Цель: изучить синтаксис условного оператора; научиться применять оператор if-elif-else; уметь применять простые и составные условия.
Теория
Логические значения и выражения
В Python для хранения логических значений используется тип bool. Существует только два литерала для логических значений — True (истина) и False (ложь). Результатом вычисления логического выражения является одно из двух логических значений.
Операторы сравнения используются, чтобы узнать равны или не равны два логических выражения, какое из них больше или меньше.
| Оператор | Название | Пример |
|---|---|---|
< |
Меньше | 6 < 10 – True; 52 < 5 – False. |
> |
Больше | 2 > 9 – False |
<= |
Меньше или равно | 5 <= 5– True; 5 <= 6– True. |
>= |
Больше или равно | 2 >= 3– False; 2 >= 2 – True. |
== |
Равно | "python" == "ruby" – False |
!= |
Не равно | 42 != 1 — True |
✔
±
Что из перечисленного является логическим выражением?
True
True и False — логические литералы. Их можно отнести к логическим выражениям.
3 + 4 == 7
Выражение 3+4 равно 7. 7 == 7 — логическое выражение.
3 + 4
Значение этого выражения число.
"False"
Значение в двойных кавычках, значит это строка.
3 == 4
Результат сравнения с помощью == принимает значение True или False.
Логические операторы
Для комбинирования логических выражений можно использовать логические операторы — not, and и or.
Значение следующего выражения True, если x больше 0 и меньше 10:
x = 5 print(x > 0 and x < 10)
Следующие выражение истинно, если x делится на 2 или делится на 3:
x = 6 print(x % 2 == 0 or x % 3 == 0)
Результат следующего логического выражения будет не истиной, если x > y и не ложью в обратном случае. Иными словами результат логического выражения инвертируется:
x = 10 y = 4 print(not x > y)
Попробуйте поменять значения переменных x и y в примерах, чтобы получить разные значения логических выражений.
✔
±
Какие из логических выражений помогут определить, что значение переменной x лежит между 0 и 5?
x > 0 and < 5
Не хватает x в правой части оператора and.
x > 0 or x < 5
Значение этого логического выражения всегда будет равно True, так как любое число больше 0 или меньше 5.
0 < x < 5
Как не странно, такой вариант записи условия допустим в Python.
x > 0 and x < 5
Правильный вариант. Значение x одновременно больше 0 и меньше 5.
Приоритет операторов
Арифметические операторы имеют больший приоритет чем операторы сравнения и логические операторы. Затем вычисляется значение выражений с операторами сравнения. Самый низкий приоритет у логических операторов. Например в выражении x * 5 >= 10 and y - 6 <= 20 в первую очередь выполнятся операторы * и -, потом произойдёт сравнение (операторы >= и <=) и в самом конце выполниться логический оператор and. В этом примере, если x = 1 a y = 7, то значение всего выражения будет равно
x
?
.
| Приоритет | Операторы |
|---|---|
| 7(высокий) | ** |
| 6 | *, /, //, % |
| 5 | +, - |
| 4 | ==, !=, <=, >=, >, < |
| 3 | not |
| 2 | and |
| 1(низкий) | or |
✔
Какой из вариантов расстановки скобок в следующем выражении отражает последовательность выполнения операторов:
5 * 3 > 10 and 4 + 6 == 11((((5 * 3) > 10) and 4) + 6) == 11
((5 * 3) > 10) and ((4 + 6) == 11)
((5 * 3) > (10 and (4 + 6))) == 11
(5 * (3 > 10)) and (4 + (6 == 11))
* и + выполняться в первую очередь, затем операторы сравнения и в конце логический оператор and.
У арифметических операторов приоритет выше чем у операторов сравнения.
Операторы не выполняются слева-направо, а выполняются согласно их приоритету.
and не обладает большим приоритетом, чем ==.
Инструкция “Ветвление”
Полная форма
Общая форма записи полной формы инструкции ветвления:
if <логическое выражение>:
# если логическое выражение == True
<блок инструкций 1>
else:
# если логическое выражение == False
<блок инструкций 2>graph TD
A([Начало]) --> B{Логическое<br>выражение<br>истино?}:::diamond
B --> F(( ))
F --> |Да| C[блок инструкций 1]
F --> |Нет| D[блок инструкций 2]
C --> E([Конец])
D --> E
Обратите внимание, что после : набор инструкций записывается с отступом. С помощью отступа в Python обозначаются блоки инструкций. Конец строки считается концом инструкции, конец отступа считается концом блока инструкций. Рисунок 1 содержит диаграмму работы полной формы ветвления.
Обратите внимание на правила оформления блоков инструкций. Это важно, так как в Python вложенность инструкций определяется именно отступами.
- Блок связанных инструкций должен иметь одинаковый отступ.
- Размер отступа может быть произвольным (рекомендовано 4 пробела).
- Для создания отступов можно использовать пробелы или табуляцию.
- Нельзя смешивать пробелы и символы табуляции при оформлении одного блока.
В следующем примере определим чётность или нечётность значения в переменной x:
x = 15
if x % 2 == 0:
print(x, "чётное")
else:
print(x, "нечётное")
Сокращённая форма
Ветвление можно записать в сокращённой форме без оператора else:
x = 10
if x < 0:
print(x, "отрицательное число")
print("Конец программы")
Попробуйте поменять значение x на отрицательное число и запустить программу ещё раз.
✔
Есть ли синтаксические ошибки в следующем коде:
x = -10
if x < 0:
print("Отрицательное число ", x, " не подойдёт")
else:
print(x, " положительное число")
else:
print("Конец программы")Последний блок else не привязан ни к одному if. В коде есть ошибка.
У каждого блока else должен быть соответствующий ему блок if. В коде есть ошибка.
Как обозначить пустой блок инструкций? (нажмите, чтобы открыть)
Иногда бывает необходимо обозначить пустой блок инструкций, чтобы реализовать его позже. В таком случае пригодится инструкция pass (пропустить):
if x < 0:
pass # TODO: придумать как обработать отрицательные значенияЗапись без инструкции pass вызовет синтаксическую ошибку:
if x < 0:
# Ошибка! Пустой блок инструкций
# следующие инструкцииКаскадное ветвление
Инструкции ветвления могут быть вложены друг в друга.
x = 1.6
y = 3.1
if x < y:
print("x меньше y")
else:
if x > y:
print("x больше y")
else:
print("x равно y")
Рисунок 2 содержит диаграмму с ходом выполнения алгоритма.
graph TD
A([Начало]) --> B[x = 1.6<br>y = 3.1]
B --> C{x < y?}
C --> D(( ))
D -->|Да| E[/x меньше y/]
D -->|Нет| F{x > y?}
F --> G(( ))
G -->|Да| H[/x больше y/]
G -->|Нет| I[/x равно y/]
E --> J(( ))
H --> J
I --> J
J --> K([Конец])
В Python такую последовательность условий можно записать иначе с помощью инструкции elif:
x = 1.6
y = 3.1
if x < y:
print("x меньше y")
elif x > y:
print("x больше y")
else:
print("x равно y")
В обоих случаях будет выполнена только одна из ветвей алгоритма.
К примеру следующий код:
if x < y and x < z:
print(1)
elif y < x and y < z:
print(2)
else:
print(3)При x = 3, y = 5 и z = 2 выведет на экран цифру
x .
Примеры
Познакомьтесь с готовыми решениями задач. Ответьте на вопросы после кода решения каждой задачи.
Пример № 1 (ex01.py)
Напишите программу, которая бы получала на вход температуру воздуха из прогноза погоды и выводила на экран краткую характеристику. Если температура меньше 5 градусов вывести сообщение «Холодно, оденьтесь теплее»; если температура больше либо равна 5, но меньше 20 градусов вывести сообщение «На улице прохладно»; если температура больше либо равна 20 градусов – «На улице тепло».
print("Погода на сегодня")
t = float(input("Введите температуру в градусах Цельсия: "))
#не забывайте про отступы в условном операторе
if t < 5:
print("Холодно, оденьтесь теплее.")
if t >= 5 and t < 20:
print("На улице прохладно.")
if t >= 20:
print("На улице тепло.")
В строке номер
x
?
пользователь вводит сегодняшнюю температуру воздуха. В строке номер
x
?
используется логический оператор
x
and. Значение всего логического выражения будет равно True, если значения
x
обоих логических выражений будет равно True.
В программе встречается только
x
сокращённая форма инструкции if.
Пример № 2 (ex02.py)
Напишите программу вычисляющую корни квадратного уравнения по заданным коэффициентам a, b и c. В случае если корень один – вывести на экран один корень. Если корней нет – вывести соответствующее сообщение.
#загрузка модуля содержащего математические функции
import math
print("Вычисление корней квадратного уравнения")
a = float(input("введите коэффициент a "))
b = float(input("введите коэффициент b "))
c = float(input("введите коэффициент c "))
D = b ** 2 - 4 * a * c
print("дискриминант: ", D)
if D > 0:
root1 = (-b + math.sqrt(D)) / (2 * a)
root2 = (-b - math.sqrt(D)) / (2 * a)
print("Корни уравнения: ", root1, root2)
elif D == 0:
root = (-b + math.sqrt(D)) / (2 * a)
print("Корень уравнения: ", root)
else:
print("Корней нет")
В программе используется
x
каскадная форма записи инструкции if.
В строке
x
?
проверяется, равен ли дискриминант нулю. В этом случае значение корня уравнения сохраняется в переменную с именем
x
. Инструкции после оператора
x
else выполнятся, если уравнение не имеет корней.
Задания для самостоятельной работы
Задание № 1 (sam01.py)
Дано целое число. Если оно является положительным, то прибавьте к нему 1; в противном случае оставьте значение числа без изменений. Выведите полученное число на экран.
Задание № 2 (sam02.py)
Даны две переменные A и B. Если их значения равны, то присвоить каждой переменной сумму этих значений, а если не равны, то присвоить переменным нулевые значения. Значения переменных A и B вводятся с клавиатуры. Выведите новые значения переменных на экран.
Задание № 3 (sam03.py)
С клавиатуры вводится номер месяца. Нумерация месяцев начинается с 1. Выведите на экран пору года к которой принадлежит этот месяц — зима, весна, лето или осень.
Используйте каскадную форму записи инструкции ветвления.
Учтите, что к зимним относятся месяцы с номерами 1, 2 и 12.
Достаточно прописать логические выражения для трёх пор года. Если ни одно из трёх условий не выполнится, значит выполнится ветвь else для оставшейся последней поры года. Так получится сократить код.
month = int(input("Введите номер месяца (от 1 до 12): "))
if month == 1 or month == 2 or month == 12:
print("Зима")
elif month >=3 and month <=5:
print("Весна")
elif month >= 6 and month <= 8:
print("Лето")
else:
print("Осень")Задание № 4 (sam04.py)
Индекс массы тела – это величина, которая позволяет оценить степень соответствия массы человека и его роста и рассчитывается по формуле
\[
I=\frac{m}{h^2}
\]
где m – масса тела в килограммах, h – рост в метрах. Нормой считается значение индекса в диапазоне от 18 до 25. Напишите программу рассчитывающую индекс массы тела по введённым данным и выводящее сообщение в трёх случаях: значение индекса в норме, индекс меньше нормы, индекс больше нормы.
Задание № 5 (sam05.py)
Високосным является год, значение которого делится на 4, но при этом не делится на 100, либо делится на 400. Напишите программу, которая определяет, является ли введённый год високосным или нет, и выводит соответствующее сообщение.
Синтаксис языка программирования
Чтобы начать писать даже простейшие программы на языке Python (и не только на нем), необходимо изучить хотя бы
первичные основы синтаксиса языка. В противном случае компьютер просто не сможет понять и правильно выполнить нашу программу. Например, если
строку кода print(‘Привет, Мир!’) из задания предыдущего параграфа записать в виде
print (‘Привет, Мир!’), интерпретатор выдаст ошибку и не выведет это приветствие на
экран, т.к. в инструкции мы неправильно употребили пробел. Казалось бы мелочь, но его там вообще быть не должно. Таковы правила синтаксиса
языка Python.
Синтаксис языка программирования – это набор
правил, которые определяют структуру и порядок написания программ на этом языке.
Говоря о синтаксисе, мы подразумеваем правила написания идентификаторов и литералов, использования ключевых слов, разделения и оформления
инструкций и комментариев и т.д. Уверенное знание всех этих правил, позволит нам писать программы любой сложности, допуская при этом минимум ошибок.
А учитывая простоту и лаконичность синтаксиса Python, сделать это будет совсем не трудно. Но прежде, для расширения
кругозора, давайте познакомимся с понятиями лексемы и литерала.
Лексемы и литералы в Python
Если синтаксис – это набор правил, которые помогают нам (программистам) правильно писать инструкции, то лексемы — это кирпичики, из которых мы эти
инструкции составляем.
Лексема – это минимальная единица кода программы, которая имеет для
интерпретатора определенный смысл и не может быть разбита на более мелкие логические части.
Все лексемы в Python делятся на пять основных групп: идентификаторы и ключевые слова
(NAME), литералы (NUMBER, STRING и т.д.), символы операций
(OP), разделители (NEWLINE, INDENT, ENDMARKER и др.) и
комментарии (COMMENT).
Узнать из каких лексем состоит тот или иной участок исходного кода Python можно при помощи модуля лексического
сканера tokenize, который можно найти в стандартной библиотеке в разделе
Python Language Services. После получения списка лексем, его можно использовать,
например, для синтаксической подсветки кода на языке Python, логического разбора кода или каких-нибудь других целей.
Для того, чтобы необходимый модуль библиотеки стал доступен для использования в скрипте, его нужно сперва к нему подключить, т.е.
импортировать.
Делается это при помощи ключевого слова import, после которого через пробел указывается требуемый модуль. В нашем случае инструкция
импорта может выглядеть как import tokenize.
Чтобы получить наглядное представление о лексемах, давайте рассмотрим пример №1, в котором представлен код
простейшей программы, разбивающей строку с исходным python-кодом на лексемы и выводящей их на экран (для
просмотра результата работы программы не забудьте нажать кнопку «Результат»).
Код
Результат
pythonCodes
# Импортируем необходимые модули стандартной библиотеки.
import io, token, tokenize
# Создаем многострочную строку с кодом.
code_example = '''# Это словарь - именованная коллекция объектов.
my_dict = {'Имя': 'Python', 'Версия': "3.9.0"}
# Выводим значения на экран.
print(my_dict['Имя'], my_dict['Версия'])'''
# Это позволит нам работать со строкой, как с файловым объектом.
rl = io.StringIO(code_example).readline
# Разбиваем код на токены, т.е. лексемы с указанием
# места их расположения в коде.
tkns = tokenize.generate_tokens(rl)
# Проходимся по всем токенам циклом.
for tkn in tkns:
# Выводим тип, имя и саму лексему.
print(tkn[0], ' -> ', token.tok_name[tkn[0]], ' -> ', tkn[1])60 -> COMMENT -> # Это словарь - именованная коллекция объектов.
61 -> NL ->
5 -> INDENT ->
1 -> NAME -> my_dict
54 -> OP -> =
54 -> OP -> {
3 -> STRING -> 'Имя'
54 -> OP -> :
3 -> STRING -> 'Python'
54 -> OP -> ,
3 -> STRING -> 'Версия'
54 -> OP -> :
3 -> STRING -> "3.9.0"
54 -> OP -> }
4 -> NEWLINE ->
61 -> NL ->
60 -> COMMENT -> #Выводим значения на экран.
61 -> NL ->
1 -> NAME -> print
54 -> OP -> (
1 -> NAME -> my_dict
54 -> OP -> [
3 -> STRING -> 'Имя'
54 -> OP -> ]
54 -> OP -> ,
1 -> NAME -> my_dict
54 -> OP -> [
3 -> STRING -> 'Версия'
54 -> OP -> ]
54 -> OP -> )
4 -> NEWLINE ->
6 -> DEDENT ->
0 -> ENDMARKER ->Пример №1. Разложение python-кода на лексемы.
Как видим, лексический сканер выделил нам такие лексемы, как # Выводим значения на экран.
(комментарий), print (ключевое слово), my_dict (идентификатор),
{, :, ] (символы операций),
‘Версия’ (строковый литерал). Присутствуют в разборе и разделители в виде символов новой строки, которые при
отображении на экране добавили нам заметные отступы.
Что касается термина токен, то это та же самая лексема, только с указанием ее местонахождения в исходном
коде. Дело в том, что лексические сканеры обычно выделяют не только сами лексемы, но также номера строк и столбцов, где каждая лексема начинается и
заканчивается.
Токен – это набор из лексемы и ее координат в исходном коде языка
программирования.
Теперь давайте скажем пару слов о литералах. Термин этот мы уже встречали, осталось понять, что они из себя представляют.
Литералы – это простые неименованные значения некоторого типа
данных, написанные непосредственно в самом коде программы.
В качестве примеров приведем литералы, которые являются значениями различных типов данных: вещественное число 3.4,
целое число 5, комплексное число 5+3j, строка в двойных кавычках
«яблоко», строка в одинарных кавычках ‘две груши’, логические значения
True и False, словарь {1: 1, ‘два’: 2},
список [1, 2, 3] и т.д. При этом, если, например, литерал числа 28840.0303178
является одновременно и лексемой (пусть и выглядит она подозрительно большой), то литерал списка [1, 2] состоит
сразу из пяти лексем.
Итак, лексемы – это логически неделимые фрагменты кода, а литералы – обычные значения в нем.
Имена в Python
Идентификаторы – это просто имена (например, переменных, функций или
классов). В Python идентификаторы чувствительны к регистру символов, должны начинаться с буквы любого алфавита в
Юникоде или символа подчеркивания (_), после чего могут следовать любые буквы,
цифры или символы подчеркивания. При этом с цифры имена начинаться не должны, иначе интерпретатор не сможет отличить их от чисел.
Примерами идентификаторов могут служить: b (латинская буква), ж (русская буква),
_b (начинается со знака подчеркивания), py_2 (включает цифру),
_Чаво (начинается со знака подчеркивания и включает русские буквы, одна из которых заглавная),
G123 (начинается с заглавной буквы), set_name
(имя в «змеиной» нотации), setName (имя в
«верблюжей» нотации), ClassName (стиль CapWords) и т.д.
В то же время комбинации символов 15var_1, $Var2 или
var 3 не могут использоваться в качестве идентификаторов, т.к. они начинаются либо содержат недопустимые
символы (третье имя содержит пробел). Также следует помнить про регистр используемых символов, поскольку, например, идентификаторы
var_1, Var_1 и VAR_1 обозначают имена совершенно
разных переменных или функций, т.к. регистр символов у них не совпадает.
Для лучшего восприятия кода следует давать именам понятные и по возможности краткие названия, которые бы соответствовали, например, хранящимся
в переменных данным или же выполняемым функциями действиям. Кроме того, идентификаторы могут состоять как из одной буквы, так и сразу из нескольких
слов. Для таких случаев в программировании существуют два распространенных устоявшихся стиля записи идентификаторов, которые называются
camelCase («верблюжьяНотация») и snake_case («змеиная_нотация»). Если идентификатор
состоит из одного слова, то в обоих случаях он пишется строчными буквами. При наличии двух и более слов, в верблюжей
нотации первое слово идентификатора пишется строчными буквами, а каждое последующее слово начинается с заглавной буквы. В змеиной
нотации все слова пишутся строчными буквами, но каждое последующее слово идентификатора отделяется от предыдущего знаком подчеркивания
(см. пример №2).
Код
pythonCodes
# Одинаково в любой нотации.
cars = 5
автобусы = 10
# Змеиная нотация (используется для переменных и функций
# внутри Python и ее стандартной библиотеки).
go_to_str = True
# Верблюжья нотация (обычно используется для переменных
# и функций сторонних библиотек и модулей).
goToStr = True
# Стиль CapWords (используется для классов и констант
# как внутри Python, так и в большинстве библиотек).
GoToStr = True
# Собственные константы я пишу заглавными буквами.
STR_LEN = 20
# Смешивать нотации можно, но не рекомендуется.
goTo_str = False
Пример №2. Стили записи идентификаторов.
Обычно программисты сами решают, какой стиль записи имен использовать в своих программах (если конечно не приходится подчиняться общепринятым
правилам компании или проекта). Более того, никто не запрещает смешивать сразу оба стиля. Главное помнить, что в плане восприятия так поступать не
рекомендуется.
Что касается соглашений по именам в Python, то они подробно описаны в руководстве по написанию кода
PEP8 на официальном сайте.
Отступы и точка с запятой в Python
В отличие от многих других языков программирования в Python каждая инструкция
(команда на языке Python) обычно отделяется от других не точкой с запятой (;),
а переводом строки. Общее правило в Python гласит, что конец строки автоматически считается концом инструкции,
находящейся в этой строке. В свою очередь это правило порождает другое, которое предписывает (за редким исключением) писать в каждой строке
по одной инструкции (см. пример №3).
Код
Результат
pythonCodes
# Имеем 4 инструкции по одной на каждой строке.
# Точку с запятой нигде не ставим.
a = 3.7
b = 5.2
c = a + b
# Выведет 8.9
print(c)
# -------------------------
# Конечно, точки с запятой ошибок не вызовут,
# но в Python так поступать не принято!!!
a = 3.7;
b = 5.2;
c = a + b;
# Опять же выведет 8.9
print(c);8.9 8.9
Пример №3. Примеры разделения инструкций в Python.
Другим важным отличием языка Python является то, что вложенные инструкции одного уровня должны оформляться
одинаковыми отступами от левого края. Именно по величине отступов интерпретатор определяет, где заканчивается очередной блок инструкций и начинается
новый. Общий шаблон оформления составных (вложенных) инструкций имеет вид:
Основная инструкция: Вложенный блок инструкций
Неважно, какие отступы мы будем использовать, главное, чтобы для инструкций одного уровня вложенности они были одинаковыми (см. пример
№4). Так это могут быть символы табуляции или несколько подряд идущих пробелов, но что-то одно в пределах
одного блока инструкций.
Код
Результат
pythonCodes
# Для отступов вложенных инструкций мы
# использовали по одному символу табуляции Tab.
a = 3.7
b = 5.2
# Если делитель больше нуля, то
if a > 0:
# делим числа
c = a/b
# и выводим результат на экран.
print(c)
# Иначе, если
elif a < 0:
# перемножаем числа
c = a*b
# и выводим результат на экран.
print(c)
# Иначе
else:
# выводим предупреждение.
print('На ноль делить нельзя!')0.7115384615384616
Пример №4. Порядок использования отступов в Python.
Если бы в примере выше мы использовали для первой вложенной инструкции символ табуляции, а для второй или третьей символы пробела, интерпретатор
выдал бы нам ошибку. При этом визуально отступы могли бы выглядеть одинаковыми! Такое может быть при равенстве длины символа табуляции использованному
количеству пробелов. Поэтому следует выбрать для себя какой-то один вариант расстановки отступов, чтобы в дальнейшем не путаться. К слову, в
официальной документации советуется использовать четыре подряд идущих пробела (см. здесь).
Как и в большинстве других языков программирования в Python присутствует условная инструкция
if, которая в общем случае имеет следующий формат записи:
if <Условие №1>:
<Блок инструкций №1>
elif <Условие №2>:
<Блок инструкций №2>
...
else:
<Запасной блок инструкций>
Если первое условие истинно (результатом вычислений будет True), то выполняется первый блок инструкций. Если первое условие ложно
(результатом вычислений будет False), то проверяются по-очереди все условия необязательных блоков elif и, если найдется
истинное условие, то выполняется соответствующий условию блок инструкций. Если все дополнительные условия окажутся ложными, выполнится запасной блок инструкций
else. Обязательным является только блок инструкций if, остальные блоки могут быть опущены. При этом разрешается
использовать любое количество блоков elif, но только один блок else (еще раз посмотрите на пример выше).
Мы обязательно вернемся к более детальному рассмотрению этой условной инструкции. Пока же просто будем иметь о ней некоторое представление. Тоже
самое касается и другой новой информации подаваемой в блоках с зеленой левой границей.
Далее. Бывают ситуации, когда в коде короткие инструкции идут одна за другой. Тогда некоторые программисты записывают их на одной
строке, разделяя точкой с запятой. Кроме того, на одной строке с основной инструкцией разрешается записывать и односторочные вложенные инструкции
(см. пример №5). Однако все это пусть и допускается, но в Python не приветствуется!
Код
Результат
pythonCodes
# Пишем 2 инструкции на одной строке.
# Вот здесь-то как раз и нужна точка с запятой.
a = 3.7; b = 5.2
# А здесь мы записали на одной строке и основную инструкцию, и вложенные,
# не забыв разделить 2 вложенные инструкции точкой с запятой.
if a > 0: c = a/b; print(c)
else: print('На ноль делить нельзя!')
# Согласитесь, что читаемость кода упала. Поэтому старайтесь поступать
# так как можно реже! А еще лучше, вообще никогда так не делайте!0.7115384615384616
Пример №5. Запись нескольких инструкций на одной строке.
Обратите внимание, что когда мы записывали вложенную инструкцию на одной строке с основной, точку с запятой мы не ставили. А вот две вложенные
инструкции, расположенные на одной строке, мы, во избежание ошибки, точкой с запятой разделили.
Итак, мы выяснили, что инструкции в Python следует записывать по одной на каждой строке. При этом использовать
точку с запятой не нужно, т.к. конец строки автоматически завершает текущую инструкцию. Но что, если инструкция получается слишком длинной и не
помещается полностью на экране? В этом случае можно расположить ее на нескольких строках, заключив в зависимости от ситуации в пару круглых,
квадратных или фигурных скобок (см. пример №6).
Код
Результат
pythonCodes
# Обычные короткие инструкции.
import math
a = 3
d = 56.33
s = 1.041
# Чтобы расположить длинную инструкцию на нескольких строках,
# нужно просто заключить ее в круглые скобки.
n = (
143.77 + 34*(math.sqrt(439.25)) -
23/(math.pi - a*d) + abs(-36*s)
)
# Т.к. синтаксис литерала списка предусматривает квадратные
# скобки, круглые писать не нужно.
li = [
'а', 'б', 'в', 'г', 'д', 'е', 'ё', 'ж', 'з', 'и', 'й', 'к',
'л', 'м', 'н', 'о', 'п', 'р', 'с', 'т', 'у', 'ф', 'х', 'ц',
'ч', 'ш', 'щ', 'ъ', 'ы', 'ь', 'э', 'ю', 'я'
]
# А вот синтаксис литерала словаря требует наличие фигурных скобок.
dict = {
1: 'а', 2: 'б', 3: 'в', 4: 'г', 5: 'д', 6: 'е', 7: 'ё',
8: 'ж', 9: 'з', 10: 'и', 11: 'й', 12: 'к', 13: 'л',
14: 'м', 15: 'н', 16: 'о', 17: 'п', 18: 'р', 19: 'с',
20: 'т', 21: 'у', 22: 'ф', 23: 'х', 24: 'ц', 25: 'ч',
26: 'ш', 27: 'щ', 28: 'ъ', 29: 'ы', 30: 'ь', 31: 'э',
32: 'ю', 33: 'я'
}
# Выведем все на экран.
print('Значение выражения: ', n, end='\n\n')
print('Русские буквы в нижнем регистре: ', li, end='\n\n')
print('Словарь с цифровыми ключами: ', dict, end='\n\n')
# Скопируйте код примера и проверьте его работоспособность.Значение выражения: 893.9666059760239
Русские буквы в нижнем регистре: ['а', 'б', 'в', 'г', 'д', 'е', 'ё',
'ж', 'з', 'и', 'й', 'к', 'л', 'м', 'н', 'о', 'п', 'р', 'с', 'т', 'у',
'ф', 'х', 'ц', 'ч', 'ш', 'щ', 'ъ', 'ы', 'ь', 'э', 'ю', 'я']
Словарь с цифровыми ключами: {1: 'а', 2: 'б', 3: 'в', 4: 'г', 5: 'д',
6: 'е', 7: 'ё', 8: 'ж', 9: 'з', 10: 'и', 11: 'й', 12: 'к', 13: 'л',
14: 'м', 15: 'н', 16: 'о', 17: 'п', 18: 'р', 19: 'с', 20: 'т', 21: 'у',
22: 'ф', 23: 'х', 24: 'ц', 25: 'ч', 26: 'ш', 27: 'щ', 28: 'ъ', 29: 'ы',
30: 'ь', 31: 'э', 32: 'ю', 33: 'я'}
Пример №6. Запись одной инструкции на нескольких строках.
Вообще, в официальном руководстве советуют использовать строки кода с длиной не более 79 символов. Поэтому,
если ситуация выходит из-под контроля, необходимо не задумываясь применять для переноса длинных строк скобки. Сложностей с выбором подходящего
вида скобок возникать не должно, т.к. для каждой синтаксической конструкции предусмотрен свой тип скобок. Например, если мы при помощи литерала
объявляем список или словарь, то автоматически подразумеваем квадратные и, соответственно, фигурные скобки. А вот синтаксис вызова функции или
литерала кортежа требует от нас использования круглых скобок. Все эти знания приходят со временем и начинают казаться чем-то само собой разумеющимся.
Как вы уже поняли, для вывода информации на экран используется встроенная функция print(), которой через запятую
следует передавать выводимые на экран значения. Отметим, что все значения сначала автоматически преобразуются в строки и только потом выводятся.
При этом в качестве дополнительных аргументов функции можно передавать именованные строковые аргументы sep и
end. Первый задает вид разделителя между выводимыми значениями (по умолчанию это обычный пробел, т.е.
sep=’ ‘), а второй – символы в конце вывода (по умолчанию это символ перевода строки, т.е.
end=’\n’). В итоге инструкция вывода, например, двух значений может иметь такой вид:
print(‘один’, ‘два’, sep=’ ‘, end=’\n’).
Комментарии в Python
Еще одной важной частью синтаксиса любого языка программирования являются комментарии.
В Python используются только однострочные комментарии, которые начинаются с символа
#. Комментарии идут только до конца строки и весь код после символа #
интерпретатором игнорируется (см. пример №7). При этом принято записывать комментарии на отдельной строке
до инструкции, а не вставлять их после в той же строке.
Код
pythonCodes
# Комментарии начинаются с символа решетки, после которого
# принято ставить пробел. Все предложения комментариев
# принято начинать с заглавной буквы и заканчивать точкой.
# a = 3.7 - эта инструкция не сработает, т.к. считается комментарием.
# Многострочные комментарии синтаксисом не предусмотрены, но!!!
# Для этого вполне подойдут строки в тройных кавычках.
# Удобный многострочный комментарий.
'''b = 5.2
# Комментарии принято писать на отдельной строке.
c = a + b
print(c) # А вот так комментарии не принято писать.
'''
# Здесь появится ошибка.
''' Т.к. многострочные комментарии ''' нельзя '''использовать
внутри других многострочных """комментариев''' даже, если
для них используются разные кавычки"""Пример №7. Комментарии в Python.
Многострочные комментарии синтаксисом Python не предусмотрены. Вместо них используются подряд идущие
однострочные комментарии. Однако многие программисты, как показано в примере, в ходе тестирования кода часто используют для создания временных многострочных
комментариев строки в тройных кавычках. В результате такого хака многострочные комментарии представляют собой любой текст, расположенный между комбинациями
символов »’ и »’ или же «»» и
«»». Такие многострочные комментарии поглощают однострочные, могут содержать несколько строк, но при этом
не могут быть вложенными друг в друга.
Текст комментариев интерпретатором игнорируется, но их наличие в исходном коде переоценить практически невозможно. Ведь любой программист на
собственном опыте знает, что по прошествии определенного времени разобраться даже в собственном коде становится все сложнее. Поэтому в процессе
разработки программ нужно обязательно использовать комментарии, которые позволяют:
- освежить в памяти программиста различные мелкие детали;
- подсказывают, какую задачу решает тот или иной фрагмент кода, в особенности, если код чужой;
- позволяют в случае необходимости временно закомментировать фрагмент кода, например, во время отладки программы;
- играют роль предупреждений, например, о необходимости применения именно данного решения, а не на первый взгляд более очевидного.
Следует помнить, что при внесении в исходный код изменений необходимо одновременно обновлять и комментарии! Иначе рано или поздно возникнет
неразбериха, в которой код будет выполнять одно, а комментарии подразумевать совсем другое.
В любом случае, правильно составленные комментарии ускоряют как разработку кода, так и его отладку в дальнейшем.
Форматирование python-кода
Если вы еще не посетили официальную страницу руководства PEP8 по написанию кода на
Python, сделайте это сейчас хотя бы для ознакомления. Здесь же мы еще раз кратко пройдемся по основным
принципам форматирования python-кода, заполнив при этом некоторые пробелы. Итак.
- На каждой строке следует писать по одной инструкции, не вставляя в конце точку с запятой.
-
После основной инструкции должно присутствовать двоеточие. При этом одинаковые блоки вложенных инструкций должны отделяться с левой стороны
идентичными отступами. В идеале для этого нужно использовать по четыре пробела на каждый уровень вложенности. -
Строки кода по возможности должны полностью помещаться в видимой области экрана монитора. В идеале они не должны превышать длины в
79 символов. Для переноса длинных инструкций на новую строку в зависимости от ситуации следует использовать
круглые, квадратные или фигурные скобки. -
В большинстве случаев интерпретатор игнорирует подряд идущие пробелы и символы табуляции (отступы сюда не относятся!!!). Поэтому для визуального
разделения некоторых лексем и повышения читабельности кода можно смело использовать пробелы (см. пример №8).
Однако при этом желательно придерживаться устоявшихся стандартов и, например, не ставить подряд несколько пробелов, а также не использовать для
таких целей символы табуляции. -
Комментарии в исходном коде следует писать на отдельной строке, а не вместе с инструкцией на одной строке. При этом принято отделять символ
решетки от текста комментария пробелом, а предложения начинать с заглавной буквы и завершать точкой.
Код
pythonCodes
# Многие операторы рекомендуется отделять пробелами.
a = 3
a += 5
# Перед символами ,, :, ;, . пробел ставить не принято.
c, d = 5, 3
# Как и в вызовах функций вокруг символа =,
def my_func(s=5, b=0.5):
# и в выражениях вокруг знаков умножения и деления.
return (s*d + s/d) * (s%d + 0.1)/5.05
# Также не нужно ставить пробелы сразу после
# открывающей скобки или перед закрывающей.
dict = {'color': 'red'}Пример №8. Примеры использования пробелов в коде Python.
Пугаться такого количества рекомендаций не стоит. Большинство из них в скором времени станут для вас естественным способом оформления кода. А
некоторые рекомендации вы и вовсе будете игнорировать, где-то умышленно, а где-то и рефлекторно. Я, например, не люблю ставить пробел в начале
комментариев, часто забываю завершать их точкой. Также я привык не отделять пробелами операторы присваивания, ставить их после запятых и т.д.
Но придерживаться рекомендаций по оформлению кода в Python все-таки стоит. Не нужно перенимать вредные привычки,
ведь потом от них будет очень трудно избавиться.
Вопросы и задания для самоконтроля
1. Что такое синтаксис языка программирования?
Показать решение.
Ответ.
Синтаксис языка программирования – это набор
правил, которые определяют структуру и порядок написания программ на этом языке.
2. Какие из представленных фрагментов кода являются литералами:
«a==5», d = 0.5, [0.5, ‘cat’],
{‘color’: ‘green’}, import math,
‘Синий иней’.
Показать решение.
Ответ.
«a==5» – литерал строки в двойных кавычках, [0.5, ‘cat’] – литерал списка,
{‘color’: ‘green’} – литерал словаря, ‘Синий иней’ – литерал строки в
одинарных кавычках.
3. Опишите правила составления имен (идентификаторов) в Python.
Показать решение.
Ответ.
В Python идентификаторы чувствительны к регистру символов, должны начинаться с буквы любого алфавита в
Юникоде или знака подчеркивания _, после чего могут следовать любые буквы,
цифры или символы подчеркивания. При этом с цифры имена начинаться не должны, иначе интерпретатор не сможет отличить их от чисел.
4. Перечислите правильно составленные идентификаторы, сопровождая свой выбор пояснениями:
f, f2, d5,
3d, abc, ABC,
$h, h$2, _h___2,
h_2_, 2_h,
ruEn, d3.f3, d3_f3,
d3 f3, эй_Hey, свободный_дом2,
ухТы!!!, 3дом_слева, F15,
gggggggggg, d’25’, s_8.
Показать решение.
Ответ.
Правильно составленными являются идентификаторы (см. правила составления имен):
f, f2, d5,
abc, ABC, _h___2,
h_2_, ruEn, d3_f3,
эй_Hey, свободный_дом2,
F15, gggggggggg, s_8.
5. Составьте имя переменной в верблюжей и змеиной нотациях, используя фразу
show must go on. Как будет выглядеть имя, если использовать данную фразу для названия класса?
Показать решение.
Ответ.
Имя переменной в верблюжей нотации будет иметь вид showMustGoOn (обычно используется для переменных и
функций сторонних библиотек), при использовании змеиной нотации – show_must_go_on
(используется для переменных и функций внутри Python и ее стандартной библиотеки). Для имен классов обычно
используется нотация CupWords, поэтому имя будет иметь вид ShowMustGoOn.
6. Какой символ используется в Python для обозначения комментариев?
Определите в коде строки комментариев и закомментируйте их.
Показать решение.
Условие
pythonCodes
Присваиваем переменной значение.
a = 3
Увеличиваем значение на единицу.
b += 1
Выводим его на экран.
print(b) Условие
Решение
pythonCodes
Присваиваем переменной значение.
a = 3
Увеличиваем значение на единицу.
b += 1
Выводим его на экран.
print(b) # Присваиваем переменной значение.
a = 3
# Увеличиваем значение на единицу.
b += 1
# Выводим его на экран.
print(b)
7. Внимательно отформатируйте представленный исходный код в соответствии с официальными рекомендациями.
Показать решение.
Условие
pythonCodes
li=['red','green' , 'blue' ]; #Формируем список
#Циклом выводим значения списка на экран.
for val in li : print ( val ) Условие
Решение
pythonCodes
li=['red','green' , 'blue' ]; #Формируем список
#Циклом выводим значения списка на экран.
for val in li : print ( val ) # Формируем список.
li = ['red', 'green', 'blue']
# Циклом выводим значения списка на экран.
for val in li:
print(val)
'''
Уберите лишние пробелы, точку с запятой после списка,
правильно оформите комментарии.
'''
8. Создайте скрипт, в котором переменным num и
s, присвойте значения 500 и ‘ рублей’.
Затем выведите значения переменных на экран при помощи функции print, использовав в качестве разделителя
пустую строку и завершив вывод двумя символами перевода строки. В конце скрипта напишите комментарий «Символ = в
программировании означает присвоить, а не равно!».
Показать решение.
Решение
Результат
pythonCodes
num = 500
s = ' рублей.'
print(num, s, sep='', end='\n\n')
# Символ = в программировании означает присвоить, а не равно! 500 рублей.
Быстрый переход к другим страницам
Условия в Python
В этом уроке мы разберём особенности синтаксиса языка Python и оператор условия if в Python.
Часто в программах необходимо выполнить ряд команд при выполнении условия. Для этого используется оператор условия if
if (условие):
действия в случае выполнения условия
Оператор условия if(условие) проверяет, выполняется ли условие внутри скобок. Если условие выполняется, выполняются команды, которые идут после двоеточия и имеют одинаковый отступ от левого края.
Синтаксис Python.
В отличии от языков Си и Java, в программах на Python после команды не нужно указывать точку с запятой. Конец строки является концом инструкции (команды).Для вложенных инструкций (наборов команд, например, в условных операторах, циклах), в отличии от Си, не используются открывающие и закрывающие скобки.Чтобы записать вложенную инструкцию в Python (блок команд), необходимо указать двоеточие и все команды блока располагать с одним и тем же отступом от левого края.
Пример вложенной инструкции в программе на Python.
a = int(input(«Введите переменную a «))
if (a == 10):
print(«Это иллюстрация работы вложенной конструкции»)
print(«a равно 10»)
print(«Программа завершилась.»)
Эта программа вводит переменную a с клавиатуры.
Для оператора if используется вложенная конструкция. Если условие выполняется, то выполняется два оператора, так как они идут после двоеточия и имеют одинаковый отступ
print(«Это иллюстрация работы вложенной конструкции»)
print(«a равно 10»)
Обратите внимание, что оператор print(“Программа завершилась”) не входит во вложенную конструкцию, потому что он не имеет отступа.
В скобках оператора if() пишется условие, при котором исполняются блок команд, которые идут после двоеточия и имеют одинаковый отступ.
Пример программы с условиями на Python, которая определяет знак числа
if (a == 0):
print(«a равно нулю.»)
if (a > 0):
print(“a положительно.”)
if (a < 0):
print(“a отрицательно.”)
При задании условий используются условные операторы.

Вернуться к содержанию Следующая тема Цикл for в python
Полезно почитать по теме пример на условия в python
Пример программы диалога на python
Программа на python для решения линейного уравнения
Игра камень ножницы бумага на python
Поделиться:
Комментарии ()
Нет комментариев. Ваш будет первым!
- Как работает if else
-
Синтаксис
-
Отступы
-
Примеры
- Оператор elif
- Заглушка pass
- if else в одну строку
- Вложенные условия
- Конструкция switch case
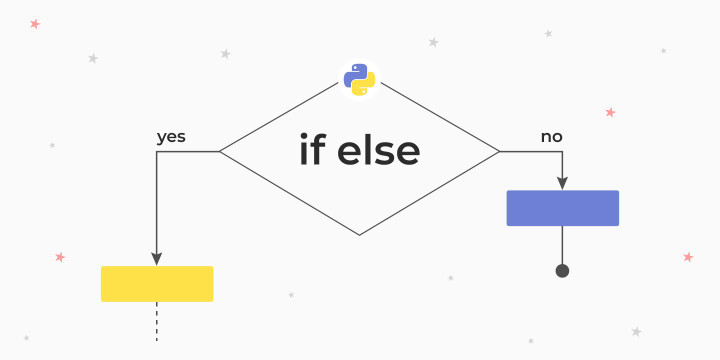
Фундаментальная важность условий для любого из языков программирования заключается в их возможности описывать большую часть логики работы программы.
if else — это оператор, управляющий условным ветвлением. Простыми словами это конструкция в Python, указывающая интерпретатору, следует ли выполнять определенный участок кода или нет.
Как и все прочие составные инструкции языка, оператор выбора также поддерживает свойство вложенности. Это означает, что использование if else позволяет создавать внутри программного модуля так называемое логическое ветвление.
Как работает if else
Синтаксис
Оператор if else в языке Python — это типичная условная конструкция, которую можно встретить и в большинстве других языков программирования.
# самый простой пример, где есть всего одно условие
a = 1
if a == 1:
print("It is true")
> It is true
Синтаксически конструкция выглядит следующим образом:
- сначала записывается часть
ifс условным выражением, которое возвращает истину или ложь; - затем может следовать одна или несколько необязательных частей
elif(в других языках вы могли встречатьelse if); - Завершается же запись этого составного оператора также необязательной частью
else.
count = 1
# условное выражение может быть сколь угодно сложным,
# и может быть сколь угодно много elif-частей
if True and count == 1 and count == 2:
print("if")
elif count == 'count':
print("First elif")
elif count == 14.2:
print("Second elif")
elif count == 1:
print("Nth elif")
else:
print("Else")
> Nth elif
Для каждой из частей существует ассоциированный с ней блок инструкций, которые выполняются в случае истинности соответствующего им условного выражения.
b = 10
if b == 10:
# любое количество инструкций
print(b)
b = b * 15
b = b - 43
b = b ** 0.5
print(b)
elif b == 20:
print("You will not see me")
else:
print("And me")
> 10
> 10.344080432788601
То есть интерпретатор начинает последовательное выполнение программы, доходит до if и вычисляет значение сопутствующего условного выражения. Если условие истинно, то выполняется связанный с if набор инструкций. После этого управление передается следующему участку кода, а все последующие части elif и часть else (если они присутствуют) опускаются.
Отступы
Отступы — важная и показательная часть языка Python. Их смысл интуитивно понятен, а определить их можно, как размер или ширину пустого пространства слева от начала программного кода.
# начало кода
# код
# код
# код
# начало первого отступа
# первый отступ
# первый отступ
# начало второго отступа
# второй отступ
# второй отступ
# конец второго отступа
# конец первого отступа
Благодаря отступам, python-интерпретатор определяет границы блоков. Все последовательно записанные инструкции, чье смещение вправо одинаково, принадлежат к одному и тому же блоку кода. Конец блока совпадает либо с концом всего файла, либо соответствует такой инструкции, которая предшествует следующей строке кода с меньшим отступом.
var_a = 5
var_b = 10
var_c = 20
if var_c**2 > var_a * var_b:
# блок №1
if var_c < 100:
# блок №2
if var_c > 10:
# блок №3
var_a = var_a * var_b * var_c
# блок №2
var_b = var_a + var_c
# блок №1
var_c = var_a - var_b
print(var_a)
print(var_b)
print(var_c)
> 1000
> 1020
> -20
Таким образом, с помощью отступов появляется возможность создавать блоки на различной глубине вложенности, следуя простому принципу: чем глубже блок, тем шире отступ.
Примеры
Рассмотрим несколько практических примеров использования условного оператора.
Пример №1: создание ежедневного бэкапа (например базы данных):
from datetime import datetime
def daily_backup(last_backup_date):
"""
Передаем дату последнего бэкапа.
Если прошло больше 1 дня, создаем бэкап
"""
if not last_backup_date:
print(f"creating first backup [{datetime.now().date()}] ..")
return
delta = datetime.now() - last_backup_date
if delta.days > 0:
print(f"creating backup [{datetime.now().date()}] ..")
else:
print(f"backup on [{datetime.now().date()}] already exists")
daily_backup("")
> creating first backup [2020-08-15] ..
daily_backup(datetime(2020, 8, 14))
> creating backup [2020-08-15] ..
daily_backup(datetime(2020, 8, 15))
> backup on [2020-08-15] already exists
Пример №2: Проверка доступа пользователя к системе. В данном примере if проверяет наличие элемента в списке:
BLACK_LIST = ['192.34.12.3', '192.34.12.5', '192.34.10.23']
USERS = ['rolli34', 'constantinpetrovv', 'kate901']
def access_available(user_name, ip):
if user_name in USERS:
if ip not in BLACK_LIST:
return True
else:
print(f"write to log: user {user_name} [ip: {ip}] in block list")
else:
print(f"write to log: user {user_name} [ip: {ip}] does not exists")
return False
if access_available("rolli34", "192.34.12.111"):
print(f"Hello!!")
> Hello!!
if access_available("rolli34", "192.34.10.23"):
print(f"Hello!!")
> write to log: user rolli34 [ip: 192.34.10.23] in block list
if access_available("devnull", "192.34.10.11"):
print(f"Hello!!")
> write to log: user devnull [ip: 192.34.10.11] does not exists
Пример №3: Валидация входных данных. В примере к нам приходят данные в формате json. Нам необходимо выбрать все записи определенного формата:
NEED = {
"name": str,
"weight": int,
"age": int,
}
def is_valid(data):
valid = True
for need_key_name, need_type in NEED.items():
# проверяем наличие ключа
if need_key_name in data:
# если ключ есть, проверяем тип значения
data_type = type(data[need_key_name])
if data_type != need_type:
print(f"type error: '{need_key_name}' is {data_type}, need: {need_type}")
valid = False
else:
print(f"key error: '{need_key_name}' does not exists")
valid = False
return valid
if is_valid({"name": "Alex"}):
print("data is valid")
>
key error: 'weight' does not exists
key error: 'age' does not exists
if is_valid({"name": "Alex", "age": "18"}):
print("data is valid")
>
key error: 'weight' does not exists
type error: 'age' is <class 'str'>, need: <class 'int'>
if is_valid({"name": "Alex", "weight": 60, "age": 18}):
print("data is valid")
> data is valid
Оператор elif
elif позволяет программе выбирать из нескольких вариантов. Это удобно, например, в том случае, если одну переменную необходимо многократно сравнить с разными величинами.
shinobi = 'Naruto'
if shinobi == 'Orochimaru':
print('fushi tensei')
elif shinobi == 'Naruto':
print('RASENGAN')
elif shinobi == 'Sasuke':
print('chidori')
> RASENGAN
Такая конструкция может содержать сколь угодно большую последовательность условий, которые интерпретатор будет по порядку проверять.
Но помните, что первое условие всегда задается с if
Также не стоит забывать, что как только очередное условие в операторе оказывается истинным, программа выполняет соответствующий блок инструкций, а после переходит к следующему выражению.
Из этого вытекает, что даже если несколько условий истинны, то исполнению подлежит все равно максимум один, первый по порядку, блок кода с истинным условием.
Если ни одно из условий для частей if и elif не выполняется, то срабатывает заключительный блок под оператором еlse (если он существует).
Заглушка pass
Оператор-заглушка pass заменяет собой отсутствие какой-либо операции.
Он может быть весьма полезен в случае, когда в ветвлении встречается много elif-частей, и для определенных условий не требуется выполнять никакой обработки.
Наличие тела инструкции в Python обязательно
sum = 100000
account_first = 12000
account_second = 360000
if account_first > sum:
pass
elif account_second > sum:
pass
else:
print(sum)
if else в одну строку
Во многих языках программирования условие может быть записано в одну строку. Например, в JavaScript используется тернарный оператор:
# так выглядит условие в одну строку в JavaScript
const accessAllowed = (age > 21) ? true : false;
Читается это выражение так: если age больше 21, accessAllowed равен true, иначе — accessAllowed равен false.
В Python отсутствует тернарный оператор
Вместо тернарного оператора, в Питоне используют инструкцию if else, записанную в виде выражения (в одно строку):
<expression if True> if <predicate> else <expression if False>
Пример:
number = -10
abs_number = number if number >= 0 else -number
print(abs_number)
Такая конструкция может показаться сложной, поэтому для простоты восприятия, нужно поделить ее на 3 блока:
Стоит ли использовать такой синтаксис? Если пример простой, то однозначно да:
# полная версия
count = 3
if count < 100:
my_number = count
else:
my_number = 100
# сокращенная версия
count = 3
my_number = count if count < 100 else 100
Вполне читаемо смотрятся и следующие 2 примера:
x = "Kate" if "Alex" in "My name is Alex" else "Mary"
print(x)
> Kate
y = 43 if 42 in range(100) else 21
print(y)
> 43
Но если вы используете несколько условий, сокращенная конструкция усложняется и становится менее читаемой:
x = 10
result = 100 if x > 42 else 42 if x == 42 else 0
print(result)
> 0
Вложенные условия
Ограничений для уровней вложенности в Python не предусмотрено, а регулируются они все теми же отступами:
# делать код менее читаемым можно до бесконечности
def run(action):
if action:
print(some_func())
else:
if some_func():
num = one_func()
if num:
if 0 < num < 100:
print(num)
else:
print('-')
Стоит ли использовать такие вложенности? Скорее нет, чем да. Одно из положений Python Zen гласит:
Flat is better than nested (развернутое лучше вложенного).
Большая вложенность имеет следующие недостатки:
- становится трудно легко найти, где заканчивается конкретный блок;
- код становится менее читаемым и сложным для понимания;
- возможно придется прокручивать окно редактора по горизонтали.
Но что делать, если в скрипте не получается уйти от большой вложенности if-else? 🤷♂️
Чтобы уйти от большой вложенности, попробуйте не использовать оператор else
Пример выше, можно записать следующим образом:
def run(action):
if action:
print(some_func())
return
if not some_func():
return
num = one_func()
if not num:
return
if 0 < num < 100:
print(num)
return
print('-')
Конструкция switch case
В Python нет классического switch case, как в других языках. Но с версии 3.10 появился мощный аналог — match case, который поддерживает распаковку, шаблоны и вложенные структуры.
В языках, где такая инструкция есть, она позволяет заменить собой несколько условий if и более наглядно выразить сравнение с несколькими вариантами.
# пример на C++
int main() {
int n = 5;
# сравниваем значение n поочередно со значениями case-ов
switch (n) {
case 1:
cout << n;
break;
case 2:
cout << n;
break;
# так как 5 не равняется ни 1-у, ни 2-м, то выполняется блок default
default:
cout << "There is not your number";
break;
}
return 0;
}
> There is not your number
Свято место пусто не бывает, поэтому в питоне такое множественное ветвление, в обычном случае, выглядит как последовательность проверок if-elif:
n = 5
if n == 1:
print(n)
elif n == 2:
print(n)
else:
print("There is not your number")
> "There is not your number"
Однако есть и более экзотический вариант реализации этой конструкции, задействующий в основе своей python-словари:
switch_dict = {
1: 1,
2: 2,
3: 3,
}
print(switch_dict.get(5, "There is not your number"))
> "There is not your number"
Использование словарей позволяет, в качестве значений, хранить вызовы функций, тем самым, делая эту конструкцию весьма и весьма мощной и гибкой.
# Глава 2. Синтаксические правила
> Код, который так же понятен, как обычный английский.
Одна из целей создания питона, озвученная автором языка Гвидо ван Россумом
Рассмотрим структуру программы и основные синтаксические правила. Также вы узнаете, для чего нужны и чем различаются оператор `pass` и объект-синглтон «многоточие».
## Структура программы
В Java, go, C++ и многих других языках точкой входа в приложение является метод `main()`. Такие языки объединяет нерушимое правило: нельзя просто написать код на уровне файла и запустить его. Питон — представитель скриптовых языков, и на него это правило не распространяется: с первой же строчки скрипта может начинаться бизнес-логика, не обернутая ни в какую функцию.
Исходный код программы на питоне принято сохранять в файлах с расширением `.py`. Для запуска из консоли необходимо вызвать интерпретатор питона и первым аргументом указать имя файла. Допустим, исходный код в `example.py` состоит из одной строчки:
«`python
print(«Dummy script, does nothing»)
«`
Тогда после запуска скрипта мы увидим в консоли ожидаемый вывод:
«`shell
$ python example.py
Dummy script, does nothing
«`
В этом коротком примере вся программа сводится к вызову встроенной функции `print()` для вывода текста. В ней нет подключения модулей, объявления переменных, классов. Что ж, усложним код.
Пусть в консоль печатается текущее время:
«`python {.example_for_playground}
from datetime import datetime
def print_time():
now = datetime.now()
current_time = now.strftime(«%H:%M:%S»)
print(«Current Time:», current_time)
print_time()
«`
«`
Current Time: 13:19:20
«`
На первой строке из модуля `datetime` импортируется одноименный объект в глобальное пространство имен программы. Затем объявляется функция `print_time()`. Внутри нее у объекта `datetime` вызывается метод `now()` для получения текущего времени; оно преобразовывается в удобный формат и печатается в консоль. На последней строке объявленная функция `print_time()` вызывается.
Пример демонстрирует общепринятую практику по **структурированию кода:** в начале файла импортируются нужные модули, затем объявляются какие-то глобальные переменные, функции и другие полезности, а в самом конце все это используется.
## Синтаксические правила
С этих правил начинают свой путь все питонисты.
**Вложенные блоки кода** отделяются отступами, а не фигурными скобками. Мы будем придерживаться [рекомендации из PEP8:](https://peps.python.org/pep-0008/#indentation) 1 отступ = 4 пробела.
Вложенному блоку предшествует инструкция, заканчивающаяся двоеточием. Перед телом цикла — это условие цикла. Перед телом `if` — условие `if`. И так далее.
Пример условия:
«`python
if user_is_active:
get_next_command()
else:
close_session()
«`
Пример цикла:
«`python
for item in items:
process(item)
«`
Пример функции:
«`python
def is_long(s):
if len(s) > 79:
return «string is too long»
return «string has normal length»
«`
Конец строки — это конец инструкции. Точка с запятой в конце не ставится.
Пример с последовательным вызовом двух пользовательских функций. Никаких точек с запятой:
«`python
check_db_is_online()
start_transaction()
«`
Инициализируйте две переменные:{.task_text}
— `a`, равную 8, на одной строке.
— `b`, равную 10, на другой.
«`python {.task_source #python_chapter_0020_task_0010}
«`
Синтаксис: переменная = значение {.task_hint}
«`python {.task_answer}
a = 8
b = 10
«`
Исправьте синтаксические ошибки в коде. {.task_text}
В данном коде используется функция `range(a, b)`, позволяющая получить последовательность от целого числа `a` до целого числа `b` не включительно. {.task_text}
«`python {.task_source #python_chapter_0020_task_0020}
for i in range(1, 10); print(i);
«`
Нужно заменить точку с запятой в конце цикла на двоеточие. Удалить точку с запятой после `print()` и перенести вызов `print()` на новую строку с отступом. {.task_hint}
«`python {.task_answer}
for i in range(1, 10):
print(i)
«`
Если инструкция не влезает в строку (например, становится длиннее рекомендованных PEP8 79 символов), ее можно разбить на несколько строк с использованием круглых скобок.
Первая строка в этом примере занимает 92 символа:
«`python
while retries_count < max_retries and service_is_up and not cancelled and request_is_ready:
send_request()
«`
Приведем ее в соответствие с PEP8:
«`python
while (
retries_count < max_retries
and service_is_up
and not cancelled
and request_is_ready
):
send_request()
«`
Разбейте условие `if` на две строки или более. {.task_text}
«`python {.task_source #python_chapter_0020_task_0030}
MAX_SESSIONS = 5
MAX_QUEUE_LEN = 100
sessions_count = 9
queue_tasks = [«task1», «task2»] # Here we create list of strings
error_in_request = True
if sessions_count > MAX_SESSIONS or len(queue_tasks) > MAX_QUEUE_LEN or error_in_request:
print(«Error handling request»)
«`
Для разбиения условия на несколько строк возьмите его в круглые скобки. {.task_hint}
«`python {.task_answer}
MAX_SESSIONS = 5
MAX_QUEUE_LEN = 100
sessions_count = 9
queue_tasks = [«task1», «task2»] # Here we create list of strings
error_in_request = True
if (
sessions_count > MAX_SESSIONS
or len(queue_tasks) > MAX_QUEUE_LEN
or error_in_request
):
print(«Error handling request»)
«`
## Исключения из правил
Из этих несложных правил есть и исключения. Но их лучше избегать, чтобы не снижать читаемость кода. Тем не менее вы можете натолкнуться на злоупотребление ими в чужом коде.
Например, несколько простых инструкций в одной строке не являются ошибкой. Друг от друга они отделяются точкой с запятой. В этом примере переменным `x` и `y` присваиваются результаты пользовательских функций:
«`python
x = x_offset(); y = y_offset(); print(x, y)
«`
Сделайте этот код более читабельным. Одна строка — одна инструкция. {.task_text}
«`python {.task_source #python_chapter_0020_task_0040}
x = 5; y = 8; print(x, y)
«`
Должно получиться 3 строки: 2 для инициализации переменных и 1 на вызов функции. {.task_hint}
«`python {.task_answer}
x = 5
y = 8
print(x, y)
«`
Также допустимо размещать инструкцию и ее вложенный блок на одной строке. Это сработает, если сам вложенный блок не содержит каких-то своих вложенных инструкций:
«`python
while is_active: send_request()
«`
Перепишите этот код, чтобы вложенный блок `while` шел на отдельной строке. {.task_text}
В коде заводится функция `send_request()`, которая затем вызывается в цикле `while`. {.task_text}
«`python {.task_source #python_chapter_0020_task_0050}
def send_request():
# some business logic
return False
is_active = True
while is_active: is_active = send_request()
«`
Тело цикла должно идти на отдельной строке с отступом. {.task_hint}
«`python {.task_answer}
def send_request():
# some business logic
return False
is_active = True
while is_active:
is_active = send_request()
«`
## Оператор pass
Бывают случаи, когда вложенный блок требуется оставить пустым. Например, ловить исключение, но не совершать дополнительных действий для его обработки:
«`python
try:
send_request(data)
except Exception:
# Do nothing
«`
Но пустой вложенный блок — это синтаксическая ошибка:
«`
SyntaxError: unexpected EOF while parsing
«`
Чтобы ее избежать, был придуман оператор `pass`. Это [ассемблеровский NOP](https://en.wikipedia.org/wiki/NOP_(code)) в мире питона. Так сказать оператор «отсутствие оператора».
Теперь синтаксической ошибки не будет:
«`python
try:
send_request(data)
except Exception:
pass
«`
Добавьте `pass` в цикл, чтобы устранить ошибку интерпретатора. {.task_text}
«`python {.task_source #python_chapter_0020_task_0060}
n = 101
while n < 100:
«`
Перед оператором `pass` не забудьте сделать отступ. {.task_hint}
«`python {.task_answer}
n = 101
while n < 100:
pass
«`
## Многоточие
В питоне существует объект-синглтон «многоточие», привязанный к константе с именем `Ellipsis` и литералу `…`:
«`python {.example_for_playground}
print(Ellipsis)
print(…)
«`
«`
Ellipsis
Ellipsis
«`
У многоточия несколько вариантов использования, и наиболее распространенный — это проставление вместо ключевого слова `pass`. Об остальных применениях (расширенный синтаксис срезов, аннотации типов и т.д.) мы поговорим в следующих главах.
«`python
def handle_request(req):
…
«`
При этом многоточие не является семантической заменой `pass`: `pass` принято проставлять в качестве индикатора намеренного отсутствия кода, а многоточие — как напоминание TBD (to be defined) при активной разработке. Например, если соответствующий блок кода планируется добавить в следующем реквесте.
## Комментарии
Однострочные комментарии начинаются с символа `#`:
«`python
# TODO: refactor coords calculation
x = x_offset() # get x offset
«`
Многострочные комментарии обрамляются тремя подряд идущими кавычками: двойными `»` либо одинарными `’`.
«`python
«»»
TODO:
refactor before release!
«»»
«`
«`python
»’
TODO:
refactor before release!
»’
«`
PEP8 рекомендует использовать для многострочных комментариев двойные кавычки.
Если многострочный комментарий следует сразу за объявлением модуля, функции, класса или метода, то он называется **docstring.** Большинство современных IDE умеют делать подсказки на основе docstring.
Пример docstring для функции:
«`python
def get_coords():
«»»Here we calculate x, y and transform
these coordinates to lat, lon»»»
pass
«`
## Резюмируем
— Блоки кода определяются двоеточием и отступами.
— Для обозначения отсутствия операции во вложенном блоке предусмотрен оператор `pass`.
— Объект-синглтон `Ellipsis` и соответствующий ему литерал `…` имеют несколько вариантов использования. Самый частый — проставление многоточия `…` вместо `pass` для маркировки мест, где кода еще нет, но планируется его дописать.
— Однострочные комментарии начинаются с символа `#`, многострочные — заключаются в тройные кавычки.