Материал из РУВИКИ — свободной энциклопедии
Перейти к материалам ОГЭ/ЕГЭ

РУВИКИ для ОГЭ/ЕГЭ
Переходите на портал РУВИКИ, где собраны материалы для подготовки к ОГЭ и ЕГЭ
Перейти
Перейти к материалам ОГЭ/ЕГЭ
РУВИКИ для ОГЭ/ЕГЭ
Переходите на портал РУВИКИ, где собраны материалы для подготовки к ОГЭ и ЕГЭ
Эта статья о системе команд в целом; об инструкциях см. Код операции.
| Выполнение программы |
|---|
| Общие понятия |
|
| Типы кода |
|
| Стратегии компиляции |
|
| Основные среды выполнения |
|
| Основные компиляторы и наборы инструментов для сборки |
|
Памятка программиста, 1960-е годы. Цифровой (машинный) код «Минск-22»
Маши́нный код (платфо́рменно-ориенти́рованный код), маши́нный язы́к — система команд (набор кодов операций) конкретной вычислительной машины, которая интерпретируется непосредственно процессором или микропрограммами этой вычислительной машины.[1]
Компьютерная программа, записанная на машинном языке, состоит из машинных инструкций, каждая из которых представлена в машинном коде в виде т. н. опкода — двоичного кода отдельной операции из системы команд машины. Для удобства программирования вместо числовых опкодов, которые только и понимает процессор, обычно используют их условные буквенные мнемоники. Набор таких мнемоник, вместе с некоторыми дополнительными возможностями (например, некоторыми макрокомандами, директивами), называется языком ассемблера.
Каждая модель процессора имеет собственный набор команд, хотя во многих моделях эти наборы команд сильно перекрываются. Говорят, что процессор A совместим с процессором B, если процессор A полностью «понимает» машинный код процессора B. Если процессоры A и B имеют некоторое подмножество инструкций, по которым они взаимно совместимы, то говорят, что они одной «архитектуры» (имеют одинаковую архитектуру набора команд).
Каждая машинная инструкция выполняет определённое действие, такое как операция с данными (например, сложение или копирование машинного слова в регистре или в памяти) или переход к другому участку кода (изменение порядка исполнения; при этом переход может быть безусловным или условным, зависящим от результатов предыдущих инструкций). Любая исполнимая программа состоит из последовательности таких атомарных машинных операций.
Операции, записываемые в виде одной машинной инструкции, можно разделить на «простые» (элементарные операции) и «сложные». Кроме того, большинство современных процессоров состоит из отдельных «исполнительных устройств» — вычислительных блоков, которые умеют исполнять лишь ограниченный набор простейших операций. При исполнении очередной инструкции специальный блок процессора — декодер — транслирует (декодирует) её в последовательность элементарных операций, понимаемых конкретными исполнительными устройствами.
Архитектура набора команд процессора определяет, какие операции он способен выполнять, и какой машинной инструкции какие числовые коды операций (опкоды) соответствуют. Опкоды бывают постоянной длины (у RISC-, MISC-архитектур) и диапазонной (у CISC-архитектур; например: для архитектуры x86 команда имеет длину от 8 до 120 битов).
Современные суперскалярные процессоры способны выполнять несколько машинных инструкций за один такт.
Машинный код можно рассматривать как примитивный язык программирования или как самый низкий уровень представления скомпилированных или ассемблированных компьютерных программ. Хотя вполне возможно создавать программы прямо в машинном коде, сейчас это делается редко в силу громоздкости кода и трудоёмкости ручного управления ресурсами процессора, за исключением ситуаций, когда требуется экстремальная оптимизация. Поэтому подавляющее большинство программ пишется на языках более высокого уровня и транслируется в машинный код компиляторами. Машинный код иногда называют нативным кодом (также собственным или родным кодом — от англ. native code), когда говорят о платформенно-зависимых частях языка или библиотек.[2]
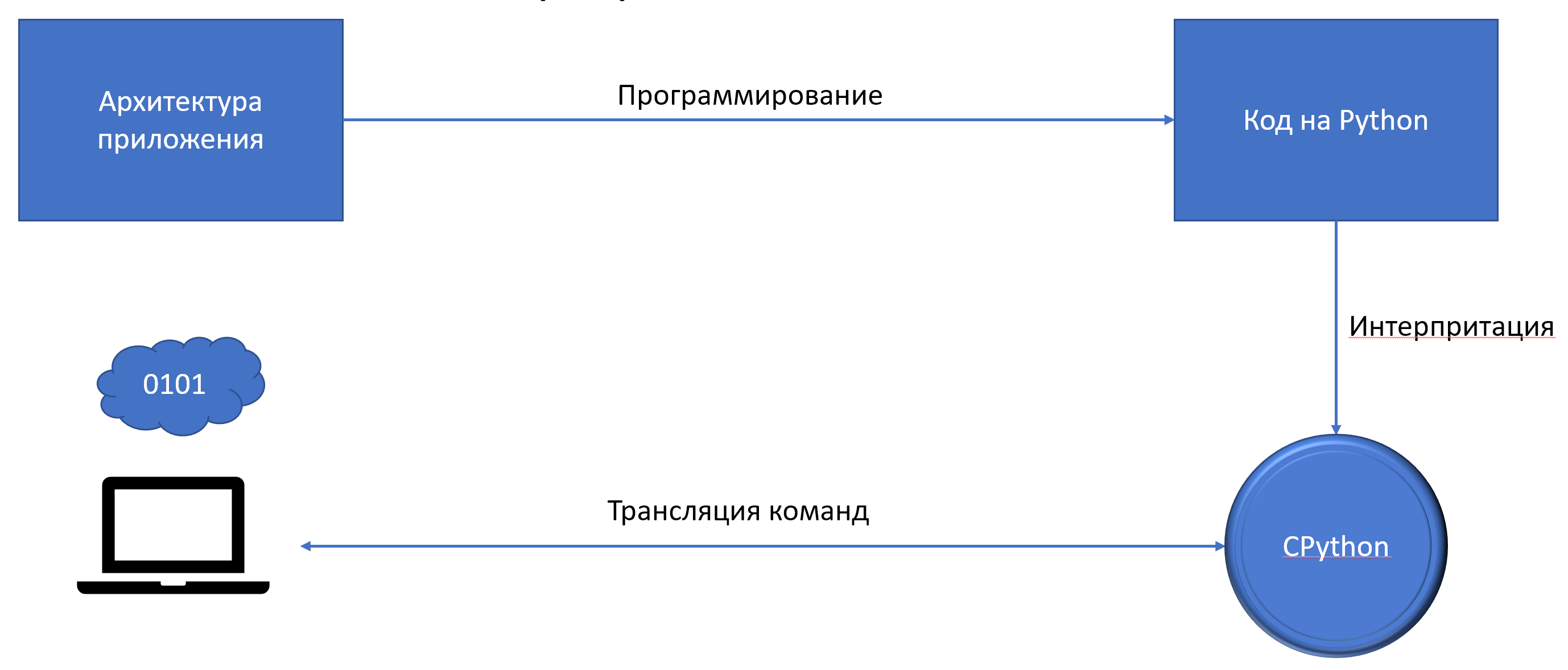
Программы на интерпретируемых языках (таких как Basic или Python) не транслируются в машинный код; вместо этого они либо исполняются непосредственно интерпретатором языка, либо транслируются в псевдокод (байт-код). Однако интерпретаторы этих языков (которые сами можно рассматривать как процессоры), как правило, представлены в машинном коде.
В некоторых компьютерных архитектурах поддержка машинного кода реализуется ещё более низкоуровневым слоем программ, называемых микропрограммами. Это позволяет обеспечить единый интерфейс машинного языка у всей линейки или семейства компьютеров, которые могут иметь значительные структурные отличия между собой, и облегчает перенос программ в машинном коде между разными моделями компьютеров. Примером такого подхода является семейство компьютеров IBM System/360 и их преемников: несмотря на разные шины шириной от 8 до 64 бит и выше, тем не менее, у них общая архитектура на уровне машинного языка.
Использование слоя микрокода для реализации эмулятора позволяет компьютеру представлять архитектуру совершенно другого компьютера. В линейке System/360 это использовалось для переноса программ с более ранних машин IBM на новое семейство — например, эмулятор IBM 1401/1440/1460 на IBM S/360 model 40.
Абсолютный код (англ. absolute code) — программный код, пригодный для прямого выполнения процессором[1], то есть код, не требующий дополнительной обработки (например, разрешения ссылок между различными частями кода или привязки к адресам в памяти, обычно выполняемой загрузчиком программ). Примерами абсолютного кода являются исполнимые файлы в формате .COM и загрузчик ОС, располагаемый в MBR. Часто абсолютный код понимается в более узком смысле как позиционно-зависимый код (то есть код, привязанный к определённым адресам памяти).
Позиционно-независимый код (англ. position-independent code) — программа, которая может быть размещена в любой области памяти, так как все ссылки на ячейки памяти в ней относительные (например, относительно счётчика команд). Такую программу можно переместить в другую область памяти в любой момент, в отличие от перемещаемой программы, которая хотя и может быть загружена в любую область памяти, но после загрузки должна оставаться на том же месте.[1]
Возможность создания позиционно-независимого кода зависит от архитектуры и системы команд целевой платформы. Например, если во всех инструкциях перехода в системе команд должны указываться абсолютные адреса, то код, требующий переходов, практически невозможно сделать позиционно-независимым. В архитектуре x86 непосредственная адресация в инструкциях работы с данными представлена только абсолютными адресами, но поскольку адреса данных считаются относительно сегментного регистра, который можно поменять в любой момент, это позволяет создавать позиционно-независимый код со своими ячейками памяти для данных. Кроме того, некоторые ограничения набора команд могут сниматься с помощью самомодифицирующегося кода или нетривиальных последовательностей инструкций.
Программа «Hello, world!» для процессора архитектуры x86 (ОС MS DOS, вывод при помощи BIOS прерывания int 10h) выглядит следующим образом (в шестнадцатеричном представлении):
- BB 11 01 B9 0D 00 B4 0E 8A 07 43 CD 10 E2 F9 CD 20 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21
Данная программа работает при её размещении по смещению 10016. Отдельные инструкции выделены цветом:
- BB 11 01, B9 0D 00, B4 0E, 8A 07 — команды присвоения значений регистрам.
- 43 — инкремент регистра BX.
- CD 10, CD 20 — вызов программных прерываний 1016 и 2016.
- E2 F9 — команда для организации цикла.
- Малиновым показаны данные (строка «Hello, world!»).
Тот же код ассемблерными командами:
XXXX:0100 mov bx, 0111h ; поместить в bx смещение строки HW XXXX:0103 mov cx, 000Dh ; поместить в cx длину строки HW XXXX:0106 mov ah, 0Eh ; поместить в ah номер функции прерывания 10h XXXX:0108 mov al, [bx] ; поместить в al значение ячейки памяти, адрес которой находится в bx XXXX:010A inc bx ; перейти к следующему байту строки (увеличить смещение на 1) XXXX:010B int 10h ; вызов прерывания 10h XXXX:010D loop 0108 ; уменьшить cx на 1 и, если результат≠0, то перейти по адресу 0108 XXXX:010F int 20h ; прерывание 20h: завершить программу XXXX:0111 HW db 'Hello, World!' ; строка, которую требуется напечатать
- Язык ассемблера
- JIT-компиляция
- ↑ 1 2 3 Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп.) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания).
- ↑ Kate Gregory. Managed, Unmanaged, Native: What Kind of Code Is This? (28 апреля 2003). Дата обращения: 27 марта 2012. Архивировано 30 мая 2012 года.
Machine instructions are machine code programs or commands. In other words, commands written in the machine code of a computer that it can recognize and subsequently execute.
Machine code or machine language refers to a computer programming language consisting of a string of ones and zeros, i.e., binary code. Computers can respond to machine code directly, i.e., without any direction or conversion.
Machine instructions make up the machine language program
One machine instruction consists of several bytes of memory. It tells the computer’s CPU to perform one machine operation. CPU stands for Central Processing Unit.
The CPU looks at machine instructions in the system’s main memory, one after another. For each machine instruction, it performs one machine operation.
The machine language program is the collection of all machine instructions in the main memory.
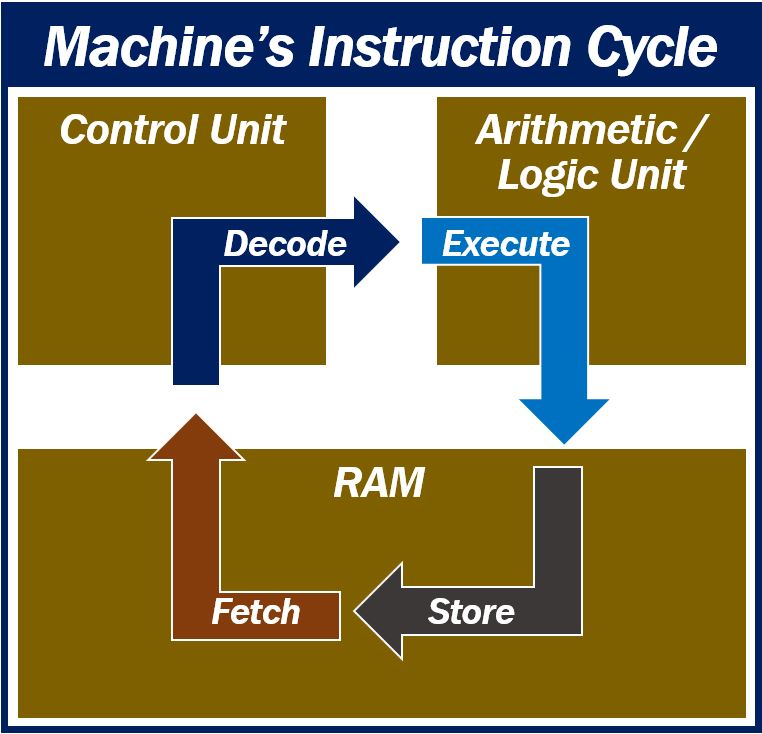
Machine instructions – four main steps
There are four main steps in the machine instruction cycle:
– Fetch: the processor fetches the instruction from the memory address. It stores the address in the PC (Program Counter) and IR (Instruction Register). The PC points to the next instruction at the end of the fetch operation.
– Decode: the processor interprets and decodes the instruction. The instruction within the IR gets decoded.
– Execute: the CPU’s Control Unit decodes the data as a sequence of control signals to the CPU’s relevant function units. These units perform the actions that the instruction ‘instructs.’
– Store: the operation generates a result, which the processor stores in the main memory. Sometimes, it may send it to an output device.
Converting human instructions into machine instructions
Human programmers do not write programs as long strings of ones and zeros or sequences of binary digits. They use Python, BASIX, Ruby, Java, C++, or another programming language. We call these high-level programming languages.
High-level languages are more like the everyday written language that humans use, rather than binary number sequences. But computers don’t understand them.
Before a computer’s processor can execute the instructions in high-level languages, they must be translated into a binary code.
In the world of computer programming, there are two languages:
– Human-readable language. In this case, humans can read and understand them, but machines cannot.
– Machine-readable language. These appear as long strings of ones and zeros and tell the computer’s processor what to do. Humans cannot read the language, only machines (computers) can.
Compilers and interpreters
Most programming software has a piece of translating software that converts high-level languages into machine instructions. We call these translators compilers and interpreters. Compilers or interpreters translate the language.
A compiler translates a human-readable program into a machine-readable form before the program can run.
An interpreter translates a human-readable program, instruction by instruction, into an executive, machine-readable form. Then, it executes each instruction that it has translated before it moves onto the next one. Every time the program runs, it is translated.
Время на прочтение9 мин
Количество просмотров16K
Вторая часть перевода D Programming Language Tutorial от Ali Çehreli. Большая часть материала ориентирована на начинающих, но так как большая часть аудитории уже имеет базовые знания в программировании, то этот материал убран под хабракаты. В данной части рассматриваются фундаментальные типы, свойства типов, основы компиляции и императивного программирования.
Другие части:
- Часть 1
- Часть 2
- Часть 3
Базовый материал
Компилятор
Ранее мы увидели, что наиболее часто используемые инструменты в D — текстовый редактор и компилятор. Программы на D пишутся в текстовых редакторах (прим. ваш КО).
При использовании компилируемых языков, таких как D, необходимо понимать концепцию компиляции и функцию компилятора.
Машинные коды
Мозгом компьютера является микропроцессор (или ЦПУ, сокращение от центрального процессорного устройства). Кодированием называется указывание, что именно должен делать ЦПУ, и инструкции, которые используются при этом, называются машинными кодами.
Большинство архитектур ЦПУ используют специфичные для них машинные коды. Эти машинные инструкции определяются с учетом ограничений аппаратных средств во время проектирования архитектуры. На самом низком уровне эти инструкции реализованы как электические сигналы. Так как простота программирования на этом уровне не является главной целью, написание программ напрямую в машиннах кодах ЦПУ является очень сложной задачей.
Эти машинные инструкции представляют собой специальные числа, которые представляют различные операции, поддерживаемые конкретным ЦПУ. Например, для воображаемого 8-битного ЦПУ, число 4 может представлять операцию загрузки, число 5 — операцию сохранения, и число 6 — операцию увеличения значения на единицу. Предполагая, что первые 3 бита слева — номер операции и 5 последующих бита — значение, которое используется в этой операции, программа-пример в машинных кодах этого ЦПУ может выглядеть следующим образом:
Operation Value Meaning
100 11110 LOAD 11110
101 10100 STORE 10100
110 10100 INCREMENT 10100
000 00000 PAUSE
Находясь настолько близко к железу, машинные коды не подходят для представления высокоуровневых понятий таких как: игральная карта или запись о студенте.
Языки программирования
Языки программирования разработаны быть эффективным способом программирования ЦПУ с возможностью представления высокоуровневых концепций. Языкам программирования не приходится иметь дело с ограничениями аппаратуры; их главная задача — простота использования и выразительность. Языки программирования легче понимаются людьми, они ближе к естественным языкам:
if (a_card_has_been_played()) {
display_the_card();
}
Однако языки программирования придерживаются гораздо более строгих и формальных правил, чем любой язык, на котором говорят.
Компилируемые языки
В некоторых языках программирования инструкции должны быть скомпилированы прежде, чем стать исполняемой программой. Такие языки создают быстро выполняющиеся программы, но процесс разработки включает в себя два основных шага: написание программы и ее компиляцию.
В общем случае компилируемые языки помогают в обнаружении ошибок даже до того, как программа начинает выполняться.
D — компилируемый язык.
Интерпретируемые языки
Некоторые языки программирования не требует компиляции. Такие языки называются интерпретируемыми. Программа может запущена прямо из свеженапечатанного исходного кода. Некоторые примеры интерпретируемых языков: Python, Ruby и Perl. Так как этап компиляции отсутствует, для таких языков разработка программы может быть проще. С другой стороны, так как инструкции программы должны быть разобраны для интерпретации каждый раз, когда программа запускается, программа на таких языках медленнее, чем их эквиваленты, написанные на компилируемых языках.
В общем случае для интерпретируемых языков, многие типы ошибок в программе не могут быть обнаружены до момента начала выполнения.
Компилятор
Назначение компилятора — трансляция: он транслирует программы, написанные на языке программирования, в машинный код. Это перевод из языка программиста на язык ЦПУ. Такая трансляция называется компиляцией. Каждый компилятор понимает какой-то конкретный язык программирования и описывается, как компилятор для этого языка, например «компилятор для D».
Ошибки компиляции
Так как компилятор компилирует программу согласно правилам языка, он останавливает компиляцию как только достигает некорректных инструкций. Некорректные инструкции — те, которые выбиваются из спецификаций языка. Проблемы, такие как: несоответсвующие скобки, отсутствующая точка с запятой, ключевое слово с опечаткой и т.д. — все вызывают ошибки компиляции.
Также компилятор генерирует предупреждения компиляции, когда он видит подозрительный кусок кода, который может вызывать беспокойство, но не обязательно является ошибкой. Однако, предупреждения практически всегда указывают на настоящую ошибку или плохой стиль, поэтому самая распространенная практика — рассматривать большинство или все предупреждения как ошибки.
Фундаментальные типы
Ранее мы выяснили, что мозгом компьютера является ЦПУ. Большинство задач программы выполняются на ЦПУ, и остальные распределены по другим частям компьютера.
Наименьшая единица данных в компьтере называется битом, которая может принимать значения 0 или 1.
Так как тип данных, который может содержать только значения 0 или 1 имел бы очень ограниченное применение, ЦПУ определяет бОльшие типы данных, которые являются комбинациями из более одного бита. Например, байт содержит 8 битов. Наиболее производительный тип данных определяет битность ЦПУ: 32-битный ЦПУ, 64-битный ЦПУ и т.п.
Типов, определенных ЦПУ, все еще недостаточно: они не могут описать высокоуровневые понятия, как имя студента или игральная карта. D предоставляет множество полезных типов данных, но даже этих типов не хватает для описания многих высокоуровневых концепций. Такие концепции должны быть определены программистом как структуры (struct) или классы (class), которые мы увидим в следующих главах.
Фундаментальные типы D очень похожи на фундаментальные типы многих других языков, как показано в следующей таблице. Термины, появляющиеся в этой таблице, объяснены ниже:
| Тип | Определение | Начальное значение |
|---|---|---|
| bool | Логическое значение Истина/Ложь | false |
| byte | 8 битное число со знаком | 0 |
| ubyte | 8 битное число без знака | 0 |
| short | 16 битное число со знаком | 0 |
| ushort | 16 битное число без знака | 0 |
| int | 32 битное число соз знаком | 0 |
| uint | 32 битное число без знака | 0 |
| long | 64 битное число со знаком | 0 |
| ulong | 64 битное число без знака | 0 |
| float | 32 битное действительное число с плавающей точкой | float.nan |
| double | 64 битное действительное число с плавающей точкой | double.nan |
| real | наибольшое число с плавающей точкой, которое поддерживается оборудованием | real.nan |
| ifloat | мнимая часть комплексного числа для float | float.nan * 1.0i |
| idouble | мнимая часть комплексного числа для double | double.nan * 1.0i |
| ireal | мнимая часть комплексного числа для real | real.nan * 1.0i |
| cfloat | комплексный вариант float | float.nan + float.nan * 1.0i |
| cdouble | комплексный вариант double | double.nan + double.nan * 1.0i |
| creal | комплексный вариант real | real.nan + real.nan * 1.0i |
| char | символ UTF-8 (code point) | 0xFF |
| wchar | символ UTF-16 (code point) | 0xFFFF |
| dchar | символ UTF-32 (code point) | 0x0000FFFF |
В довесок к вышеперечисленным, ключевое слово void описывает сущности не имеющие типа. Ключевые слова cent и ucent зарезервированы для будущего использования для представления знаковых и безнаковых 128-битных значений.
Вы можете использовать int для большинства значений, до тех пор пока нет особых причин не делать это. Рассмотрите double для представления понятий, которые имеют дробную часть.
Разъяснения понятий, представленных в таблице
Логическое значение: тип логического выражения, имеющий значения true для истины и false для лжи.
Тип со знаком: Тип, который может принимать отрицательные и положительные значения. Например, byte может иметь значения от 0 до 255. Буква u в начале названия этих типов взята от слова unsigned.
Число с плавающей точкой: Тип может представлять значения с десятичной дробной частью, как у 1.25. Точность вычислений с плавающей точкой напрямую зависит от числа битов в типе: больше число битов, получаем более точные результаты.
Только числа с плавающей точкой могут представлять десятичные дроби; целочисленные типы (например, int) могут держать только такие значения, как 1 и 2.
Комлексные типы чисел: Эти типы могут представлять комплексные числа из математики.
Мнимые типы чисел: Эти типы могут представлять только мнимую часть комплексных чисел. Буква i, которая находится в колонке начальных значений, в математике является квадратным корнем из -1.
nan: Сокращение от «not a number», представляющее некорректное значение с плавающей точкой.
Комментарии переводчика
Может показаться странным, что для чисел с плавающей точкой используются NaN значения как инициализаторы. Оффициальное объяснение от разработчиков (хотя я не согласен с этой позицией):
NaN’ы обладают интересным свойством, что в какой бы операции они не использовались, то в результате получается снова NaN. Поэтому NaN будет распространяться и будет результатом любых вычислений, где он был использован. Это означает, что внезапно появляющийся NaN является недвусмысленным индикатором того, что была использована непроиницилизированная переменная.
Если бы 0.0 использовался как начальное значение, его последствия легко было бы не заметить на выходе, поэтому если инициализация по умолчанию была непреднамеренная, баг мог бы остаться незамеченным.
Не подразумевается, что инициализатор по умолчанию должен быть полезным значением, его цель — вскрытие багов. NaN хорошо подходит под эту роль.
Но, конечно, компилятор может обнаружить и сгенерировать ошибку о переменных, которые не были проинициализированы? В большинстве случаев он может, но не всегда, и то, что он может, зависит от сложности внутреннего анализа потоков данных. Поэтому надежда на этот механизм — непереносимое и ненадежное решение.
Из-за особенностей реализации ЦПУ, NaN отсутствует для целочисленных, поэтому вместо этого D использует 0. Нулевое значение не имеет таких преимуществ для обнаружения ошибок, какими обладает NaN, но, по крайней мере, ошибки от непреднамеренной инициализации будут повторимы и поэтому более отлаживаемыми.
Свойства типов
В D у типов есть свойства. Чтобы получить значение свойства, нужно написать имя свойства после типа через точку. Например, sizeof свойство int вызывается так: int.sizeof. В этой главе рассматриваются только следующие четыре атрибута:
- stringof: имя типа
- sizeof: размер типа в байтах (для кол-ва битов умножьте на

- min: минимальное значение, которое может принимать тип
- max: максимальное значение, которое может принимать тип

Программа, которая печатает эти свойства для int
import std.stdio;void main()
{
writeln(«Тип : «, int.stringof);
writeln(«Длина в байтах : «, int.sizeof);
writeln(«Минимальное значение : «, int.min);
writeln(«Максимальное значение: «, int.max);
}
Примечания переводчика
Некоторые типы имеют другие свойства, например float и double не имеют свойства min, вместо него используется -float.max и —double.max, подробнее.
size_t
Вы также встретитесь с типом size_t, имя которого расшифровывается как «size type». Он не является самостоятельным типом, а псевдонимом безнакового типа, которого хватит для представления всех возможных адресов в памяти. Поэтому этот тип зависит от системы: uint на 32-х битных, ulong для 64-х битных системах и т.д.
Можно использовать свойство .stringof, чтобы увидеть на какой тип ссылается size_t на вашей системе:
Код
import std.stdio;void main()
{
writeln(size_t.stringof);
}
Вывод на моей системе:
ulong
Упражнения
Распечатайте свойства других типов.
Примечание:Нельзя использовать зарезервированные типы cent и ucent в любой программе; как исключение, void не имеет свойств .min и .max.
Решение
import std.stdio;void main()
{
writeln(«Тип : «, short.stringof);
writeln(«Размер в байтах : «, short.sizeof);
writeln(«Минимальное значение : «, short.min);
writeln(«Максимальное занчение: «, short.max);
writeln();
writeln(«Тип : «, ulong.stringof);
writeln(«Размер в байтах : «, ulong.sizeof);
writeln(«Минимальное значение : «, ulong.min);
writeln(«Максимальное занчение: «, ulong.max);
}
Базовый материал
Оператор присваивания и порядок вычислений
Первые два камня преткновения, которые ждут изучающих программирование, это — оператор присваивания и порядок вычислений.
Оператор присваивания
Вы будете встречать подобные строчки практически во всех программах, практически во всех языках программирования:
a = 10;
Значение этой строчки — «сделай значение a равным 10». Аналогично следующая строчка обозначает «сделай значение b равным 20»:
b = 20;
На основе вышеизложенной информации что можно сказать о следущей строчке?
a = b;
К сожалению, эта строчка не содержит оператор сравнения из математики, который, я предполагаю, все знают. Выражение выше не означает «a равно b»! Когда мы используем ту же логику, что и в предыдущих двух строчках, выражение выше должно означать «сделай значение a равным значению b».
Хорошо известный символ = в математике имеет совершенно другой смысл в программировании: «сделать значение слева равным значению с правой стороны».
Порядок вычислений
Операции программы выполняются шаг за шагом в определенном порядке. Предыдущие три выражения в программе можно увидеть в следующем порядке:
a = 10;
b = 20;
a = b;
Смысл этих строк вместе: «сделай значение a равным 10, затем сделай значение b равным 20, затем сделай значение a равным значению b». Соответственно, после выполнения этих трех операций оба значения a и b будут равны 20.
Упражнение
Изучите, как следующие три операции меняют местами значения a и b. Если в начале их значения были равны 1 и 2 соответственно, то после выполнения операций значения становятся равны 2 и 1:
c = a;
a = b;
b = c;
Решение
Значения a, b и c напечатаны справой стороны каждой операции:
в начале → a 1, b 2, c неважно
c = a → a 1, b 2, c 1
a = b → a 2, b 2, c 1
b = c → a 2, b 1, c 1
В конце значения a и b меняются местами.
1.1. Введение в программирование
Машинный язык
Процессор компьютера не способен понимать напрямую языки программирования, такие как C++, С#, Java, Kotlin, Python и т.д. Очень ограниченный набор инструкций, которые изначально понимает процессор, называется машинным кодом (или «машинным языком»). То, как эти инструкции организованы, выходит за рамки данного введения, но стоит отметить две вещи.
Во-первых, каждая команда (инструкция) состоит только из определенной последовательности (набора) цифр: 0 и 1. Эти числа называются битами или двоичным кодом.
Например, одна команда машинного кода архитектуры ×86 выглядит следующим образом:
10110000 01100001
Во-вторых, каждый набор бит переводится процессором в инструкции для выполнения определенного задания (например, сравнить два числа или переместить число в определенную ячейку памяти). Разные типы процессоров обычно имеют разные наборы инструкций, поэтому инструкции, которые будут работать на процессорах Intel (используются в персональных компьютерах), с большей долей вероятности, не будут работать на процессорах Xenon (используются в игровых приставках Xbox). Раньше, когда компьютеры только начинали массово распространяться, программисты должны были писать программы непосредственно на машинном языке, что было очень неудобно, сложно и занимало намного больше времени, чем сейчас.
Язык ассемблера
Так как программировать на машинном языке — удовольствие специфическое, то программисты изобрели язык ассемблера. В этом языке каждая команда идентифицируется коротким именем (а не набором единиц с нулями), и переменными можно управлять через их имена. Таким образом, писать/читать код стало гораздо легче. Тем не менее, процессор все равно не понимает язык ассемблера напрямую. Его также нужно переводить, с помощью ассемблера, в машинный код. Ассемблер — это транслятор (переводчик), который переводит код, написанный на языке ассемблера, в машинный язык.
Преимуществом Ассемблера является его производительность (точнее скорость выполнения) и он до сих пор используется, когда это имеет решающее значение. Тем не менее, причина подобного преимущества заключается в том, что программирование на этом языке адаптируется к конкретному процессору. Программы, адаптированные под один процессор, не будут работать с другим. Кроме того, чтобы программировать на Ассемблере, по-прежнему нужно знать очень много не очень читабельных инструкций для выполнения даже простого задания.
Например, вот вышеприведенная команда, но уже на языке ассемблера:
mov al, 061h
Высокоуровневые языки программирования
Для решения проблем читабельности кода и чрезмерной сложности были разработаны высокоуровневые языки программирования. C, C++, Pascal, Java, JavaScript и Perl — это всё языки высокого уровня. Они позволяют писать и выполнять программы, не переживая о совместимости кода с разными архитектурами процессоров. Программы, написанные на языках высокого уровня, также должны быть переведены в машинный код перед выполнением. Есть два варианта:
- компиляция, которая выполняется компилятором;
- интерпретация, которая выполняется интерпретатором.
Компилятор — это программа, которая читает код и создает автономную (способную работать независимо от другого аппаратного или программного обеспечения) исполняемую программу, которую процессор понимает напрямую. При запуске программы весь код компилируется целиком, а затем создается исполняемый файл и уже при повторном запуске программы компиляция не выполняется.
Проще говоря, процесс компиляции и сполнения программ выглядит следующим образом:
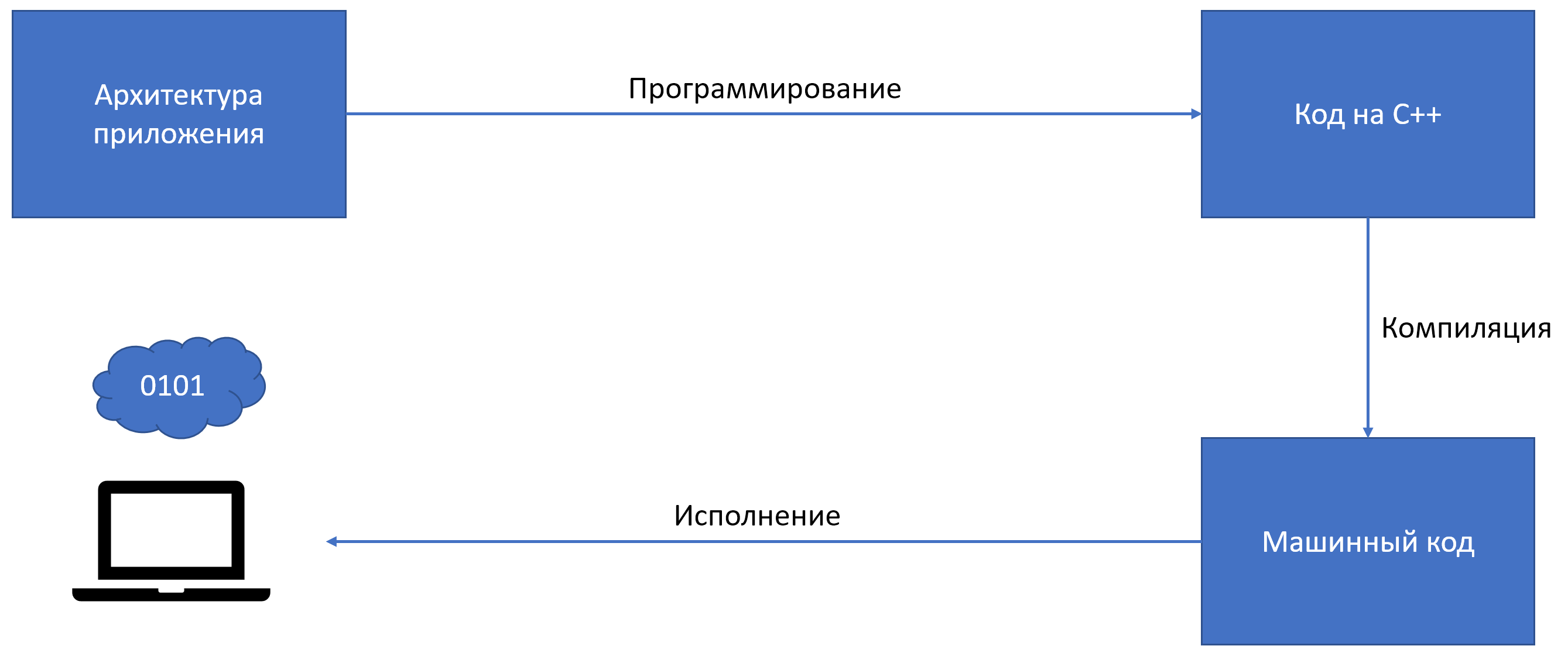
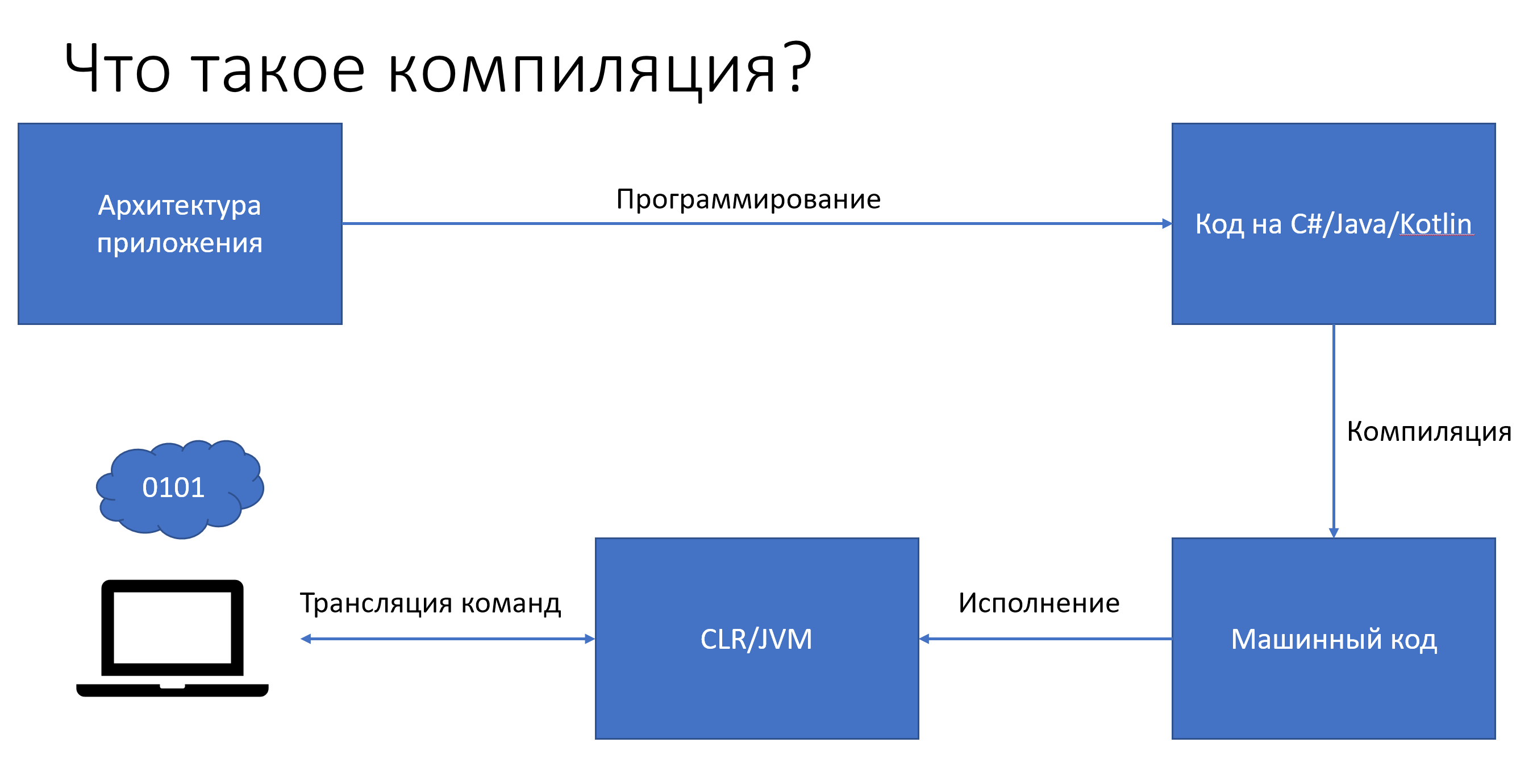
На языках C#/Java/Kotlin в данный процесс добавляется еще один компонент в виде виртуальной машины (для C# — CLR, Java/Kotlin — JVM), целью которой является исполнением байт-кода. Таким образом программа может быть выполненена независимо от платформы, в отличии от программ на C++. Достаточно, чтобы на этой платформе была виртуальная машина для соответствуюещго компиялтора языка.
Интерпретатор — это программа, которая напрямую выполняет код, без его предыдущей компиляции в исполняемый файл. Интерпретаторы более гибкие, но менее эффективные, так как процесс интерпретации выполняется повторно при каждом запуске программы.
Процесс интерпретации:
Любой язык программирования может быть компилируемым или интерпретируемым, однако, такие языки, как C, C++ и Pascal — компилируются, в то время как «скриптовые» языки, такие, как Perl и JavaScript — интерпретируются. Некоторые языки программирования (например, Python) могут как компилироваться, так и интерпретироваться.
Плюсы компилируемости в машинный код
- эффективность: программа компилируется и оптимизируется для конкретного процессора
- нет необходимости устанавливать сторонние приложения (такие как интерпретатор или виртуальная машина)
Минусы компилируемости в машинный код
- нужно компилировать для каждой платформы
- сложность внесения изменения в программу — нужно перекомпилировать заново
Преимущества высокоуровневых языков программирования
- Легче писать/читать код. Вот вышеприведенная команда, но уже на языке C++:
а = 97; - Требуется меньше инструкций для выполнения определенного задания. В языке C++ вы можете сделать что-то вроде
а = Ь * 2 + 5; в одной строке. В языке ассемблера вам пришлось бы использовать 5 или 6 инструкций. - Вы не должны заботиться о таких деталях, как загрузка переменных в регистры процессора. Компилятор или интерпретатор берёт это на себя.
- Высокоуровневые языки программирования более портативные под различные архитектуры.
Машинная инструкция
- Машинная инструкция
-
- Эта статья о системе команд в целом; об инструкциях см.: Код операции (информатика).
Машинный код (также употребляются термины собственный код, или платформенно-ориентированный код, или родной код, или нативный код — от англ. native code) — система команд (язык) конкретной вычислительной машины (машинный язык), который интерпретируется непосредственно микропроцессором или микропрограммами данной вычислительной машины.
Каждая модель процессора имеет свой собственный машинный язык, хотя во многих моделях эти наборы команд сильно перекрываются. Говорят, что процессор A совместим с процессором B, если процессор A полностью «понимает» машинный код процессора B. Если процессор A знает несколько команд, которых не понимает процессор B, то B несовместим с A.
«Слова» машинного языка называются машинными инструкциями. Каждая из них описывает элементарное действие, выполняемое процессором, такое как «переслать байт из памяти в регистр». Программа — это просто длинный список инструкций, выполняемых процессором. Раньше процессоры просто выполняли инструкции одну за другой, но новые суперскалярные процессоры способны выполнять несколько инструкций за раз. Прямой поток выполнения команд может быть изменён инструкцией перехода, которая переносит выполнение на инструкцию с заданным адресом. Инструкция перехода может быть условной, выполняющей переход только при соблюдении некоторого условия.
Также инструкции бывают постоянной длины (у MISC-архитектур) и диапазонной (у x86 команда имеет длину от 8 до 120 битов).
См также
- Язык ассемблера
- Система команд
Wikimedia Foundation.
2010.
Полезное
Смотреть что такое «Машинная инструкция» в других словарях:
-
Инструкция (информатика) — У этого термина существуют и другие значения, см. Инструкция. В информатике термин инструкция обозначает одну отдельную операцию процессора, определённую системой команд. В более широком понимании, «инструкцией» может быть любое представление… … Википедия
-
Микрокод — В этой статье не хватает ссылок на источники информации. Информация должна быть проверяема, иначе она может быть поставлена под сомнение и удалена. Вы можете … Википедия
-
NOP — У этого термина существуют и другие значения, см. NOP (значения). В информатике NOP или NOOP (сокращение от английского: «No OPeration») инструкция процессора на языке ассемблера, или команда протокола, которая предписывает ничего не делать. NOP… … Википедия
-
Ассемблер — Эта статья о компьютерных программах. О языке программирования см. Язык ассемблера. Ассемблер (от англ. assembler сборщик) компьютерная программа, компилятор исходного текста программы, написанной на языке… … Википедия
-
MIX — MIX это гипотетический компьютер, использованный в монографии Дональда Кнута, «Искусство программирования»[1]. Номер модели компьютера MIX 1009, происходит от комбинации номеров и названий коммерческих моделей машин, современных… … Википедия
-
Макроассемблер — Эта статья о компьютерных программах, о языке программирования см.: Язык ассемблера Ассемблер (от англ. assembler рабочий сборщик) компьютерная программа, компилятор исходного текста программы написанной на языке ассемблера, в программу на… … Википедия
-
устройство — 2.5 устройство: Элемент или блок элементов, который выполняет одну или более функцию. Источник: ГОСТ Р 52388 2005: Мототранспортны … Словарь-справочник терминов нормативно-технической документации
-
Типовая — 21. Типовая техническая программа обследования гидротехнических сооружений электростанций. М.: Союзтехэнерго, 1982. Источник: 87 2001: Рекомендации по проведению натурных наблюдений за осадками грунтовых плотин 3. Типовая инструкция по… … Словарь-справочник терминов нормативно-технической документации
-
команда — 2.1 команда: Электрический сигнал, несущий сообщение, передаваемое с КДП и предназначенное для управления радиотехническими средствами УВД и ближней навигации. Источник … Словарь-справочник терминов нормативно-технической документации
-
РМ 4-239-91: Системы автоматизации. Словарь-справочник по терминам. Пособие к СНиП 3.05.07-85 — Терминология РМ 4 239 91: Системы автоматизации. Словарь справочник по терминам. Пособие к СНиП 3.05.07 85: 4.2. АВТОМАТИЗАЦИЯ 1. Внедрение автоматических средств для реализации процессов СТИСО 2382/1 Определения термина из разных документов:… … Словарь-справочник терминов нормативно-технической документации