Загрузить PDF
Загрузить PDF
HTTrack — свободный офлайн-браузер с открытым исходным кодом, разработанный Xavier Roche и распространяемый по лицензии GNU General Public.
Браузер позволяет загружать сайты из интернета на локальный компьютер. По умолчанию HTTrack формирует загруженный сайт по относительной ссылке-структуре оригинального сайта. Загруженный (или «зеркальный») веб-сайт можно просматривать, открыв страницу сайта в браузере.
-

Перейдите на официальный сайт и скачайте браузер в разделе «Download».
-
Может включать несколько веб-сайтов.
-
Дополнительно можно ввести базовый путь, по умолчанию проект будет сохранен в корневом каталоге веб-директории.
-
Введите адреса веб-сайтов, которые вы хотите дублировать (разделите их запятыми или пробелами).
-
- дублировать сайт;
- дублировать мастер сайта;
- просто получить указанные файлы;
- дублировать все ссылки с URL-адресов;
- проверить ссылку URL;
- выход.
-
-
-
По желанию задайте дополнительные параметры, такие как лимит ресурса.
-
-
Будьте терпеливы, дождитесь окончания процесса!
Реклама










Советы
- По умолчанию в этом браузере нет индикатора выполнения, поэтому наберитесь терпения.
- Нажмите Ctrl + C во время копирования для выбора вариантов, включая паузы.
Реклама
Предупреждения
- Загрузка может занять долгое время.
Реклама
Об этой статье
Эту страницу просматривали 8497 раз.
Была ли эта статья полезной?
| httrack(1) | General Commands Manual | httrack(1) |
NAME
httrack — offline browser : copy websites to a local directory
SYNOPSIS
httrack [ url ]… [ -filter ]… [ +filter ]… [ -O,
—path ] [ -w, —mirror ] [ -W, —mirror-wizard ] [ -g,
—get-files ] [ -i, —continue ] [ -Y, —mirrorlinks ] [
-P, —proxy ] [ -%f, —httpproxy-ftp[=N] ] [ -%b,
—bind ] [ -rN, —depth[=N] ] [ -%eN, —ext-depth[=N] ] [
-mN, —max-files[=N] ] [ -MN, —max-size[=N] ] [ -EN,
—max-time[=N] ] [ -AN, —max-rate[=N] ] [ -%cN,
—connection-per-second[=N] ] [ -GN, —max-pause[=N] ] [ -cN,
—sockets[=N] ] [ -TN, —timeout[=N] ] [ -RN,
—retries[=N] ] [ -JN, —min-rate[=N] ] [ -HN,
—host-control[=N] ] [ -%P, —extended-parsing[=N] ] [ -n,
—near ] [ -t, —test ] [ -%L, —list ] [ -%S,
—urllist ] [ -NN, —structure[=N] ] [ -%D,
—cached-delayed-type-check ] [ -%M, —mime-html ] [ -LN,
—long-names[=N] ] [ -KN, —keep-links[=N] ] [ -x,
—replace-external ] [ -%x, —disable-passwords ] [ -%q,
—include-query-string ] [ -o, —generate-errors ] [ -X,
—purge-old[=N] ] [ -%p, —preserve ] [ -%T,
—utf8-conversion ] [ -bN, —cookies[=N] ] [ -u,
—check-type[=N] ] [ -j, —parse-java[=N] ] [ -sN,
—robots[=N] ] [ -%h, —http-10 ] [ -%k, —keep-alive ] [
-%B, —tolerant ] [ -%s, —updatehack ] [ -%u,
—urlhack ] [ -%A, —assume ] [ -@iN, —protocol[=N] ] [
-%w, —disable-module ] [ -F, —user-agent ] [ -%R,
—referer ] [ -%E, —from ] [ -%F, —footer ] [ -%l,
—language ] [ -%a, —accept ] [ -%X, —headers ] [ -C,
—cache[=N] ] [ -k, —store-all-in-cache ] [ -%n,
—do-not-recatch ] [ -%v, —display ] [ -Q, —do-not-log ]
[ -q, —quiet ] [ -z, —extra-log ] [ -Z, —debug-log ]
[ -v, —verbose ] [ -f, —file-log ] [ -f2,
—single-log ] [ -I, —index ] [ -%i, —build-top-index ]
[ -%I, —search-index ] [ -pN, —priority[=N] ] [ -S,
—stay-on-same-dir ] [ -D, —can-go-down ] [ -U,
—can-go-up ] [ -B, —can-go-up-and-down ] [ -a,
—stay-on-same-address ] [ -d, —stay-on-same-domain ] [ -l,
—stay-on-same-tld ] [ -e, —go-everywhere ] [ -%H,
—debug-headers ] [ -%!, —disable-security-limits ] [ -V,
—userdef-cmd ] [ -%W, —callback ] [ -K, —keep-links[=N]
] [
DESCRIPTION
httrack allows you to download a World Wide Web site from
the Internet to a local directory, building recursively all directories,
getting HTML, images, and other files from the server to your computer.
HTTrack arranges the original site’s relative link-structure. Simply open a
page of the «mirrored» website in your browser, and you can browse
the site from link to link, as if you were viewing it online. HTTrack can
also update an existing mirrored site, and resume interrupted downloads.
EXAMPLES
- httrack www.someweb.com/bob/
-
mirror site www.someweb.com/bob/ and only this site - httrack www.someweb.com/bob/ www.anothertest.com/mike/ +*.com/*.jpg
-mime:application/* -
mirror the two sites together (with shared links) and accept any .jpg files
on .com sites - httrack www.someweb.com/bob/bobby.html +* -r6
- means get all files starting from bobby.html, with 6 link-depth, and
possibility of going everywhere on the web - httrack www.someweb.com/bob/bobby.html —spider -P
proxy.myhost.com:8080 - runs the spider on www.someweb.com/bob/bobby.html using a proxy
- httrack —update
- updates a mirror in the current folder
- httrack
- will bring you to the interactive mode
- httrack —continue
- continues a mirror in the current folder
OPTIONS
General options:
- -O
- path for mirror/logfiles+cache (-O path mirror[,path cache and logfiles])
(—path <param>)
Action options:
- -w
- *mirror web sites (—mirror)
- -W
- mirror web sites, semi-automatic (asks questions) (—mirror-wizard)
- -g
- just get files (saved in the current directory) (—get-files)
- -i
- continue an interrupted mirror using the cache (—continue)
- -Y
- mirror ALL links located in the first level pages (mirror links)
(—mirrorlinks)
Proxy options:
- -P
- proxy use (-P proxy:port or -P user:pass@proxy:port) (—proxy
<param>) - -%f
- *use proxy for ftp (f0 don t use) (—httpproxy-ftp[=N])
- -%b
- use this local hostname to make/send requests (-%b hostname) (—bind
<param>)
Limits options:
- -rN
- set the mirror depth to N (* r9999) (—depth[=N])
- -%eN
- set the external links depth to N (* %e0) (—ext-depth[=N])
- -mN
- maximum file length for a non-html file (—max-files[=N])
- -mN,N2
- maximum file length for non html (N) and html (N2)
- -MN
- maximum overall size that can be uploaded/scanned (—max-size[=N])
- -EN
- maximum mirror time in seconds (60=1 minute, 3600=1 hour)
(—max-time[=N]) - -AN
- maximum transfer rate in bytes/seconds (1000=1KB/s max)
(—max-rate[=N]) - -%cN
- maximum number of connections/seconds (*%c10)
(—connection-per-second[=N]) - -GN
- pause transfer if N bytes reached, and wait until lock file is deleted
(—max-pause[=N])
Flow control:
- -cN
- number of multiple connections (*c8) (—sockets[=N])
- -TN
- timeout, number of seconds after a non-responding link is shutdown
(—timeout[=N]) - -RN
- number of retries, in case of timeout or non-fatal errors (*R1)
(—retries[=N]) - -JN
- traffic jam control, minimum transfert rate (bytes/seconds) tolerated for
a link (—min-rate[=N]) - -HN
- host is abandoned if: 0=never, 1=timeout, 2=slow, 3=timeout or slow
(—host-control[=N])
Links options:
- -%P
- *extended parsing, attempt to parse all links, even in unknown tags or
Javascript (%P0 don t use) (—extended-parsing[=N]) - -n
- get non-html files near an html file (ex: an image located outside)
(—near) - -t
- test all URLs (even forbidden ones) (—test)
- -%L
- <file> add all URL located in this text file (one URL per line)
(—list <param>) - -%S
- <file> add all scan rules located in this text file (one scan rule
per line) (—urllist <param>)
Build options:
- -NN
- structure type (0 *original structure, 1+: see below)
(—structure[=N]) - -or
- user defined structure (-N «%h%p/%n%q.%t»)
- -%N
- delayed type check, don t make any link test but wait for files download
to start instead (experimental) (%N0 don t use, %N1 use for unknown
extensions, * %N2 always use) - -%D
- cached delayed type check, don t wait for remote type during updates, to
speedup them (%D0 wait, * %D1 don t wait)
(—cached-delayed-type-check) - -%M
- generate a RFC MIME-encapsulated full-archive (.mht) (—mime-html)
- -LN
- long names (L1 *long names / L0 8-3 conversion / L2 ISO9660 compatible)
(—long-names[=N]) - -KN
- keep original links (e.g. http://www.adr/link) (K0 *relative link, K
absolute links, K4 original links, K3 absolute URI links, K5 transparent
proxy link) (—keep-links[=N]) - -x
- replace external html links by error pages (—replace-external)
- -%x
- do not include any password for external password protected websites (%x0
include) (—disable-passwords) - -%q
- *include query string for local files (useless, for information purpose
only) (%q0 don t include) (—include-query-string) - -o
- *generate output html file in case of error (404..) (o0 don t generate)
(—generate-errors) - -X
- *purge old files after update (X0 keep delete) (—purge-old[=N])
- -%p
- preserve html files as is (identical to -K4 -%F «» )
(—preserve) - -%T
- links conversion to UTF-8 (—utf8-conversion)
Spider options:
- -bN
- accept cookies in cookies.txt (0=do not accept,* 1=accept)
(—cookies[=N]) - -u
- check document type if unknown (cgi,asp..) (u0 don t check, * u1 check but
/, u2 check always) (—check-type[=N]) - -j
- *parse Java Classes (j0 don t parse, bitmask: |1 parse default, |2 don t
parse .class |4 don t parse .js |8 don t be aggressive)
(—parse-java[=N]) - -sN
- follow robots.txt and meta robots tags (0=never,1=sometimes,* 2=always,
3=always (even strict rules)) (—robots[=N]) - -%h
- force HTTP/1.0 requests (reduce update features, only for old servers or
proxies) (—http-10) - -%k
- use keep-alive if possible, greately reducing latency for small files and
test requests (%k0 don t use) (—keep-alive) - -%B
- tolerant requests (accept bogus responses on some servers, but not
standard!) (—tolerant) - -%s
- update hacks: various hacks to limit re-transfers when updating (identical
size, bogus response..) (—updatehack) - -%u
- url hacks: various hacks to limit duplicate URLs (strip //,
www.foo.com==foo.com..) (—urlhack) - -%A
- assume that a type (cgi,asp..) is always linked with a mime type (-%A
php3,cgi=text/html;dat,bin=application/x-zip) (—assume
<param>) - -can
- also be used to force a specific file type: —assume
foo.cgi=text/html - -@iN
- internet protocol (0=both ipv6+ipv4, 4=ipv4 only, 6=ipv6 only)
(—protocol[=N]) - -%w
- disable a specific external mime module (-%w htsswf -%w htsjava)
(—disable-module <param>)
Browser ID:
- -F
- user-agent field sent in HTTP headers (-F «user-agent name»)
(—user-agent <param>) - -%R
- default referer field sent in HTTP headers (—referer <param>)
- -%E
- from email address sent in HTTP headers (—from <param>)
- -%F
- footer string in Html code (-%F «Mirrored [from host %s [file %s [at
%s]]]» (—footer <param>) - -%l
- preffered language (-%l «fr, en, jp, *» (—language
<param>) - -%a
- accepted formats (-%a «text/html,image/png;q=0.9,*/*;q=0.1»
(—accept <param>) - -%X
- additional HTTP header line (-%X «X-Magic: 42» (—headers
<param>)
Log, index, cache
- -C
- create/use a cache for updates and retries (C0 no cache,C1 cache is
prioritary,* C2 test update before) (—cache[=N]) - -k
- store all files in cache (not useful if files on disk)
(—store-all-in-cache) - -%n
- do not re-download locally erased files (—do-not-recatch)
- -%v
- display on screen filenames downloaded (in realtime) — * %v1 short version
— %v2 full animation (—display) - -Q
- no log — quiet mode (—do-not-log)
- -q
- no questions — quiet mode (—quiet)
- -z
- log — extra infos (—extra-log)
- -Z
- log — debug (—debug-log)
- -v
- log on screen (—verbose)
- -f
- *log in files (—file-log)
- -f2
- one single log file (—single-log)
- -I
- *make an index (I0 don t make) (—index)
- -%i
- make a top index for a project folder (* %i0 don t make)
(—build-top-index) - -%I
- make an searchable index for this mirror (* %I0 don t make)
(—search-index)
Expert options:
- -pN
- priority mode: (* p3) (—priority[=N])
- -p0
- just scan, don t save anything (for checking links)
- -p1
- save only html files
- -p2
- save only non html files
- -*p3
- save all files
- -p7
- get html files before, then treat other files
- -S
- stay on the same directory (—stay-on-same-dir)
- -D
- *can only go down into subdirs (—can-go-down)
- -U
- can only go to upper directories (—can-go-up)
- -B
- can both go up&down into the directory structure
(—can-go-up-and-down) - -a
- *stay on the same address (—stay-on-same-address)
- -d
- stay on the same principal domain (—stay-on-same-domain)
- -l
- stay on the same TLD (eg: .com) (—stay-on-same-tld)
- -e
- go everywhere on the web (—go-everywhere)
- -%H
- debug HTTP headers in logfile (—debug-headers)
Guru options: (do NOT use if possible)
- -#X
- *use optimized engine (limited memory boundary checks)
(—fast-engine) - -#0
- filter test (-#0 *.gif www.bar.com/foo.gif ) (—debug-testfilters
<param>) - -#1
- simplify test (-#1 ./foo/bar/../foobar)
- -#2
- type test (-#2 /foo/bar.php)
- -#C
- cache list (-#C *.com/spider*.gif (—debug-cache <param>)
- -#R
- cache repair (damaged cache) (—repair-cache)
- -#d
- debug parser (—debug-parsing)
- -#E
- extract new.zip cache meta-data in meta.zip
- -#f
- always flush log files (—advanced-flushlogs)
- -#FN
- maximum number of filters (—advanced-maxfilters[=N])
- -#h
- version info (—version)
- -#K
- scan stdin (debug) (—debug-scanstdin)
- -#L
- maximum number of links (-#L1000000) (—advanced-maxlinks[=N])
- -#p
- display ugly progress information (—advanced-progressinfo)
- -#P
- catch URL (—catch-url)
- -#R
- old FTP routines (debug) (—repair-cache)
- -#T
- generate transfer ops. log every minutes (—debug-xfrstats)
- -#u
- wait time (—advanced-wait)
- -#Z
- generate transfer rate statistics every minutes (—debug-ratestats)
Dangerous options: (do NOT use unless you exactly know what you are doing)
- -%!
- bypass built-in security limits aimed to avoid bandwidth abuses
(bandwidth, simultaneous connections) (—disable-security-limits) - -IMPORTANT
- NOTE: DANGEROUS OPTION, ONLY SUITABLE FOR EXPERTS
- -USE
- IT WITH EXTREME CARE
Command-line specific options:
- -V
- execute system command after each files ($0 is the filename: -V «rm
\$0») (—userdef-cmd <param>) - -%W
- use an external library function as a wrapper (-%W
myfoo.so[,myparameters]) (—callback <param>)
Details: Option N
- -N0
- Site-structure (default)
- -N1
- HTML in web/, images/other files in web/images/
- -N2
- HTML in web/HTML, images/other in web/images
- -N3
- HTML in web/, images/other in web/
- -N4
- HTML in web/, images/other in web/xxx, where xxx is the file extension
(all gif will be placed onto web/gif, for example) - -N5
- Images/other in web/xxx and HTML in web/HTML
- -N99
- All files in web/, with random names (gadget !)
- -N100
- Site-structure, without www.domain.xxx/
- -N101
- Identical to N1 except that «web» is replaced by the site s
name - -N102
- Identical to N2 except that «web» is replaced by the site s
name - -N103
- Identical to N3 except that «web» is replaced by the site s
name - -N104
- Identical to N4 except that «web» is replaced by the site s
name - -N105
- Identical to N5 except that «web» is replaced by the site s
name - -N199
- Identical to N99 except that «web» is replaced by the site s
name - -N1001
- Identical to N1 except that there is no «web» directory
- -N1002
- Identical to N2 except that there is no «web» directory
- -N1003
- Identical to N3 except that there is no «web» directory (option
set for g option) - -N1004
- Identical to N4 except that there is no «web» directory
- -N1005
- Identical to N5 except that there is no «web» directory
- -N1099
- Identical to N99 except that there is no «web» directory
Details: User-defined option N
%n Name of file without file type (ex: image)
%N Name of file, including file type (ex: image.gif)
%t File type (ex: gif)
%p Path [without ending /] (ex: /someimages)
%h Host name (ex: www.someweb.com)
%M URL MD5 (128 bits, 32 ascii bytes)
%Q query string MD5 (128 bits, 32 ascii bytes)
%k full query string
%r protocol name (ex: http)
%q small query string MD5 (16 bits, 4 ascii bytes)
%s? Short name version (ex: %sN)
%[param] param variable in query string
%[param:before:after:empty:notfound] advanced variable extraction
Details: User-defined option N and advanced variable
extraction
%[param:before:after:empty:notfound]
- -param
- : parameter name
- -before
- : string to prepend if the parameter was found
- -after
- : string to append if the parameter was found
- -notfound
- : string replacement if the parameter could not be found
- -empty
- : string replacement if the parameter was empty
- -all
- fields, except the first one (the parameter name), can be empty
Details: Option K
- -K0
- foo.cgi?q=45 -> foo4B54.html?q=45 (relative URI, default)
- -K
- -> http://www.foobar.com/folder/foo.cgi?q=45 (absolute URL)
(—keep-links[=N]) - -K3
- -> /folder/foo.cgi?q=45 (absolute URI)
- -K4
- -> foo.cgi?q=45 (original URL)
- -K5
- -> http://www.foobar.com/folder/foo4B54.html?q=45 (transparent proxy
URL)
Shortcuts:
- —mirror
-
<URLs> *make a mirror of site(s) (default) - —get
-
<URLs> get the files indicated, do not seek other URLs (-qg) - —list
-
<text file> add all URL located in this text file (-%L) - —mirrorlinks
- <URLs> mirror all links in 1st level pages (-Y)
- —testlinks
-
<URLs> test links in pages (-r1p0C0I0t) - —spider
-
<URLs> spider site(s), to test links: reports Errors & Warnings
(-p0C0I0t) - —testsite
-
<URLs> identical to —spider - —skeleton
-
<URLs> make a mirror, but gets only html files (-p1) - —update
-
update a mirror, without confirmation (-iC2) - —continue
-
continue a mirror, without confirmation (-iC1) - —catchurl
-
create a temporary proxy to capture an URL or a form post URL - —clean
-
erase cache & log files - —http10
-
force http/1.0 requests (-%h)
Details: Option %W: External callbacks prototypes
see htsdefines.h
FILES
/etc/httrack.conf
The system wide configuration file.
ENVIRONMENT
- HOME
- Is being used if you defined in /etc/httrack.conf the line path
~/websites/#
DIAGNOSTICS
Errors/Warnings are reported to hts-log.txt by default, or
to stderr if the -v option was specified.
LIMITS
These are the principals limits of HTTrack for that moment. Note
that we did not heard about any other utility that would have solved
them.
— Several scripts generating complex filenames may not find
them (ex: img.src=’image’+a+Mobj.dst+’.gif’)
— Some java classes may not find some files on them (class
included)
— Cgi-bin links may not work properly in some cases
(parameters needed). To avoid them: use filters like -*cgi-bin*
BUGS
Please reports bugs to <bugs@httrack.com>. Include a
complete, self-contained example that will allow the bug to be reproduced,
and say which version of httrack you are using. Do not forget to detail
options used, OS version, and any other information you deem necessary.
COPYRIGHT
Copyright (C) 1998-2024 Xavier Roche and other contributors
This program is free software: you can redistribute it and/or
modify it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or (at your
option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General
Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see
http://www.gnu.org/licenses/.
AVAILABILITY
The most recent released version of httrack can be found at:
http://www.httrack.com
Xavier Roche <roche@httrack.com>
SEE ALSO
The HTML documentation (available online at
http://www.httrack.com/html/ ) contains more detailed information.
Please also refer to the httrack FAQ (available online at
http://www.httrack.com/html/faq.html )
Многие пользователи сталкивались с необходимостью сохранить интересующий их веб-ресурс для дальнейшего изучения или архивирования. К сожалению, стандартными средствами браузеров это сделать крайне затруднительно. На помощь приходит бесплатная программа HTTrack Website Copier, позволяющая с легкостью скачать сайты целиком. В этой подробной инструкции вы узнаете, как эффективно пользоваться HTTrack для решения своих задач, настраивать параметры закачки, избегать типичных ошибок и получать рабочие локальные копии сайтов. Читайте дальше и откройте для себя удобный инструментарий веб-мастера!
Что такое HTTrack Website Copier
HTTrack Website Copier — это бесплатная программа для Windows, позволяющая скачивать сайты целиком на локальный компьютер. Она сохраняет всю структуру каталогов, html-страницы, изображения, скрипты, стили и прочие файлы сайта для последующего просмотра без подключения к интернету.
HTTrack Website Copier хорошо подходит в таких ситуациях:
- Нужно изучить структуру и наполнение сайта конкурента
- Требуется сохранить любимый ресурс из опасения, что он может закрыться
- Необходим офлайн-доступ к веб-страницам в поездках или командировках без интернета
- Планируется воссоздать сайт заново, сохранив его контент
HTTrack Website Copier поддерживает HTTP, HTTPS и FTP протоколы, умеет работать через прокси-сервер. Программа распространяется абсолютно бесплатно на официальном сайте HTTrack Website Copier.
Как скачать и установить HTTrack
Чтобы скачать последнюю версию HTTrack для Windows, заходим на официальный сайт и нажимаем кнопку Download в верхнем меню. Выбираем версию для своей ОС (32 или 64 бит) и ждем загрузки установочного файла httrack_x64-3.49.2.exe.
Примечание: на момент написания статьи актуальная версия программы — 3.49.2 от 20 мая 2017 года.
Установка HTTrack ничем не отличается от других Windows-приложений:
- Запускаем загруженный exe-файл
- Соглашаемся с лицензионным соглашением
- Выбираем папку для установки программы (по умолчанию C:\Program Files\HTTrack Website Copier\)
- Ждем окончания копирования файлов
- Готово! Можно запускать HTTrack и скачивать сайты
Интерфейс и основные возможности
После первого запуска HTTrack Website Copier встречает нас стандартным окном Новый проект. Здесь нужно задать имя новому проекту, папку, куда будут сохраняться загруженные файлы, и нажать кнопку «Далее»:
На следующем шаге вводим веб-адрес сайта, который хотим скачать и снова жмем «Далее». Открываются дополнительные настройки загрузки:
- Фильтры — разрешить/запретить загрузку файлов по маске или расширению
- Ограничения — глубина закачки сайта, макс. размеры файлов и др.
- Прокси — настройки прокси-сервера
- Идентификация — имитация браузера: Firefox, Chrome, Safari
Главное в настройках — параметр «Максимальная глубина». Он отвечает за то, насколько уровней вглубь от основной страницы будет происходить закачка. Чем выше число — тем больше данных и времени потребуется.
После того, как заданы все параметры, нажимаем кнопку «Старт» и HTTrack Website Copier приступает к загрузке указанного ресурса. Во время работы отображается текущая скорость передачи данных, количество скачанных страниц и другая полезная статистика.

Советы по использованию HTTrack Website Copier
Чтобы эффективно пользоваться HTTrack Website Copier, придерживайтесь следующих советов:
- Перед началом закачки оцените объем данных на сайте. Иначе загрузка может продолжаться очень долго, а ресурсы ПК будут забиты ненужным контентом
- Ограничьте глубину загрузки уровнем 2-3, если вам нужны только основные страницы сайта
- Используйте фильтры, чтобы исключить ненужные файлы: картинки, скрипты, CSS и т.д.
- При длительной загрузке можно приостановить процесс и продолжить позже. Для этого есть пункт меню «Менеджер загрузки»
- Запустите локальное зеркало загруженного сайта через «Просмотр зеркала». Теперь можно изучать его без интернета!
winhttrack website copier инструкция
WinHTTrack Website Copier — это альтернативная версия программы HTTrack для ОС Windows. По функциональности она полностью идентична оригинальному HTTrack, но имеет другой интерфейс с вкладками. Работать в ней так же просто:
- Запускаем WinHTTrack и во вкладке «Новый проект» указываем имя и путь сохранения
- На вкладке «Конфигурация» вводим URL сайта для скачивания и настраиваем параметры загрузки
- Жмем кнопку «Запустить»
- Следим за ходом загрузки на вкладке «Скачивание»
- По окончании можно просмотреть скачанный сайт во вкладке «Просмотр»
За исключением другого интерфейса, все остальные возможности у WinHTTrack Website Copier полностью идентичны обычной версии HTTrack. Поэтому вы легко сможете работать с любой из этих программ для скачивания сайтов.

httrack website copier отзывы
Пользователи отзываются о HTTrack Website Copier в целом положительно, отмечая такие достоинства программы:
- Полная бесплатность и открытый исходный код
- Простота освоения даже для новичков
- Возможность гибко настроить параметры загрузки сайта
- Надежное сохранение всей структуры и файлов веб-ресурса
- Кроссплатформенность: работает в Windows, Linux, Android
К недостаткам можно отнести:
- Нет обновлений с 2017 года
- Иногда зависает при больших нагрузках
- Некорректно работает с некоторыми сложными сайтами
- Загружает много мусора: лишние картинки, битые ссылки и пр.
Тем не менее, HTTrack Website Copier остается лучшим бесплатным решением для скачивания сайтов под Windows. Главное — правильно настроить фильтры и ограничения загрузки, чтобы получить действительно нужную информацию с ресурса.
Резервное копирование сайта перед изменениями
Еще один полезный сценарий использования HTTrack Website Copier — это резервное копирование вашего сайта перед глобальными изменениями в коде или структуре. Допустим, вы планируете перевести сайт на новую CMS, мигрировать на другой хостинг, либо внедрить серьезные изменения в dizain и наполнение. Стоит сделать полную локальную копию старой версии с помощью HTTrack, чтобы при необходимости можно было откатиться назад или восстановить какие-то удаленные или испорченные данные.
Резервное копирование и сохранение удаленных сайтов
К сожалению бывает, что по каким-то причинам сайты закрываются или полностью удаляют контент. Чтобы сохранить для истории или личного пользования понравившийся веб-ресурс, его можно целиком скопировать с помощью HTTrack Website Copier. В локальной офлайн копии удаленного сайта можно будет почитать статьи, посмотреть изображения и медиафайлы.
httrack website copier пользоваться для сравнения с конкурентами
Еще одно интересное применение HTTrack — это анализ и сравнение своего сайта с конкурентами. Скачав 1-2 похожих сайта по тематике целиком и изучив их структуру, дизайн, контентную стратегию, можно позаимствовать и внедрить лучшие идеи у себя. Таким образом вы сможете повысить конкурентоспособность своего ресурса.
winhttrack website copier portable для скачивания сайта с разных устройств
Дистрибутив HTTrack Website Copier не требует установки — его можно просто распаковать в любую папку и запускать как портативное переносимое приложение. Например, у вас имеется флешка с портабельной версией WinHTTrack Website Copier. Теперь вы можете подключать ее к разным компьютерам (дома, на работе, в интернет-кафе) и скачивать нужные сайты, не нарушая целостности системы.
httrack website copier portable rus для русскоязычного интерфейса
В дополнение к английской версии, для HTTrack Website Copier доступен русский интерфейс. Такое приложение называется «портабельная русская версия». Чтобы скачать HTTrack Website Copier на русском языке в портативном варианте, загрузите архив с сайта portablesoft.ru и распакуйте на компьютер. Теперь можно пользоваться знакомым русскоязычным интерфейсом этой программы для скачивания сайтов.
Как пользоваться httrack website copier 3 x
HTTrack Website Copier 3.x — это общее название для всех версий утилиты начиная с 3-й итерации. На данный момент актуальная версия — 3.49.2. Пользоваться любой из версий 3.x не составляет труда — интерфейс и базовый функционал не претерпели серьезных изменений. Просто скачиваем нужную версию httrack_x64-3.xx.exe, устанавливаем, создаем новый проект, вводим URL сайта, выставляем параметры загрузки и нажимаем Старт. Все версии HTTrack Website Copier 3.x обладают широкими возможностями для эффективного скачивания сайтов.
Что делать, если текущее зеркало пусто в HTTrack Website Copier
Иногда при попытке просмотра загруженного локального зеркала сайта в HTTrack Website Copier появляется сообщение «Текущее зеркало пусто». Это означает, что программа не смогла сохранить файлы по каким-то причинам. Возможные решения:
- Проверьте настройки фильтров и ограничений, возможно стоит расширить диапазоны
- Увеличьте значение параметра «Максимальная глубина» до 5-10
- Перезапустите загрузку сайта, на этот раз дождитесь полного окончания
- Проверьте доступность сайта, возможно проблема на стороне сервера
- Очистите кеш и cookies браузера и повторите загрузку
Если перечисленные советы не помогли, то, возможно, данный сайт по техническим причинам невозможно полностью скачать при помощи HTTrack Website Copier.
Особенности копирования динамических сайтов
Современные веб-ресурсы зачастую используют сложные скрипты, чтобы динамически загружать контент в зависимости от действий посетителей. Такие сайты сложнее скопировать при помощи HTTrack Website Copier. Чтобы увеличить шанс успешной закачки, включите в настройках:
- Полную имитацию браузера
- Обработку JavaScript
- Загрузку файлов по требованию скриптов
Также постарайтесь максимально расширить фильтры и глубину копирования. Но все равно, некоторые очень сложные динамические сайты могут быть некорректно сохранены HTTrack.
Бан списков HTTrack Website Copier
HTTrack имеет встроенный механизм работы со списками URL для загрузки или исключения из загрузки. Это удобно использовать для автоматического резервного копирования ваших сайтов или, наоборот, для блокировки нежелательных. Просто сохраните список сайтов в TXT файл и укажите его в настройках HTTrack перед закачкой через опцию «URL list».
Пауза и возобновление закачки в HTTrack Website Copier
Если вы сохраняете очень большой сайт, процесс может занять много времени. Чтобы сделать перерыв, нажмите кнопку «Приостановить» в основном окне программы. Потом запустите HTTrack снова, выберите проект в списке на первом шаге и нажмите «Возобновить». Процесс загрузки продолжится с того же места.
Очистка кэша и логов HTTrack
Со временем кэш и логи накапливают много данных. Чтобы освободить место на диске, периодически заходите в меню «Инструменты» -> «Обслуживание» и нажимайте кнопки «Очистить кэш» и «Удалить старые логи». Также рекомендуется время от времени делать перезапуск HTTrack, чтобы сбросить временные данные.
Introduction
In this post, you will learn what is httrack and how does it work and also you will learn some important and useful commands in the tool. Below is the video format of the post, Check it out 👇🏾
Video:
What is HTTrack ❓
HTTrack is an offline browser accessory, Allows you to download a World Wide Website from the Internet to a local directory you want.
In simple HTTrack mirrors the target site and just saves it in the local directory you want.
Also Read: Full tutorial on SQLMAP
Why we should mirror sites using HTTrack
Great question, The httrack allows you to take a mirror of the target. So, you will not directly interact with the target.
If you directly interact with the target there are many possibilities that you will get caught by the sensors like the IDS and IPS.
So, Mirroring a target site is the best way to do brute force and other colourfully stuffs.
Advertisement
Who developed the tool
The tool is developed by the httrack guy and also below is the possible link I found related to the httrack creators.
Commands in HTTrack
General options:
O path for mirror/logfiles+cache (-O path_mirror[,path_cache_and_logfiles]) (–path )
Shortcuts:
–mirror *make a mirror of the site(s) (default)
–list add all URLs located in this text file (-%L)
–mirror links mirror all links in 1st level pages (-Y)
–testlinks test links in pages (-r1p0C0I0t)
–spider site(s), to test links: reports Errors & Warnings (-p0C0I0t)
–test site identical to –spider
–skeleton make a mirror but gets only HTML files (-p1)
–update a mirror, without confirmation (-iC2)
–continue a mirror, without confirmation (-iC1)
–catchurl create a temporary proxy to capture an URL or a form post URL
–clean erase cache & log files
–http10 force http/1.0 requests (-%h)
Advertisement
How to work with HTTrack
Just follow the below steps and by end of the step, you will mirror a site
Step1: Open a terminal and enter httrack
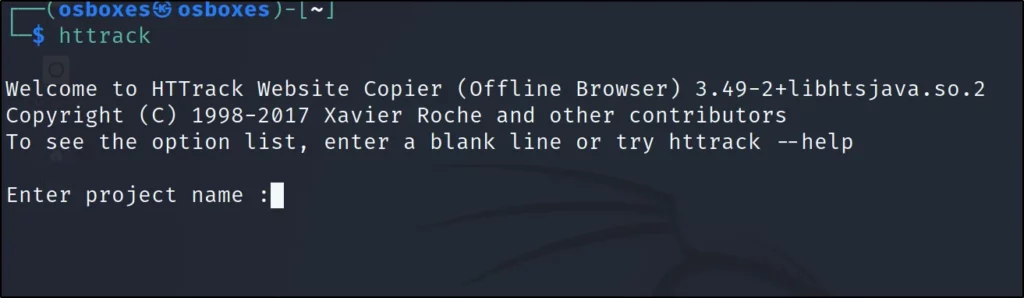
Step2: Now, enter a name for your project, Iam going with project 001

Step3: Now enter the directory where you want to save the project
Step4: Enter the target to scan and also you can add multiple URL by entering comma in between.

Step5: Choose an action
1 Mirror Web Site(s): Mirror only the URL
2 Mirror Web Site(s) with Wizard: Mirror URL with explanation
3 Just Get Files Indicated: Only mirrors the get files
4 Mirror ALL links in URLs (Multiple Mirror): Mirrors all the links the target
5 Test Links In URLs (Bookmark Test): Just the link of URL
0 Quit: Exit
Often I go with 4

Step6: If you want to enter proxy just enter http://localhost:8080
Step7: Want to add wildcards just add or want to skit just give enter
Step8: If you want to add additional arguments, you can add

Also, you can see the command line that is going to be executed
Step9: Just give Y to mirror the site
Step10: Go to the directory and find the mirror site

Congratulation… We have successfully mirrored the target.
Advertisement
Conclusion
This is an awesome tool and also there is another tool called webhttrack, The difference between webhttrack and httrack is web format and command-line interface.
Also Read: Dirbuster full tutorial
Also Read: Dirb full tutorial from noob to pro
Hello everyone today in this article we are going to discuss how we can install and use the HTTrack website copier tool
Website mirroring is the process of making a clone of the original website. This process is helpful in website footprinting by analyzing the cloned website on your local system.
There are many websites mirroring tools available in the market for paid and free. These tools include HTTrack Website Copier. HTTrack is an offline browser utility that downloads a website from the Internet to a local directory, builds all directories recursively, and transfers HTML, images, and other files from the web server to another computer.
Now we will use the HTTrack tool to make a clone of the target website and store it in our local system. We are targeting www.certifiedhacker.com as our target. This will help us in analyzing and identifying possible exploits and vulnerabilities.
How to download and Install
1. Let’s download the HTTrack tool from its official website [click here]

2. Click on the download link, and it will show you the best-recommended package according to your system

3. Download the Httrack package and install it as normally you install any applications.
Now open the application and follow these steps for cloning any website with the tool
Clone website with Httrack tool
1. First open the software then you’ll see the interface as in the figure

2. now click on the next button and create a project named your target website and then click next

3. now after clicking next now add the full URL of your target website in the add URL section

4. now click ok and then go on the set options button and then go to the scan rules tab and tick all the three boxes and for getting all the media files of the site correctly

5. now click on ok and then click next in the next section you need to tick an option [Disconnect when finished] and click on the finish button.

6. after clicking on the finish button all the required settings will be finished and the tool start to download your website on your local machine.

7. after finishing the download the tool will be disconnected from the site and shows the path to your local machine.

now you can explore the site and its loopholes and vulnerabilities in your local machine. it will save your bandwidth and request and response log in target website servers.