the CPU by allowing it to perform data-parallel computations on large sets of data simultaneously. AVX instructions operate on SIMD (Single Instruction, Multiple Data) principles, where a single instruction is executed on multiple data elements simultaneously, improving overall processing efficiency and performance.
The AVX instruction set expands on the SSE (Streaming SIMD Extensions) instructions that have been present in CPUs for quite some time. AVX instructions operate on 128-bit and 256-bit registers, allowing for parallel processing of multiple data elements.
AVX provides several benefits, including increased performance in multimedia and scientific applications that can leverage parallel processing. These instructions are particularly useful in tasks such as 3D modeling and rendering, video encoding and decoding, image processing, and data analysis.
Benefits of AVX Instructions:
- Improved performance in multimedia applications
- Enhanced capabilities for scientific calculations
- Accelerated 3D modeling and rendering
- Efficient video encoding and decoding
- Faster image processing and manipulation
Popular CPUs that Support AVX Instructions
Many modern CPUs support AVX instructions, enabling users to take advantage of parallel computing. Here are some popular CPUs that support AVX instructions:
| Processor | AVX Version | Year of Release |
| Intel Core i7-10700K | AVX-512 | 2020 |
| AMD Ryzen 9 5950X | AVX2 | 2020 |
| Intel Core i9-9900K | AVX-512 | 2018 |
| AMD Ryzen 7 5800X | AVX2 | 2020 |
These CPUs offer advanced AVX support, allowing users to harness the power of parallel processing in a wide range of applications.
Performance Impact and Considerations
While AVX instructions provide significant performance benefits, it is essential to consider a few factors:
- Thermal considerations: AVX instructions can consume more power and generate additional heat. Ensure that the CPU cooling solution can handle the increased thermal load.
- Compatibility: AVX instructions come in different versions (AVX, AVX2, AVX-512), and the level of compatibility depends on the specific CPU model. Ensure that the software or application you intend to use can utilize the specific AVX version supported by your CPU.
- Application optimization: Not all applications can take full advantage of AVX instructions. Certain tasks, such as gaming or older software, may not benefit significantly from AVX capabilities.
Tips for Maximizing AVX Performance:
- Use software that is optimized to take advantage of AVX instructions.
- Ensure proper cooling to manage increased power consumption and heat dissipation.
- Regularly update the CPU firmware to benefit from optimizations and bug fixes.
Exploring Advanced Features of CPUs with AVX Instructions
In addition to the benefits and considerations discussed earlier, CPUs that support AVX instructions offer additional advanced features that further enhance performance and efficiency in specific use cases. Let us explore some of these features:
Fused Multiply-Add (FMA)
Fused Multiply-Add (FMA) is an advanced arithmetic operation that combines multiplication and addition into a single instruction. CPUs that support AVX typically provide FMA instructions, which offer significant performance improvements in tasks involving complex mathematical calculations. FMA instructions can be especially beneficial in applications related to engineering, scientific computing, and financial modeling.
Benefits of Fused Multiply-Add:
- Increased computational power by performing multiplication and addition simultaneously
- Reduced memory accesses and improved cache efficiency
- Enhanced accuracy in floating-point operations
AVX-512 Instructions
AVX-512 is the latest extension to the AVX instruction set, introduced by Intel with their Xeon Phi processors. AVX-512 supports 512-bit registers that can accommodate even larger amounts of data for parallel processing. These instructions provide even higher performance capabilities, particularly in specialized workloads such as data analytics, machine learning, and simulation.
Benefits of AVX-512:
- Parallel processing on a larger scale with 512-bit registers
- Increased performance in high-performance computing (HPC) applications
- Optimized for data-intensive workloads
Improved Energy Efficiency
CPU architectures that support AVX instructions often come with power management features to ensure optimal energy efficiency without sacrificing performance. These features include dynamic voltage and frequency scaling (DVFS) and advanced power gating techniques. With these capabilities, CPUs can deliver high performance when required while minimizing power consumption during idle or low-demand periods.
Key Advantages of Improved Energy Efficiency:
- Reduced power consumption and energy costs
- Minimized environmental impact
- Extended battery life in mobile devices
These energy-efficient features make AVX-enabled CPUs suitable for both high-performance computing environments and energy-conservative systems.
Enhanced Security Measures
Some CPUs that support AVX instructions also integrate advanced security features to protect against potential vulnerabilities and attacks. These security measures include hardware-level mitigations for vulnerabilities like Spectre and Meltdown, as well as new instructions designed to enhance data protection and secure cryptographic operations. These security enhancements play a vital role in safeguarding sensitive data and ensuring system integrity.
Benefits of Enhanced Security Measures:
- Improved protection against vulnerabilities and attacks
- Enhanced data privacy and integrity
- Secure cryptographic operations
These built-in security features provide an additional layer of protection for systems utilizing AVX-enabled CPUs.

CPU Models That Support AVX Instructions
Advanced Vector Extensions (AVX) are a set of CPU instructions that enable faster performance for certain tasks in applications like image and video processing, scientific simulations, and artificial intelligence. AVX instructions can greatly enhance the capabilities of a CPU, improving overall system performance.
To determine if your CPU supports AVX instructions, you can check the specifications provided by the manufacturer. Some popular CPU models that support AVX instructions include:
- Intel Core i7-10700K
- AMD Ryzen 9 5950X
- Intel Core i9-10900K
- AMD Threadripper 3990X
- Intel Xeon W-3175X
These CPUs offer excellent performance for AVX workloads and are widely used in professional-grade applications. It is important to check the specific model and generation of the CPU, as AVX support may vary between different iterations of the same brand and model.
CPU That Supports AVX Instructions
- AVX instructions refer to Advanced Vector Extensions, which are sets of instructions designed to improve performance in applications that require intensive floating-point and vector operations.
- Not all CPUs support AVX instructions, so it is important to check if your CPU is capable of running AVX code.
- AVX instructions can significantly boost performance in tasks such as video editing, 3D rendering, scientific simulations, and machine learning.
- Most modern CPUs from Intel and AMD support AVX instructions, including Intel Core i7 and i9 processors, as well as AMD Ryzen processors.
- If you are unsure whether your CPU supports AVX instructions, you can check the specifications on the manufacturer’s website or consult the documentation that came with your CPU.
Frequently Asked Questions
In this section, we’ll answer some common questions about CPUs that support AVX instructions.
1. What does AVX instruction support mean for a CPU?
AVX (Advanced Vector Extensions) is a set of instructions that help CPUs perform parallel computations on large amounts of data. A CPU that supports AVX instructions can execute these instructions, leading to improved performance in tasks such as multimedia processing, scientific simulations, and data analysis.
By utilizing AVX instructions, CPUs can process multiple sets of data simultaneously, which significantly speeds up certain types of computations. This can be particularly beneficial for professionals who work with graphics-intensive applications, rendering software, or complex mathematical models.
2. How can I check if my CPU supports AVX instructions?
To determine if your CPU supports AVX instructions, you can check the specifications of your CPU model. Most CPUs released in recent years include AVX support. You can find this information on the manufacturer’s website or by referring to the product documentation.
Alternatively, you can use software tools like CPU-Z or Speccy to check the AVX support of your CPU. These tools provide detailed information about your computer’s hardware, including the supported instruction sets.
3. Are there different versions of AVX instructions?
Yes, there are different versions of AVX instructions. AVX instructions were first introduced with Intel’s Sandy Bridge processors, and since then, there have been two major revisions: AVX2 and AVX-512.
AVX2, introduced with Intel’s Haswell processors, adds more instructions and wider vector registers, allowing for even greater parallelism and improved performance. AVX-512, introduced with Intel’s Skylake-X processors, further expands the instruction set and introduces wider vector registers, enabling even more efficient parallel processing.
4. Can I use AVX instructions on any software?
Not all software is optimized to take full advantage of AVX instructions. While many multimedia applications, scientific software, and programming frameworks are designed to utilize AVX instructions, not all software developers have implemented AVX support in their applications.
You can check whether a specific software application supports AVX instructions by referring to its documentation or contacting the software developer. Utilizing AVX instructions can provide significant performance enhancements in supported applications, so it’s worth considering when choosing software for CPU-intensive tasks.
5. Are there any downsides to using AVX instructions?
While AVX instructions can greatly improve performance in certain applications, they can also lead to increased power consumption and heat generation. AVX instructions require more power and can cause the CPU to run hotter, especially during intensive workloads.
It’s important to ensure that your CPU is properly cooled and that your system has sufficient power capacity when using AVX instructions extensively. Additionally, some older software or hardware may not be compatible with AVX instructions, which could limit their usage in certain scenarios.
In conclusion, CPUs that support AVX instructions are becoming increasingly important in the world of computing. These instructions allow for faster and more efficient processing of data, making them essential for tasks that require intensive calculations and complex algorithms.
With the growing demand for high-performance computing, CPUs with AVX instructions are becoming a standard feature in many devices, from desktop computers to servers. They enable improved performance and enhanced capabilities for applications such as artificial intelligence, scientific simulations, and video editing.
Аббревиатура AVX расшифровывается как Advanced Vector Extensions. Это наборы инструкций для процессоров Intel и AMD, идея создания которых появилась в марте 2008 года. Впервые такой набор был встроен в процессоры линейки Intel Haswell в 2013 году. Поддержка команд в Pentium и Celeron появилась лишь в 2020 году.
Прочитав эту статью, вы более подробно узнаете, что такое инструкции AVX и AVX2 для процессоров, а также — как узнать поддерживает ли процессор AVX.
Содержание статьи:
AVX и AVX2 – что это такое
AVX/AVX2 — это улучшенные версии старых наборов команд SSE. Advanced Vector Extensions расширяют операционные пакеты со 128 до 512 бит, а также добавляют новые инструкции. Например, за один такт процессора без инструкций AVX будет сложена 1 пара чисел, а с ними — 10. Эти наборы расширяют спектр используемых чисел для оптимизации подсчёта данных.
Наличие у процессоров поддержки AVX весьма желательно. Эти инструкции предназначены, прежде всего, для выполнения сложных профессиональных операций. Без поддержки AVX всё-таки можно запускать большинство игр, редактировать фото, смотреть видео, общаться в интернете и др., хотя и не так комфортно.
Как узнать, поддерживает ли процессор AVX
Далее будут показаны несколько простых способов узнать это. Некоторые из методов потребуют установки специального ПО.
1. Таблица сравнения процессоров на сайте Chaynikam.info.
Для того чтобы узнать, поддерживает ли ваш процессор инструкции AVX, можно воспользоваться предлагаемым способом. Перейдите на этот сайт. В правом верхнем углу страницы расположена зелёная кнопка Добавить процессор. Нажмите её.
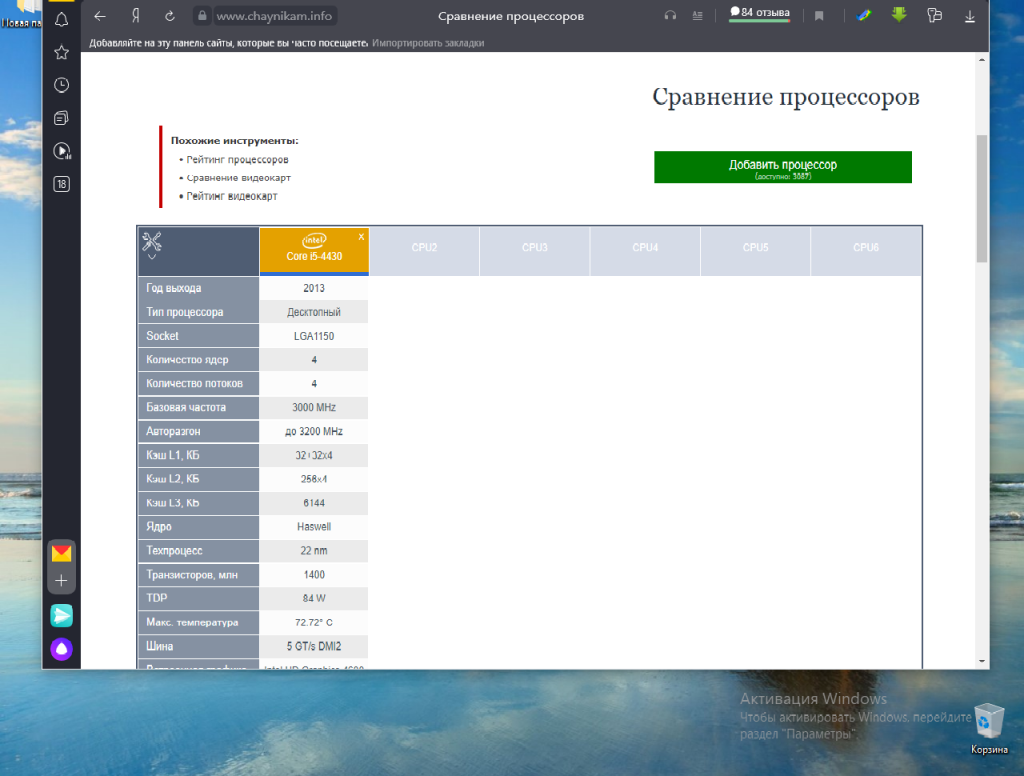
В открывшемся окне вам будет предложено указать параметры выбора нужного процессора. Все указывать не обязательно.
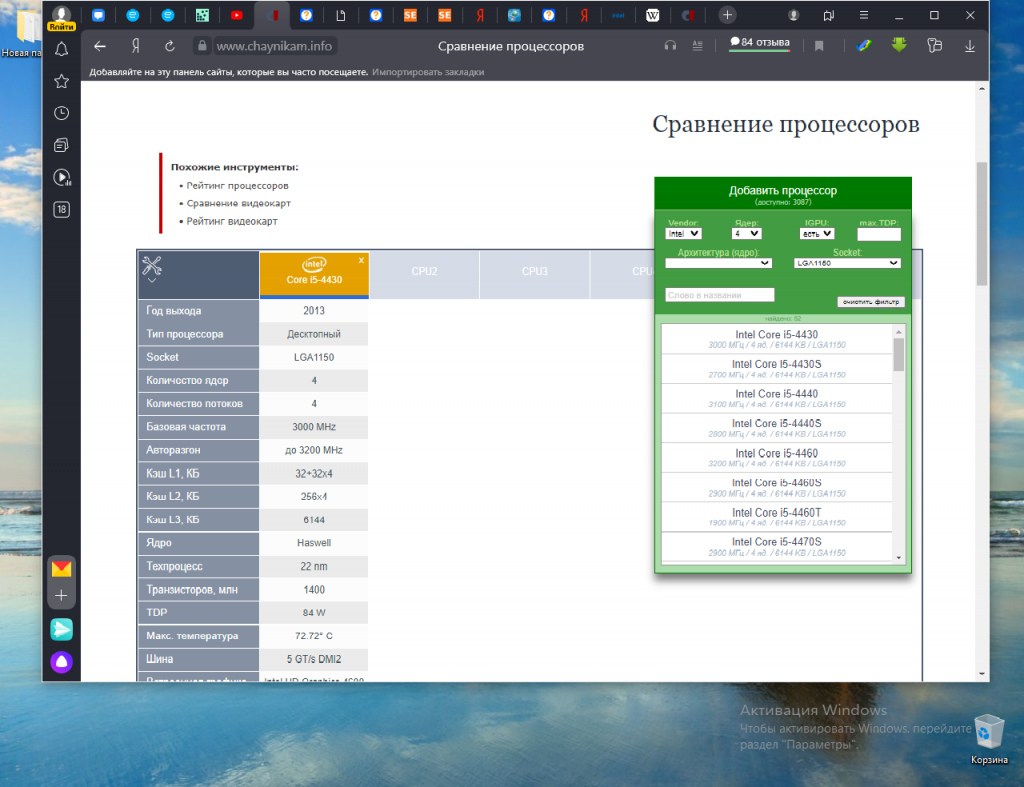
В результате выполнения поиска будет сформирована таблица с параметрами выбранного из списка процессора. Прокрутите таблицу вниз. В строке Поддержка инструкций и технологий будет показана подробная информация.
2. Утилита CPU-Z.
Один из самых простых и надёжных способов узнать поддерживает ли процессор AVX инструкции, использовать утилиту для просмотра информации о процессоре — CPU-Z. Скачать утилиту можно на официальном сайте. После завершения установки ярлык для запуска утилиты появится на рабочем столе. Запустите её.
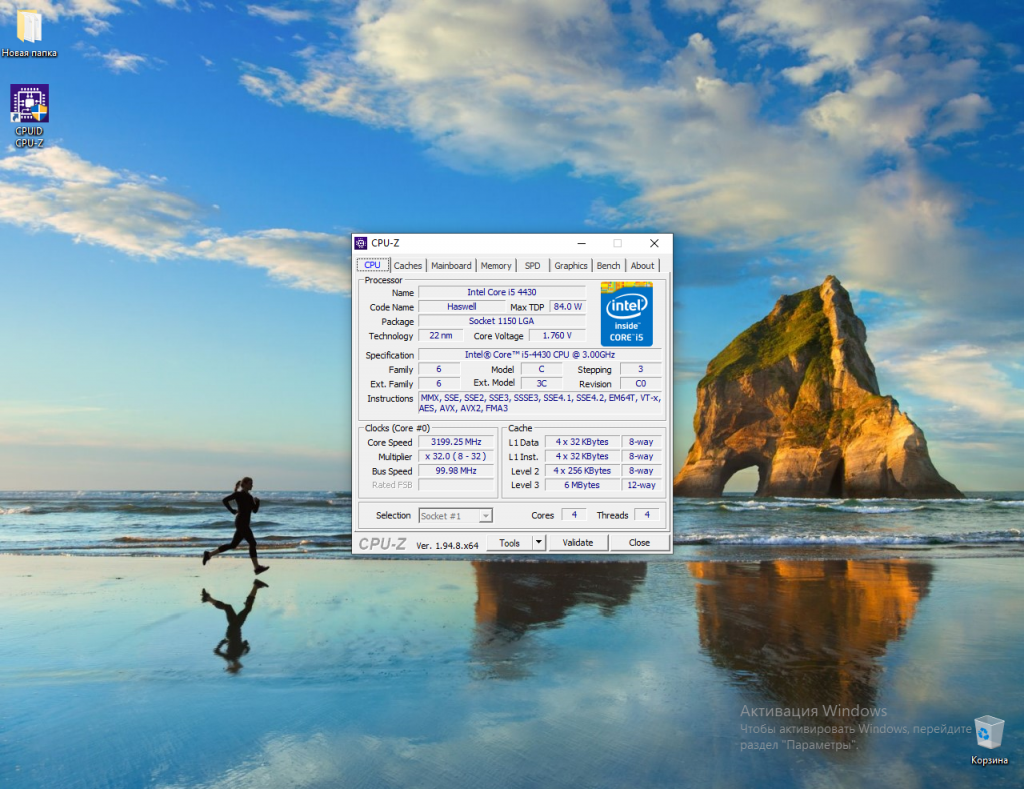
В строке Instructions показаны все инструкции и другие технологии, поддерживаемые вашим процессором.
3. Поиск на сайте производителя.
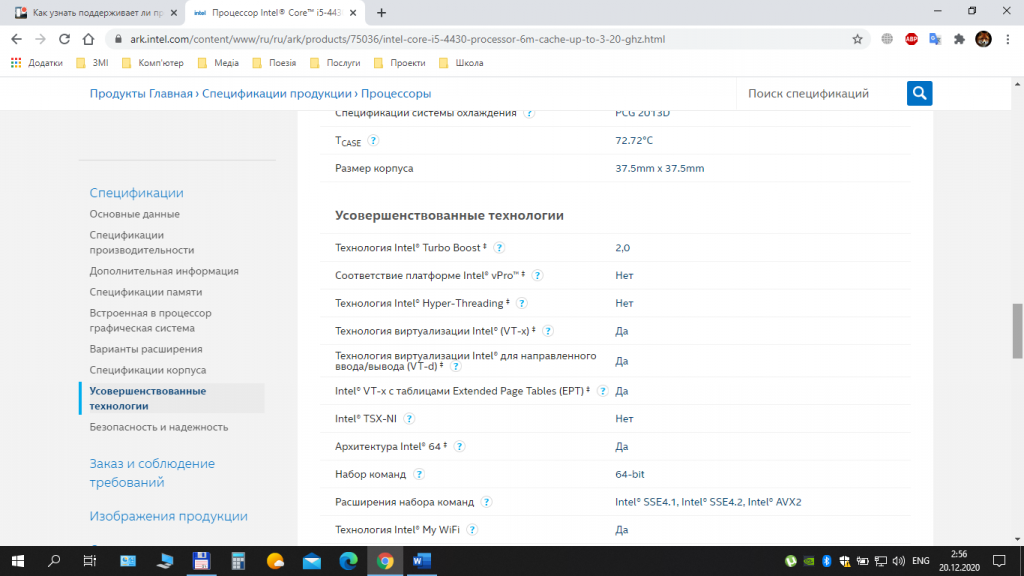
Ещё один способ узнать, есть ли AVX на процессоре, воспользоваться официальным сайтом производителя процессоров. В строке поиска браузера наберите название процессора и выполните поиск. Если у вас процессор Intel, выберите соответствующую страницу в списке и перейдите на неё. На этой странице вам будет предоставлена подробная информация о процессоре.
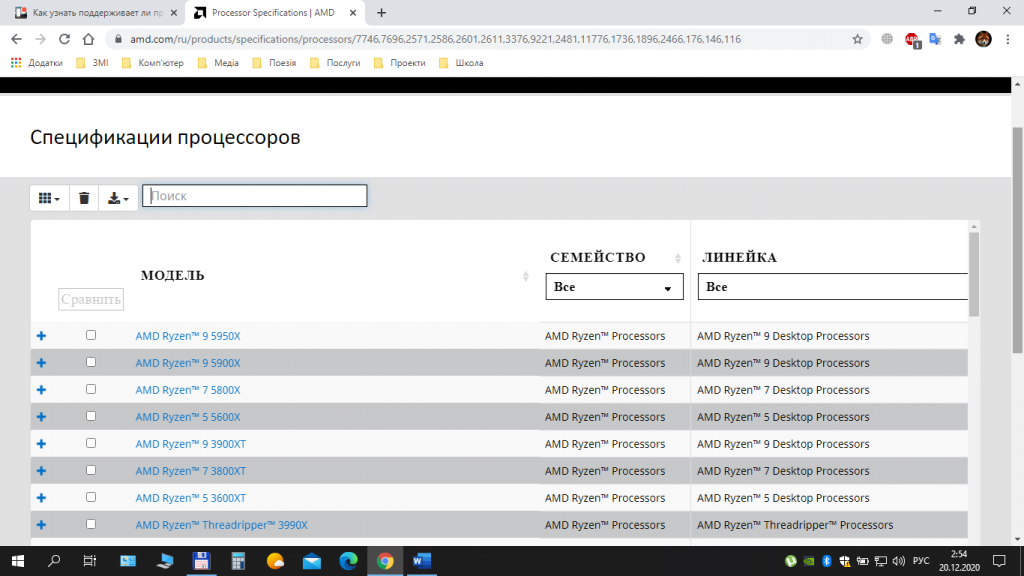
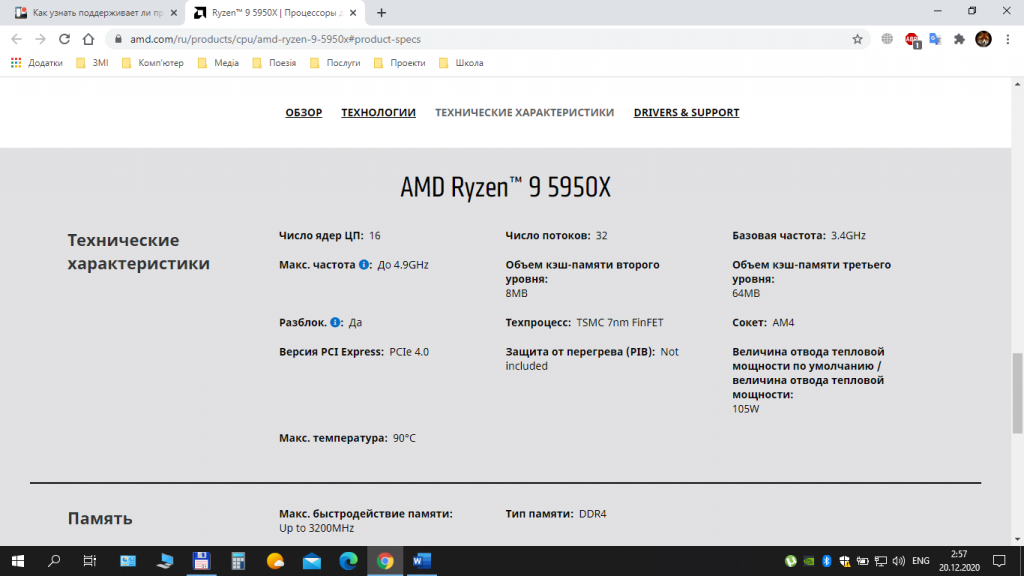
Если у вас процессор от компании AMD, то лучше всего будет воспользоваться сайтом AMD. Выберите пункт меню Процессоры, далее — пункт Характеристики изделия и затем, выбрав тип (например, Потребительские процессоры), выполните переход на страницу Спецификации процессоров. На этой странице выполните поиск вашего процессора по названию и посмотрите подробную информацию о нём.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.
Была ли эта статья полезной?
ДаНет
Оцените статью:
(12 оценок, среднее: 4,67 из 5)
Загрузка…
Об авторе
Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.
Материал из РУВИКИ — свободной энциклопедии
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 15 июля 2021 года; проверки требуют 10 правок.
Advanced Vector Extensions (AVX) — расширение системы команд x86 для микропроцессоров Intel и AMD, предложенное Intel в марте 2008.[1]
AVX предоставляет различные улучшения, новые инструкции и новую схему кодирования машинных кодов.
- Новая схема кодирования инструкций VEX
- Ширина векторных регистров SIMD увеличивается с 128 (XMM) до 256 бит (регистры YMM0 — YMM15). Существующие 128-битные SSE-инструкции будут использовать младшую половину новых YMM-регистров, не изменяя старшую часть. Для работы с YMM-регистрами добавлены новые 256-битные AVX-инструкции. В будущем возможно расширение векторных регистров SIMD до 512 или 1024 бит. Например, процессоры с архитектурой Xeon Phi уже в 2012 году имели векторные регистры (ZMM) шириной в 512 бит[2], и используют для работы с ними SIMD-команды с MVEX- и VEX-префиксами, но при этом они не поддерживают AVX. [источник не указан 3436 дней]
- Неразрушающие операции. Набор AVX-инструкций использует трёхоперандный синтаксис. Например, вместо можно использовать , при этом регистр остаётся неизменённым. В случаях, когда значение используется дальше в вычислениях, это повышает производительность, так как избавляет от необходимости сохранять перед вычислением и восстанавливать после вычисления регистр, содержавший , из другого регистра или памяти.
- Для большинства новых инструкций отсутствуют требования к выравниванию операндов в памяти. Однако рекомендуется следить за выравниванием на размер операнда во избежание значительного снижения производительности.[3]
- Набор инструкций AVX содержит в себе аналоги 128-битных SSE-инструкций для вещественных чисел. При этом, в отличие от оригиналов, сохранение 128-битного результата будет обнулять старшую половину YMM-регистра. 128-битные AVX-инструкции сохраняют прочие преимущества AVX, такие как новая схема кодирования, трехоперандный синтаксис и невыровненный доступ к памяти.
- Intel рекомендует отказаться от старых SSE-инструкций в пользу новых 128-битных AVX-инструкций, даже если достаточно двух операндов.[4].
Новая схема кодирования инструкций VEX использует VEX-префикс. В настоящий момент существуют два VEX-префикса, длиной 2 и 3 байта. Для 2-байтного VEX-префикса первый байт равен 0xC5, для 3-байтного — 0xC4.
В 64-битном режиме первый байт VEX-префикса уникален. В 32-битном режиме возникает конфликт с инструкциями LES и LDS, который разрешается старшим битом второго байта, он имеет значение только в 64-битном режиме, через неподдерживаемые формы инструкций LES и LDS.[3]
Длина существующих AVX-инструкций, вместе с VEX-префиксом, не превышает 11 байт. В следующих версиях ожидается появление более длинных инструкций.
| Инструкция | Описание |
|---|---|
| VBROADCASTSS, VBROADCASTSD, VBROADCASTF128 | Копирует 32-, 64- или 128-битный операнд из памяти во все элементы векторного регистра XMM или YMM. |
| VINSERTF128 | Замещает младшую или старшую половину 256-битного регистра YMM значением 128-битного операнда. Другая часть регистра-получателя не изменяется. |
| VEXTRACTF128 | Извлекает младшую или старшую половину 256-битного регистра YMM и копирует в 128-битный операнд-назначение. |
| VMASKMOVPS, VMASKMOVPD | Условно считывает любое количество элементов из векторного операнда из памяти в регистр-получатель, оставляя остальные элементы несчитанными и обнуляя соответствующие им элементы регистра-получателя. Также может условно записывать любое количество элементов из векторного регистра в векторный операнд в памяти, оставляя остальные элементы операнда памяти неизменёнными. |
| VPERMILPS, VPERMILPD | Переставляет 32- или 64-битные элементы вектора согласно операнду-селектору (из памяти или из регистра). |
| VPERM2F128 | Переставляет 4 128-битных элемента двух 256-битных регистров в 256-битный операнд-назначение с использованием непосредственной константы (imm) в качестве селектора. |
| VZEROALL | Обнуляет все YMM-регистры и помечает их как неиспользуемые. Используется при переключении между 128-битным режимом и 256-битным. |
| VZEROUPPER | Обнуляет старшие половины всех регистров YMM. Используется при переключении между 128-битным режимом и 256-битным. |
Также в спецификации AVX описана группа инструкций PCLMUL (Parallel Carry-Less Multiplication, Parallel CLMUL)
- PCLMULLQLQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 00]
- PCLMULHQLQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 01]
- PCLMULLQHQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 02]
- PCLMULHQHQDQ xmmreg, xmmrm [rm: 66 0f 3a 44 /r 03]
- PCLMULQDQ xmmreg, xmmrm, imm [rmi: 66 0f 3a 44 /r ib]
Подходит для интенсивных вычислений с плавающей точкой в мультимедиа-программах и научных задачах.
Там, где возможна более высокая степень параллелизма, увеличивает производительность с вещественными числами.
- Math Kernel Library[5]
Поддержка в операционных системах[править | править код]
Использование YMM-регистров требует поддержки со стороны операционной системы. Следующие системы поддерживают регистры YMM:
- Linux: с версии ядра 2.6.30,[6] released on June 9, 2009.[7]
- Windows 7: поддержка добавлена в Service Pack 1[8]
- Windows Server 2008 R2: поддержка добавлена в Service Pack 1[8]
- Intel:
- Процессоры с микроархитектурой Sandy Bridge, 2011.[9]
- Процессоры с микроархитектурой Ivy Bridge, 2012.
- Процессоры с микроархитектурой Haswell, 2013.
- Процессоры с микроархитектурой Broadwell, 2015.
- Процессоры с микроархитектурой Skylake, 2015.
- Процессоры с микроархитектурой Kaby Lake, 2017.
- Процессоры с микроархитектурой Coffee Lake, 2017.
- AMD:
- Процессоры с микроархитектурой Bulldozer, 2011.[10]
- Процессоры с микроархитектурой Piledriver, 2012.
- Процессоры с микроархитектурой Steamroller, 2014.
- Процессоры с микроархитектурой Excavator, 2015.
- Процессоры с микроархитектурой Zen, 2017.
- Процессоры с микроархитектурой Zen 2, 2019.
- Процессоры с микроархитектурой Zen 3, 2020.
Совместимость между реализациями Intel и AMD обсуждается в этой статье.
- Intel Haswell[11]
- Intel Broadwell
- Intel Skylake
- Intel Kaby Lake
- Intel Coffee Lake
- Intel Comet Lake
- Intel Rocket Lake
- Intel Alder Lake
- AMD Excavator
- AMD Zen (AMD Ryzen)
- AMD Zen 2 (AMD Ryzen)
- AMD Zen 3 (AMD Ryzen)
AVX-512
[править | править код]
AVX-512 расширяет систему команд AVX до векторов длиной 512 бит при помощи кодировки с префиксом EVEX. Расширение AVX-512 вводит 32 векторных регистра (ZMM), каждый по 512 бит, 8 регистров масок, 512-разрядные упакованные форматы для целых и дробных чисел и операции над ними, тонкое управление режимами округления (позволяет переопределить глобальные настройки), операции broadcast (рассылка информации из одного элемента регистра в другие), подавление ошибок в операциях с дробными числами, операции gather/scatter (сборка и рассылка элементов векторного регистра в/из нескольких адресов памяти), быстрые математические операции, компактное кодирование больших смещений. AVX-512 предлагает совместимость с AVX, в том смысле, что программа может использовать инструкции как AVX, так и AVX-512 без снижения производительности. Регистры AVX (YMM0-YMM15) отображаются на младшие части регистров AVX-512 (ZMM0-ZMM15), по аналогии с SSE и AVX регистрами.[12]
Используeтся в Intel Xeon Phi (ранее Intel MIC) Knights Landing (версия AVX3.1), Intel Skylake-X,[12] Intel Ice Lake, Intel Tiger Lake, Intel Rocket Lake. Также поддержка AVX-512 имеется в производительных ядрах Golden Cove[13] процессоров Intel Alder Lake, однако энергоэффективные ядра Gracemont её лишены. По состоянию на декабрь 2021 г. поддержка AVX-512 для потребительских процессоров Alder Lake официально не заявляется.[14]
Схема кодирования инструкций VEX легко допускает дальнейшее расширение набора инструкций AVX. В следующей версии, AVX2, добавлены инструкции для работы с целыми числами, FMA3 (увеличил производительность при обработке чисел с плавающей запятой в 2 раза[11]), загрузку распределенного в памяти вектора (gather) и прочее.
Различные планируемые дополнения системы команд x86:
- AES
- CLMUL
- Intel/AMD FMA3
- AMD FMA4
- AMD XOP
- AMD CVT16
В серверных процессорах поколения Broadwell добавлены расширения AVX 3.1, а в серверных процессорах поколения Skylake — AVX 3.2.
- ↑ ISA Extensions | Intel® Software. Дата обращения: 24 июня 2016. Архивировано 6 мая 2019 года.
- ↑ Intel® Xeon Phi™ Coprocessor Instruction Set Architecture Reference Manual (недоступная ссылка — история). Архивировано 11 мая 2013 года.
- ↑ 1 2 Introduction to Intel® Advanced Vector Extensions — Intel® Software Network. Дата обращения: 19 июля 2012. Архивировано 16 июня 2012 года.
- ↑ Questions about AVX — Intel® Software Network. Дата обращения: 24 июня 2016. Архивировано 7 августа 2016 года.
- ↑ Intel® AVX optimization in Intel® MKL. Дата обращения: 7 января 2014. Архивировано 7 января 2014 года.
- ↑ x86: add linux kernel support for YMM state (недоступная ссылка — история). Дата обращения: 13 июля 2009. Архивировано 5 апреля 2012 года.
- ↑ Linux 2.6.30 — Linux Kernel Newbies (недоступная ссылка — история). Дата обращения: 13 июля 2009. Архивировано 5 апреля 2012 года.
- ↑ 1 2 Enable Windows 7 Support for Intel AVX (недоступная ссылка — история). Microsoft. Дата обращения: 29 января 2011. Архивировано 5 апреля 2012 года.
- ↑ Intel Offers Peek at Nehalem and Larrabee. ExtremeTech (17 марта 2008). Архивировано из оригинала 7 июня 2011 года.
- ↑ Striking a balance (недоступная ссылка — история). Dave Christie, AMD Developer blogs (7 мая 2009). Дата обращения: 8 мая 2009. Архивировано 5 апреля 2012 года.
- ↑ 1 2 More details on the future AVX instruction set 2.0 | Tech News Pedia. Дата обращения: 14 ноября 2012. Архивировано из оригинала 31 октября 2012 года.
- ↑ 1 2 James Reinders (23 July 2013), AVX-512 Instructions, Intel, <http://software.intel.com/en-us/blogs/2013/avx-512-instructions>. Проверено 20 августа 2013. Архивная копия от 31 марта 2015 на Wayback Machine
- ↑ Dr Ian Cutress, Andrei Frumusanu. Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed. www.anandtech.com. Дата обращения: 23 декабря 2021. Архивировано 4 января 2022 года.
- ↑ Product Specifications (англ.). www.intel.com. Дата обращения: 23 декабря 2021.
- Intel Advanced Vector Extensions Programming Reference (319433-011)(pdf) (англ.)
- Использование Intel AVX: пишем программы завтрашнего дня (рус.)
- Приемы использования масочных регистров в AVX512 коде (рус.)
* In spite of paying attention and showing great sensitivity when providing the information, we can not guarantee 100% accuracy.
* Price and properties of the products must be verified from the sellers/suppliers. Not all sellers or offers might be shown in the price lists.
* Epey.co.uk cannot be held accountable for any damage or loss due to missings or errors occured
* This website may earn commissions when referring visitors to partner sites. As Epey, we comply with the guidelines of regulatory agencies requiring us to disclose such material connections when promoting products and services.
* PassMark puanı zamanla değişiklik gösterebilir. Bunun sebebi, bu yazılımı kullanan kişi sayısındaki artış ve farklı sistemlerden elde edilen sonuçların çeşitlenmesidir. Puan, genel ortalamaya göre belirlenir ve test sayısı arttıkça puanda dalgalanmalar meydana gelebilir.
Copyright © 2025 All Rights Reserved.