Последнее обновление: 20.02.2023
Конструкция switch-case позволяет сравнить некоторое выражение с набором значений. Она имеет следующую форму:
switch(выражение)
{
case значение_1: инструкции_1;
case значение_2: инструкции_2;
...................
case значение_N: инструкции_N;
default: инструкции;
}
После ключевого слова switch в скобках идет сравниваемое выражение. Значение этого выражения последовательно
сравнивается со значениями после оператора сase. И если совпадение будет найдено, то будет выполняться
определенный блок сase.
Стоит отметить, что сравниваемое выражение в switch должно представлять один из целочисленных или символьных типов или перечисление (рассматриваются далее).
В конце конструкции switch может стоять блок default. Он необязателен и выполняется в том случае, если значение после switch не соответствует ни одному из операторов case. Например:
#include <iostream>
int main()
{
int x {2};
switch(x)
{
case 1:
std::cout << "x = 1" << "\n";
break;
case 2:
std::cout << "x = 2" << "\n";
break;
case 3:
std::cout << "x = 3" << "\n";
break;
default:
std::cout << "x is undefined" << "\n";
break;
}
}
Чтобы избежать выполнения последующих блоков case/default, в конце каждого блока ставится оператор break. То есть
в данном случае будет выполняться оператор
case 2: std::cout << "x = 2" << "\n"; break;
После выполнения оператора break произойдет выход из конструкции switch..case, и остальные операторы case будут проигнорированы.
Поэтому на консоль будет выведена следующая строка
x = 2
Стоит отметить важность использования оператора break. Если мы его не укажем в блоке case, то после этого блока выполнение перейдет к следующему блоку case. Например,
уберем из предыдущего примера все операторы break:
#include <iostream>
int main()
{
int x {2};
switch(x)
{
case 1:
std::cout << "x = 1" << "\n";
case 2:
std::cout << "x = 2" << "\n";
case 3:
std::cout << "x = 3" << "\n";
default:
std::cout << "x is undefined" << "\n";
}
}
В этом случае опять же будет выполняться оператор case 2:, так как переменная x=2. Однако так как этот блок case не завершается
оператором break, то после его завершения будет выполняться набор инструкций после case 3: даже несмотря на то, что переменная x по прежнему равна 2.
В итоге мы получим следующий консольный вывод:
x = 2 x = 3 x is undefined
Совмещение условий
Можно определять для нескольких меток case один набор инструкций:
#include <iostream>
int main()
{
int x {2};
switch(x)
{
case 1:
case 2:
std::cout << "x = 1 or 2" << "\n";
break;
case 3:
case 4:
std::cout << "x = 3 or 4" << "\n";
break;
case 5:
std::cout << "x = 5" << "\n";
break;
}
}
Здесь если x=1 или x=2, то выполняется одна и та же инструкция std::cout << "x = 1 or 2" << "\n". Аналогично для вариантов
x=3 и x=4 также определена общая инструкция.
Переменные в блоках case
Определение переменных в блоках case, возможно, встречается нечасто. Однако может вызвать затруднения. Так, если переменная определяется в блоке case, то все инструкции
блока помещаются в фигурные скобки (для блока default это не требуется):
#include <iostream>
int main()
{
int x {2};
switch(x)
{
case 1:
{
int a{10};
std::cout << a << std::endl;
break;
}
case 2:
{
int b{20};
std::cout << b << std::endl;
break;
}
default:
int c{30};
std::cout << c << std::endl;
}
}
Блок switch с инициализацией переменной
Иногда в конструкции switch для различных промежуточных вычислений необходимо определить переменную. Для этой цели начиная со стандарта
C++17 язык С++ поддерживает особую форму конструкции switch:
switch(инициализация; выражение)
{
// ..........
}
Подобная форма также принимает выражение, значение которого сравнивается с константами после операторов case. Но теперь перед выражением еще может идти
определение и инициализация переменной. Например:
#include <iostream>
int main()
{
char op = '+';
int n = 10;
switch(int k{2}; op)
{
case '+':
std::cout << n + k << std::endl;
break;
case '-':
std::cout << n - k << std::endl;
break;
case '*':
std::cout << n * k << std::endl;
break;
}
}
В данном случае в конструкции switch определяется переменная k, которая доступна только в рамках этой конструкции switch. В качестве выражения
используется значение переменной op, которая представляет знак операции. И в зависимости от этого значения, выполняем определенную операцию с переменными n и k.
Пройдите тест, узнайте какой профессии подходите
Работать самостоятельно и не зависеть от других
Работать в команде и рассчитывать на помощь коллег
Организовывать и контролировать процесс работы
Быстрый ответ
Выражение CASE в SQL служит для реализации условной логики в запросах, что аналогично конструкции IF-ELSE в программировании. Применение выражения выглядит следующим образом:
Например, для категоризации возраста, запрос будет выглядеть так:
Данный запрос определяет каждый возраст как ‘Несовершеннолетний’ или ‘Взрослый’ и выводит результат в столбец ГруппаВозраста.

Основы CASE
Простой и поисковый: два типа CASE
В SQL существует два варианта выражений CASE — это простой CASE и поисковый CASE. Выбор между ними зависит от поставленной задачи:
- Простой CASE сравнивает единое выражение с несколькими конкретными значениями. Пример использования:
- Поисковый CASE применяется для проверки последовательности логических условий, например, при учете успеваемости студентов:
Обход проблемы NULL в ELSE
Если в выражении CASE отсутствует блок ELSE, то вернется NULL, если ни одно из условий WHEN не было выполнено. Чтобы избежать этого, можно задать значение по умолчанию через ELSE:
Также можно использовать функцию COALESCE для замены NULL на значение по умолчанию:
Практические советы при работе с CASE
- Порядок: Располагайте условия таким образом, чтобы самые вероятные варианты проверялись в первую очередь.
- Простота: Чем более простые условия, тем выше читаемость кода и удобнее его поддержка.
- Полное покрытие: Убедитесь, что ваша логика охватывает все возможные случаи.
CASE: Продвинутое использование
Условная агрегация в отчетах
Особо интересное применение выражение CASE находит при условной агрегации:
Вложенные CASE
Для сложных логических конструкций возможно применение вложенных выражений CASE:
CASE в операциях JOIN
Выражение CASE может быть использовано в условиях JOIN для создания динамических условий соединения таблиц:
Визуализация
Изобразить выражение CASE можно как перекресток с разными маршрутами:
- Каждый светофор — это
WHEN. THENзадаёт направление движения.ELSE— это альтернативный маршрут в случае, если условия не выполнились.
Таким образом, SQL-запрос умеет определить, что делать в зависимости от условий.
Полезные материалы
- CASE (Transact-SQL) – SQL Server | Microsoft Learn — официальная документация Microsoft по использованию CASE.
- SQL выражение CASE – W3Schools — обучающее пособие по SQL выражению CASE от W3 Schools.
- SQL CASE | Продвинутый SQL – Mode — инструкция по использованию CASE в SQL-запросах с примерами на практике.
- Выражения CASE – Официальная документация Oracle — подробное описание синтаксиса и использования CASE.
- PostgreSQL: Документация: 16: 9.18. Условные Выражения — официальная документация PostgreSQL о CASE и других условных выражениях.
Предыдущие части
- Часть первая — habrahabr.ru/post/255361
- Часть вторая — habrahabr.ru/post/255523
О чем будет рассказано в этой части
В этой части мы познакомимся:
- с выражением CASE, которое позволяет включить условные выражения в запрос;
- с агрегатными функциями, которые позволяют получить разного рода итоги (агрегированные значения) рассчитанные на основании детальных данных, полученных оператором «SELECT … WHERE …»;
- с предложением GROUP BY, которое в скупе с агрегатными функциями позволяет получить итоги по детальным данным в разрезе групп;
- с предложением HAVING, которое позволяет произвести фильтрацию по сгруппированным данным.
Выражение CASE – условный оператор языка SQL
Данный оператор позволяет осуществить проверку условий и возвратить в зависимости от выполнения того или иного условия тот или иной результат.
Оператор CASE имеет 2 формы:
| Первая форма: | Вторая форма: |
|---|---|
| CASE WHEN условие_1 THEN возвращаемое_значение_1 … WHEN условие_N THEN возвращаемое_значение_N [ELSE возвращаемое_значение] END |
CASE проверяемое_значение WHEN сравниваемое_значение_1 THEN возвращаемое_значение_1 … WHEN сравниваемое_значение_N THEN возвращаемое_значение_N [ELSE возвращаемое_значение] END |
В качестве значений здесь могут выступать и выражения.
Разберем на примере первую форму CASE:
SELECT
ID,Name,Salary,
CASE
WHEN Salary>=3000 THEN 'ЗП >= 3000'
WHEN Salary>=2000 THEN '2000 <= ЗП < 3000'
ELSE 'ЗП < 2000'
END SalaryTypeWithELSE,
CASE
WHEN Salary>=3000 THEN 'ЗП >= 3000'
WHEN Salary>=2000 THEN '2000 <= ЗП < 3000'
END SalaryTypeWithoutELSE
FROM Employees
| ID | Name | Salary | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | ЗП >= 3000 | ЗП >= 3000 |
| 1001 | Петров П.П. | 1500 | ЗП < 2000 | NULL |
| 1002 | Сидоров С.С. | 2500 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1003 | Андреев А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1004 | Николаев Н.Н. | 1500 | ЗП < 2000 | NULL |
| 1005 | Александров А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
WHEN-условия проверяются последовательно, сверху-вниз. При достижении первого удовлетворяющего условия дальнейшая проверка прерывается и возвращается значение, указанное после слова THEN, относящегося к данному блоку WHEN.
Если ни одно из WHEN-условий не выполняется, то возвращается значение, указанное после слова ELSE (что в данном случае означает «ИНАЧЕ ВЕРНИ …»).
Если ELSE-блок не указан и не выполняется ни одно WHEN-условие, то возвращается NULL.
И в первой, и во второй форме ELSE-блок идет в самом конце конструкции CASE, т.е. после всех WHEN-условий.
Разберем на примере вторую форму CASE:
Допустим, на новый год решили премировать всех сотрудников и попросили вычислить сумму бонусов по следующей схеме:
- Сотрудникам ИТ-отдела выдать по 15% от ЗП;
- Сотрудникам Бухгалтерии по 10% от ЗП;
- Всем остальным по 5% от ЗП.
Используем для данной задачи запрос с выражением CASE:
SELECT
ID,Name,Salary,DepartmentID,
-- для наглядности выведем процент в виде строки
CASE DepartmentID -- проверяемое значение
WHEN 2 THEN '10%' -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN '15%' -- 15% от ЗП выдать ИТ-шникам
ELSE '5%' -- всем остальным по 5%
END NewYearBonusPercent,
-- построим выражение с использованием CASE, чтобы увидеть сумму бонуса
Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount
FROM Employees
| ID | Name | Salary | DepartmentID | NewYearBonusPercent | BonusAmount |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 250 |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 225 |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 250 |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 300 |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 225 |
| 1005 | Александров А.А. | 2000 | NULL | 5% | 100 |
Здесь делается последовательная проверка значения DepartmentID с WHEN-значениями. При достижении первого равенства DepartmentID с WHEN-значением, проверка прерывается и возвращается значение, указанное после слова THEN, относящегося к данному блоку WHEN.
Соответственно, значение блока ELSE возвращается в случае, если DepartmentID не совпал ни с одним WHEN-значением.
Если блок ELSE отсутствует, то в случае несовпадения DepartmentID ни с одним WHEN-значением будет возвращено NULL.
Вторую форму CASE несложно представить при помощи первой формы:
SELECT
ID,Name,Salary,DepartmentID,
CASE
WHEN DepartmentID=2 THEN '10%' -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN '15%' -- 15% от ЗП выдать ИТ-шникам
ELSE '5%' -- всем остальным по 5%
END NewYearBonusPercent,
-- построим выражение с использованием CASE, чтобы увидеть сумму бонуса
Salary/100*
CASE
WHEN DepartmentID=2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount
FROM Employees
Так что, вторая форма – это всего лишь упрощенная запись для тех случаев, когда нам нужно сделать сравнение на равенство, одного и того же проверяемого значения с каждым WHEN-значением/выражением.
Примечание. Первая и вторая форма CASE входят в стандарт языка SQL, поэтому скорее всего они должны быть применимы во многих СУБД.
С MS SQL версии 2012 появилась упрощенная форма записи IIF. Она может использоваться для упрощенной записи конструкции CASE, в том случае если возвращаются только 2 значения. Конструкция IIF имеет следующий вид:
IIF(условие, true_значение, false_значение)
Т.е. по сути это обертка для следующей CASE конструкции:
CASE WHEN условие THEN true_значение ELSE false_значение END
Посмотрим на примере:
SELECT
ID,Name,Salary,
IIF(Salary>=2500,'ЗП >= 2500','ЗП < 2500') DemoIIF,
CASE WHEN Salary>=2500 THEN 'ЗП >= 2500' ELSE 'ЗП < 2500' END DemoCASE
FROM Employees
Конструкции CASE, IIF могут быть вложенными друг в друга. Рассмотрим абстрактный пример:
SELECT
ID,Name,Salary,
CASE
WHEN DepartmentID IN(1,2) THEN 'A'
WHEN DepartmentID=3 THEN
CASE PositionID -- вложенный CASE
WHEN 3 THEN 'B-1'
WHEN 4 THEN 'B-2'
END
ELSE 'C'
END Demo1,
IIF(DepartmentID IN(1,2),'A',
IIF(DepartmentID=3,CASE PositionID WHEN 3 THEN 'B-1' WHEN 4 THEN 'B-2' END,'C')) Demo2
FROM Employees
Так как конструкция CASE и IIF представляют из себя выражение, которые возвращают результат, то мы можем использовать их не только в блоке SELECT, но и в остальных блоках, допускающих использование выражений, например, в блоках WHERE или ORDER BY.
Для примера, пускай перед нами поставили задачу – создать список на выдачу ЗП на руки, следующим образом:
- Первым делом ЗП должны получить сотрудники у кого оклад меньше 2500
- Те сотрудники у кого оклад больше или равен 2500, получают ЗП во вторую очередь
- Внутри этих двух групп нужно упорядочить строки по ФИО (поле Name)
Попробуем решить эту задачу при помощи добавления CASE-выражение в блок ORDER BY:
SELECT
ID,Name,Salary
FROM Employees
ORDER BY
CASE WHEN Salary>=2500 THEN 1 ELSE 0 END, -- выдать ЗП сначала тем у кого она ниже 2500
Name -- дальше упорядочить список в порядке ФИО
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1000 | Иванов И.И. | 5000 |
| 1002 | Сидоров С.С. | 2500 |
Как видим, Иванов и Сидоров уйдут с работы последними.
И абстрактный пример использования CASE в блоке WHERE:
SELECT
ID,Name,Salary
FROM Employees
WHERE CASE WHEN Salary>=2500 THEN 1 ELSE 0 END=1 -- все записи у которых выражение равно 1
Можете попытаться самостоятельно переделать 2 последних примера с функцией IIF.
И напоследок, вспомним еще раз о NULL-значениях:
SELECT
ID,Name,Salary,DepartmentID,
CASE
WHEN DepartmentID=2 THEN '10%' -- 10% от ЗП выдать Бухгалтерам
WHEN DepartmentID=3 THEN '15%' -- 15% от ЗП выдать ИТ-шникам
WHEN DepartmentID IS NULL THEN '-' -- внештатникам бонусов не даем (используем IS NULL)
ELSE '5%' -- всем остальным по 5%
END NewYearBonusPercent1,
-- а так проверять на NULL нельзя, вспоминаем что говорилось про NULL во второй части
CASE DepartmentID -- проверяемое значение
WHEN 2 THEN '10%'
WHEN 3 THEN '15%'
WHEN NULL THEN '-' -- !!! в данном случае использование второй формы CASE не подходит
ELSE '5%'
END NewYearBonusPercent2
FROM Employees
| ID | Name | Salary | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 5% |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 15% |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 10% |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 15% |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 15% |
| 1005 | Александров А.А. | 2000 | NULL | — | 5% |
Конечно можно было переписать и как-то так:
SELECT
ID,Name,Salary,DepartmentID,
CASE ISNULL(DepartmentID,-1) -- используем замену в случае NULL на -1
WHEN 2 THEN '10%'
WHEN 3 THEN '15%'
WHEN -1 THEN '-' -- если мы уверены, что отдела с ID равным (-1) нет и не будет
ELSE '5%'
END NewYearBonusPercent3
FROM Employees
В общем, полет фантазии в данном случае не ограничен.
Для примера посмотрим, как при помощи CASE и IIF можно смоделировать функцию ISNULL:
SELECT
ID,Name,LastName,
ISNULL(LastName,'Не указано') DemoISNULL,
CASE WHEN LastName IS NULL THEN 'Не указано' ELSE LastName END DemoCASE,
IIF(LastName IS NULL,'Не указано',LastName) DemoIIF
FROM Employees
Конструкция CASE очень мощное средство языка SQL, которое позволяет наложить дополнительную логику для расчета значений результирующего набора. В данной части владение CASE-конструкцией нам еще пригодится, поэтому в этой части в первую очередь внимание уделено именно ей.
Агрегатные функции
Здесь мы рассмотрим только основные и наиболее часто используемые агрегатные функции:
| Название | Описание |
|---|---|
| COUNT(*) | Возвращает количество строк полученных оператором «SELECT … WHERE …». В случае отсутствии WHERE, количество всех записей таблицы. |
| COUNT(столбец/выражение) | Возвращает количество значений (не равных NULL), в указанном столбце/выражении |
| COUNT(DISTINCT столбец/выражение) | Возвращает количество уникальных значений, не равных NULL в указанном столбце/выражении |
| SUM(столбец/выражение) | Возвращает сумму по значениям столбца/выражения |
| AVG(столбец/выражение) | Возвращает среднее значение по значениям столбца/выражения. NULL значения для подсчета не учитываются. |
| MIN(столбец/выражение) | Возвращает минимальное значение по значениям столбца/выражения |
| MAX(столбец/выражение) | Возвращает максимальное значение по значениям столбца/выражения |
Агрегатные функции позволяют нам сделать расчет итогового значения для набора строк полученных при помощи оператора SELECT.
Рассмотрим каждую функцию на примере:
SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
| Общее кол-во сотрудников | Число уникальных отделов | Число уникальных должностей | Кол-во сотрудников у которых указан % бонуса | Максимальный процент бонуса | Минимальный процент бонуса | Сумма всех бонусов | Средний размер бонуса | Средний размер ЗП |
|---|---|---|---|---|---|---|---|---|
| 6 | 3 | 4 | 3 | 50 | 15 | 3325 | 1108.33333333333 | 2416.66666666667 |
Для большей наглядности я решил здесь сделать исключение и воспользовался синтаксисом […] для задания псевдонимов колонок.
Разберем каким образом получилось каждое возвращенное значение, а за одно вспомним конструкции базового синтаксиса оператора SELECT.
Во-первых, т.к. мы в запросе не указали WHERE-условия, то итоги будут считаться для детальных данных, которые получаются запросом:
SELECT * FROM Employees
т.е. для всех строк таблицы Employees.
Для наглядности выберем только поля и выражения, которые используются в агрегатных функциях:
SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent [Salary/100*BonusPercent],
Salary
FROM Employees
| DepartmentID | PositionID | BonusPercent | Salary/100*BonusPercent | Salary |
|---|---|---|---|---|
| 1 | 2 | 50 | 2500 | 5000 |
| 3 | 3 | 15 | 225 | 1500 |
| 2 | 1 | NULL | NULL | 2500 |
| 3 | 4 | 30 | 600 | 2000 |
| 3 | 3 | NULL | NULL | 1500 |
| NULL | NULL | NULL | NULL | 2000 |
Это исходные данные (детальные строки), по которым и будут считаться итоги агрегированного запроса.
Теперь разберем каждое агрегированное значение:
COUNT(*) – т.к. мы не задали в запросе условия фильтрации в блоке WHERE, то COUNT(*) дало нам общее количество записей в таблице, т.е. это количество строк, которое возвращает запрос:

|
| COUNT(DISTINCT DepartmentID) – вернуло нам значение 3, т.е. это число соответствует числу уникальных значений департаментов указанных в столбце DepartmentID без учета NULL значений. Пройдемся по значениям колонки DepartmentID и раскрасим одинаковые значения в один цвет (не стесняйтесь, для обучения все методы хороши):
Отбрасываем NULL, после чего, мы получили 3 уникальных значения (1, 2 и 3). Т.е. значение получаемое COUNT(DISTINCT DepartmentID), в развернутом виде можно представить следующей выборкой: 
|
COUNT(DISTINCT PositionID) – то же самое, что было сказано про COUNT(DISTINCT DepartmentID), только полю PositionID. Смотрим на значения колонки PositionID и не жалеем красок:

|
| COUNT(BonusPercent) – возвращает количество строк, у которых указано значение BonusPercent, т.е. подсчитывается количество записей, у которых BonusPercent IS NOT NULL. Здесь нам будет проще, т.к. не нужно считать уникальные значения, достаточно просто отбросить записи с NULL значениями. Берем значения колонки BonusPercent и вычеркиваем все NULL значения:
Остается 3 значения. Т.е. в развернутом виде выборку можно представить так: 
Т.к. мы не использовали слова DISTINCT, то посчитаются и повторяющиеся BonusPercent в случае их наличия, без учета BonusPercent равных NULL. Для примера давайте сделаем сравнение результата с использованием DISTINCT и без него. Для большей наглядности воспользуемся значениями поля DepartmentID: 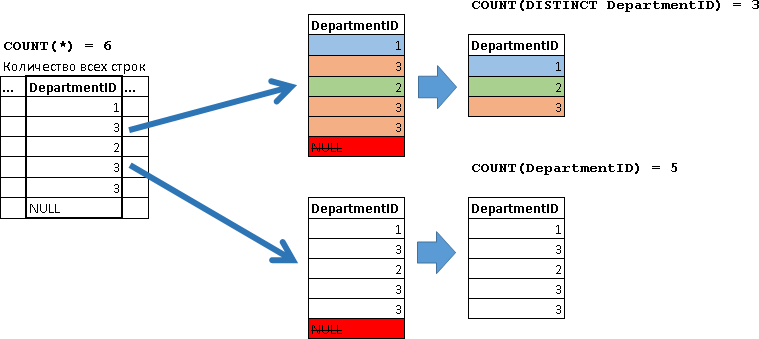
|
| MAX(BonusPercent) – возвращает максимальное значение BonusPercent, опять же без учета NULL значений. Берем значения колонки BonusPercent и ищем среди них максимальное значение, на NULL значения не обращаем внимания: Т.е. мы получаем следующее значение:
|
| MIN(BonusPercent) – возвращает минимальное значение BonusPercent, опять же без учета NULL значений. Как в случае с MAX, только ищем минимальное значение, игнорируя NULL:
Т.е. мы получаем следующее значение: Наглядное представление MIN(BonusPercent) и MAX(BonusPercent): 
|
| SUM(Salary/100*BonusPercent) – возвращает сумму всех не NULL значений. Разбираем значения выражения (Salary/100*BonusPercent):
Т.е. происходит суммирование следующих значений: 
|
AVG(Salary/100*BonusPercent) – возвращает среднее значений. NULL-выражения не учитываются, т.е. это соответствует второму выражению:
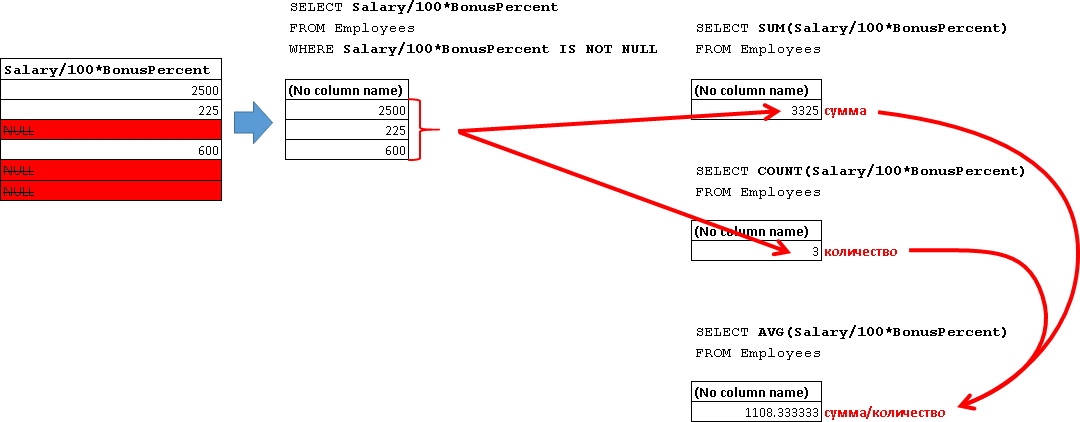
Т.е. опять же NULL-значения не учитываются при подсчете количества. Если же вам необходимо вычислить среднее по всем сотрудникам, как в третьем выражении, которое дает 554.166666666667, то используйте предварительное преобразование NULL значений в ноль:
|
| AVG(Salary) – собственно, здесь все то же самое что и в предыдущем случае, т.е. если у сотрудника Salary равен NULL, то он не учтется. Чтобы учесть всех сотрудников, соответственно делаете предварительное преобразование NULL значений AVG(ISNULL(Salary,0)) |
Подведем некоторые итоги:
- COUNT(*) – служит для подсчета общего количества строк, которые получены оператором «SELECT … WHERE …»
- во всех остальных вышеперечисленных агрегатных функциях при расчете итога, NULL-значения не учитываются
- если нам нужно учесть все строки, это больше актуально для функции AVG, то предварительно необходимо осуществить обработку NULL значений, например, как было показано выше «AVG(ISNULL(Salary,0))»
Соответственно при задании с агрегатными функциями дополнительного условия в блоке WHERE, будут подсчитаны только итоги, по строкам удовлетворяющих условию. Т.е. расчет агрегатных значений происходит для итогового набора, который получен при помощи конструкции SELECT. Например, сделаем все тоже самое, но только в разрезе ИТ-отдела:
SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
| Общее кол-во сотрудников | Число уникальных отделов | Число уникальных должностей | Кол-во сотрудников у которых указан % бонуса | Максимальный процент бонуса | Минимальный процент бонуса | Сумма всех бонусов | Средний размер бонуса | Средний размер ЗП |
|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 2 | 2 | 30 | 15 | 825 | 412.5 | 1666.66666666667 |
Предлагаю вам, для большего понимания работы агрегатных функций, самостоятельно проанализировать каждое полученное значение. Расчеты здесь ведем, соответственно, по детальным данным полученным запросом:
SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent [Salary/100*BonusPercent],
Salary
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
| DepartmentID | PositionID | BonusPercent | Salary/100*BonusPercent | Salary |
|---|---|---|---|---|
| 3 | 3 | 15 | 225 | 1500 |
| 3 | 4 | 30 | 600 | 2000 |
| 3 | 3 | NULL | NULL | 1500 |
Идем, дальше. В случае, если агрегатная функция возвращает NULL (например, у всех сотрудников не указано значение Salary), или в выборку не попало ни одной записи, а в отчете, для такого случая нам нужно показать 0, то функцией ISNULL можно обернуть агрегатное выражение:
SELECT
SUM(Salary),
AVG(Salary),
-- обрабатываем итог при помощи ISNULL
ISNULL(SUM(Salary),0),
ISNULL(AVG(Salary),0)
FROM Employees
WHERE DepartmentID=10 -- здесь специально указан несуществующий отдел, чтобы запрос не вернул записей
| (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|
| NULL | NULL | 0 | 0 |
Я считаю, что очень важно понимать назначение каждой агрегатной функции и то каким образом они производят расчет, т.к. в SQL это главный инструмент, который служит для расчета итоговых значений.
В данном случае мы рассмотрели, как каждая агрегатная функция ведет себя самостоятельно, т.е. она применялась к значениям всего набора записей полученным командой SELECT. Дальше мы рассмотрим, как эти же функции применяются для вычисления итогов по группам, при помощи конструкции GROUP BY.
GROUP BY – группировка данных
До этого мы уже вычисляли итоги для конкретного отдела, примерно следующим образом:
SELECT
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные только по ИТ отделу
А теперь представьте, что нас попросили получить такие же цифры в разрезе каждого отдела. Конечно мы можем засучить рукава и выполнить этот же запрос для каждого отдела. Итак, сказано-сделано, пишем 4 запроса:
SELECT
'Администрация' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 -- данные по Администрации
SELECT
'Бухгалтерия' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 -- данные по Бухгалтерии
SELECT
'ИТ' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные по ИТ отделу
SELECT
'Прочие' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам
В результате мы получим 4 набора данных:
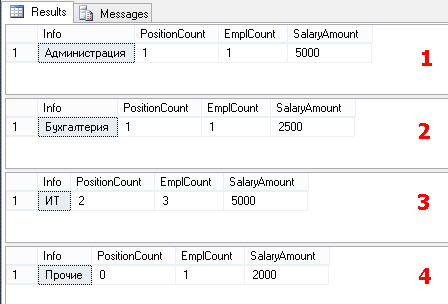
Обратите внимание, что мы можем использовать поля, заданные в виде констант – ‘Администрация’, ‘Бухгалтерия’, …
В общем все цифры, о которых нас просили, мы добыли, объединяем все в Excel и отдаем директору.
Отчет директору понравился, и он говорит: «а добавьте еще колонку с информацией по среднему окладу». И как всегда это нужно сделать очень срочно.
Мда, что делать?! Вдобавок представим еще что отделов у нас не 3, а 15.
Вот как раз то примерно для таких случаев служит конструкция GROUP BY:
SELECT
DepartmentID,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
| DepartmentID | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 0 | 1 | 2000 | 2000 |
| 1 | 1 | 1 | 5000 | 5000 |
| 2 | 1 | 1 | 2500 | 2500 |
| 3 | 2 | 3 | 5000 | 1666.66666666667 |
Мы получили все те же самые данные, но теперь используя только один запрос!
Пока не обращайте внимание, на то что департаменты у нас вывелись в виде цифр, дальше мы научимся выводить все красиво.
В предложении GROUP BY можно указывать несколько полей «GROUP BY поле1, поле2, …, полеN», в этом случае группировка произойдет по группам, которые образовывают значения данных полей «поле1, поле2, …, полеN».
Для примера, сделаем группировку данных в разрезе Отделов и Должностей:
SELECT
DepartmentID,PositionID,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID,PositionID
| DepartmentID | PositionID | EmplCount | SalaryAmount |
|---|---|---|---|
| NULL | NULL | 1 | 2000 |
| 2 | 1 | 1 | 2500 |
| 1 | 2 | 1 | 5000 |
| 3 | 3 | 2 | 3000 |
| 3 | 4 | 1 | 2000 |
Давайте, теперь на этом примере, попробуем разобраться как работает GROUP BY
Для полей, перечисленных после GROUP BY из таблицы Employees определяются все уникальные комбинации по значениям DepartmentID и PositionID, т.е. происходит примерно следующее:
SELECT DISTINCT DepartmentID,PositionID
FROM Employees
| DepartmentID | PositionID |
|---|---|
| NULL | NULL |
| 1 | 2 |
| 2 | 1 |
| 3 | 3 |
| 3 | 4 |
После чего делается пробежка по каждой комбинации и делаются вычисления агрегатных функций:
SELECT
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL AND PositionID IS NULL
SELECT
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 AND PositionID=2
-- ...
SELECT
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 AND PositionID=4
А потом все эти результаты объединяются вместе и отдаются нам в виде одного набора:
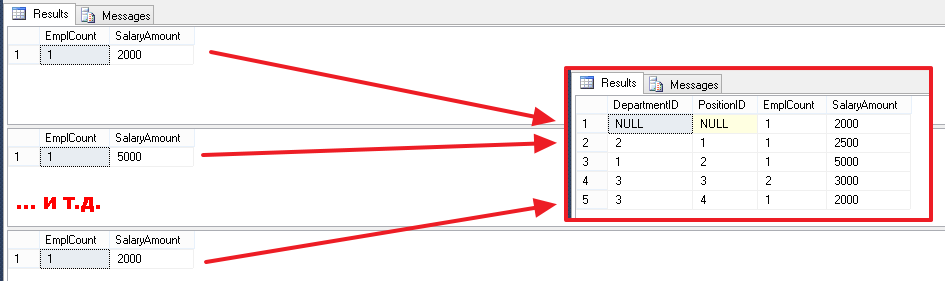
Из основного, стоит отметить, что в случае группировки (GROUP BY), в перечне колонок в блоке SELECT:
- Мы можем использовать только колонки, перечисленные в блоке GROUP BY
- Можно использовать выражения с полями из блока GROUP BY
- Можно использовать константы, т.к. они не влияют на результат группировки
- Все остальные поля (не перечисленные в блоке GROUP BY) можно использовать только с агрегатными функциями (COUNT, SUM, MIN, MAX, …)
- Не обязательно перечислять все колонки из блока GROUP BY в списке колонок SELECT
И демонстрация всего сказанного:
SELECT
'Строка константа' Const1, -- константа в виде строки
1 Const2, -- константа в виде числа
-- выражение с использованием полей участвуещих в группировке
CONCAT('Отдел № ',DepartmentID) ConstAndGroupField,
CONCAT('Отдел № ',DepartmentID,', Должность № ',PositionID) ConstAndGroupFields,
DepartmentID, -- поле из списка полей участвующих в группировке
-- PositionID, -- поле учавствующее в группировке, не обязательно дублировать здесь
COUNT(*) EmplCount, -- кол-во строк в каждой группе
-- остальные поля можно использовать только с агрегатными функциями: COUNT, SUM, MIN, MAX, …
SUM(Salary) SalaryAmount,
MIN(ID) MinID
FROM Employees
GROUP BY DepartmentID,PositionID -- группировка по полям DepartmentID,PositionID
| Const1 | Const2 | ConstAndGroupField | ConstAndGroupFields | DepartmentID | EmplCount | SalaryAmount | MinID |
|---|---|---|---|---|---|---|---|
| Строка константа | 1 | Отдел № | Отдел №, Должность № | NULL | 1 | 2000 | 1005 |
| Строка константа | 1 | Отдел № 2 | Отдел № 2, Должность № 1 | 2 | 1 | 2500 | 1002 |
| Строка константа | 1 | Отдел № 1 | Отдел № 1, Должность № 2 | 1 | 1 | 5000 | 1000 |
| Строка константа | 1 | Отдел № 3 | Отдел № 3, Должность № 3 | 3 | 2 | 3000 | 1001 |
| Строка константа | 1 | Отдел № 3 | Отдел № 3, Должность № 4 | 3 | 1 | 2000 | 1003 |
Так же стоит отметить, что группировку можно делать не только по полям, но также и по выражениям. Для примера сгруппируем данные по сотрудникам, по годам рождения:
SELECT
CONCAT('Год рождения - ',YEAR(Birthday)) YearOfBirthday,
COUNT(*) EmplCount
FROM Employees
GROUP BY YEAR(Birthday)
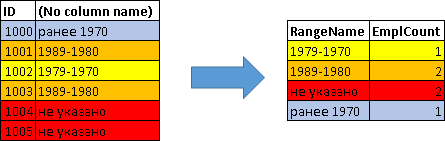
Рассмотрим пример с более сложным выражением. Для примера, получим градацию сотрудников по годам рождения:
SELECT
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END RangeName,
COUNT(*) EmplCount
FROM Employees
GROUP BY
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END
| RangeName | EmplCount |
|---|---|
| 1979-1970 | 1 |
| 1989-1980 | 2 |
| не указано | 2 |
| ранее 1970 | 1 |
Т.е. в данном случае группировка делается по предварительно вычисленному для каждого сотрудника CASE-выражению:
SELECT
ID,
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END
FROM Employees
Ну и конечно же вы можете объединять в блоке GROUP BY выражения с полями:
SELECT
DepartmentID,
CONCAT('Год рождения - ',YEAR(Birthday)) YearOfBirthday,
COUNT(*) EmplCount
FROM Employees
GROUP BY YEAR(Birthday),DepartmentID -- порядок может не совпадать с порядком их использования в блоке SELECT
ORDER BY DepartmentID,YearOfBirthday -- напоследок мы можем применить к результату сортировку
Вернемся к нашей изначальной задаче. Как мы уже знаем, отчет очень понравился директору, и он попросил нас делать его еженедельно, дабы он мог мониторить изменения по компании. Чтобы, не перебивать каждый раз в Excel цифровое значение отдела на его наименование, воспользуемся знаниями, которые у нас уже есть, и усовершенствуем наш запрос:
SELECT
CASE DepartmentID
WHEN 1 THEN 'Администрация'
WHEN 2 THEN 'Бухгалтерия'
WHEN 3 THEN 'ИТ'
ELSE 'Прочие'
END Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
ORDER BY Info -- добавим для большего удобства сортировку по колонке Info
| Info | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
| Прочие | 0 | 1 | 2000 | 2000 |
Хоть со стороны может выглядит и страшно, но все равно это получше чем было изначально. Недостаток в том, что если заведут новый отдел и его сотрудников, то выражение CASE нам нужно будет дописывать, дабы сотрудники нового отдела не попали в группу «Прочие».
Но ничего, со временем, мы научимся делать все красиво, чтобы выборка у нас не зависела от появления в БД новых данных, а была динамической. Немного забегу вперед, чтобы показать к написанию каких запросов мы стремимся прийти:
SELECT
ISNULL(dep.Name,'Прочие') DepName,
COUNT(DISTINCT emp.PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(emp.Salary) SalaryAmount,
AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
GROUP BY emp.DepartmentID,dep.Name
ORDER BY DepName
В общем, не переживайте – все начинали с простого. Пока вам просто нужно понять суть конструкции GROUP BY.
Напоследок, давайте посмотрим каким образом можно строить сводные отчеты при помощи GROUP BY.
Для примера выведем сводную таблицу, в разрезе отделов, так чтобы была подсчитана суммарная заработная плата, получаемая сотрудниками в разбивке по должностям:
SELECT
DepartmentID,
SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера],
SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора],
SUM(CASE WHEN PositionID=3 THEN Salary END) [Программисты],
SUM(CASE WHEN PositionID=4 THEN Salary END) [Старшие программисты],
SUM(Salary) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| NULL | NULL | NULL | NULL | NULL | 2000 |
| 1 | NULL | 5000 | NULL | NULL | 5000 |
| 2 | 2500 | NULL | NULL | NULL | 2500 |
| 3 | NULL | NULL | 3000 | 2000 | 5000 |
Т.е. мы свободно можем использовать любые выражения внутри агрегатных функций.
Можно конечно переписать и при помощи IIF:
SELECT
DepartmentID,
SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера],
SUM(IIF(PositionID=2,Salary,NULL)) [Директора],
SUM(IIF(PositionID=3,Salary,NULL)) [Программисты],
SUM(IIF(PositionID=4,Salary,NULL)) [Старшие программисты],
SUM(Salary) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
Но в случае с IIF нам придется явно указывать NULL, которое возвращается в случае невыполнения условия.
В аналогичных случаях мне больше нравится использовать CASE без блока ELSE, чем лишний раз писать NULL. Но это конечно дело вкуса, о котором не спорят.
И давайте вспомним, что в агрегатных функциях при агрегации не учитываются NULL значения.
Для закрепления, сделайте самостоятельный анализ полученных данных по развернутому запросу:
SELECT
DepartmentID,
CASE WHEN PositionID=1 THEN Salary END [Бухгалтера],
CASE WHEN PositionID=2 THEN Salary END [Директора],
CASE WHEN PositionID=3 THEN Salary END [Программисты],
CASE WHEN PositionID=4 THEN Salary END [Старшие программисты],
Salary [Итого по отделу]
FROM Employees
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| 1 | NULL | 5000 | NULL | NULL | 5000 |
| 3 | NULL | NULL | 1500 | NULL | 1500 |
| 2 | 2500 | NULL | NULL | NULL | 2500 |
| 3 | NULL | NULL | NULL | 2000 | 2000 |
| 3 | NULL | NULL | 1500 | NULL | 1500 |
| NULL | NULL | NULL | NULL | NULL | 2000 |
И еще давайте вспомним, что если вместо NULL мы хотим увидеть нули, то мы можем обработать значение, возвращаемое агрегатной функцией. Например:
SELECT
DepartmentID,
ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера],
ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора],
ISNULL(SUM(IIF(PositionID=3,Salary,NULL)),0) [Программисты],
ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старшие программисты],
ISNULL(SUM(Salary),0) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| NULL | 0 | 0 | 0 | 0 | 2000 |
| 1 | 0 | 5000 | 0 | 0 | 5000 |
| 2 | 2500 | 0 | 0 | 0 | 2500 |
| 3 | 0 | 0 | 3000 | 2000 | 5000 |
Теперь в целях практики, вы можете:
- вывести названия департаментов вместо их идентификаторов, например, добавив выражение CASE обрабатывающее DepartmentID в блоке SELECT
- добавьте сортировку по имени отдела при помощи ORDER BY
GROUP BY в скупе с агрегатными функциями, одно из основных средств, служащих для получения сводных данных из БД, ведь обычно данные в таком виде и используются, т.к. обычно от нас требуют предоставления сводных отчетов, а не детальных данных (простыней). И конечно же все это крутится вокруг знания базовой конструкции, т.к. прежде чем что-то подытожить (агрегировать), вам нужно первым делом это правильно выбрать, используя «SELECT … WHERE …».
Важное место здесь имеет практика, поэтому, если вы поставили целью понять язык SQL, не изучить, а именно понять – практикуйтесь, практикуйтесь и практикуйтесь, перебирая самые разные варианты, которые только сможете придумать.
На начальных порах, если вы не уверены в правильности полученных агрегированных данных, делайте детальную выборку, включающую все значения, по которым идет агрегация. И проверяйте правильность расчетов вручную по этим детальным данным. В этом случае очень сильно может помочь использование программы Excel.
Допустим, что вы дошли до этого момента
Допустим, что вы бухгалтер Сидоров С.С., который решил научиться писать SELECT-запросы.
Допустим, что вы уже успели дочитать данный учебник до этого момента, и уже уверено пользуетесь всеми вышеперечисленными базовыми конструкциями, т.е. вы умеете:
- Выбирать детальные данные по условию WHERE из одной таблицы
- Умеете пользоваться агрегатными функциями и группировкой из одной таблицы
Так как на работе посчитали, что вы уже все умеете, то вам предоставили доступ к БД (и такое порой бывает), и теперь вы разработали и вытаскиваете тот самый еженедельный отчет для директора.
Да, но они не учли, что вы пока не умеете строить запросы из нескольких таблиц, а только из одной, т.е. вы не умеете делать что-то вроде такого:
SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
Несмотря на то, что вы этого не умеете, поверьте, вы молодец, и уже, и так много достигли.
И так, как же можно воспользоваться вашими текущими знаниями и получить при этом еще более продуктивные результаты?! Воспользуемся силой коллективного разума – идем к программистам, которые работают у вас, т.е. к Андрееву А.А., Петрову П.П. или Николаеву Н.Н., и попросим кого-нибудь из них написать для вас представление (VIEW или просто «Вьюха», так они даже, думаю, быстрее поймут вас), которое помимо основных полей из таблицы Employees, будет еще возвращать поля с «Названием отдела» и «Названием должности», которых вам так недостает сейчас для еженедельного отчета, которым вас загрузил Иванов И.И.
Т.к. вы все грамотно объяснили, то ИТ-шники, сразу же поняли, что от них хотят и создали, специально для вас, представление с названием ViewEmployeesInfo.
Представляем, что вы следующей команды не видите, т.к. это делают ИТ-шники:
CREATE VIEW ViewEmployeesInfo
AS
SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
Т.е. для вас весь этот, пока страшный и непонятный, текст остается за кадром, а ИТ-шники дают вам только название представления «ViewEmployeesInfo», которое возвращает все вышеуказанные данные (т.е. то что вы у них просили).
Вы теперь можете работать с данным представлением, как с обычной таблицей:
SELECT *
FROM ViewEmployeesInfo
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
Т.к. теперь все необходимые для отчета данные есть в одной «таблице» (а-ля вьюха), то вы с легкостью сможете переделать свой еженедельный отчет:
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM ViewEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
| DepartmentName | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 0 | 1 | 2000 | 2000 |
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
Теперь все названия отделов на местах, плюс к тому же запрос стал динамическим, и будет изменяться при добавлении новых отделов и их сотрудников, т.е. вам теперь ничего переделывать не нужно, а достаточно раз в неделю выполнить запрос и отдать его результат директору.
Т.е. для вас в данном случае, будто бы ничего и не поменялось, вы продолжаете так же работать с одной таблицей (только уже правильнее сказать с представлением ViewEmployeesInfo), которое возвращает все необходимые вам данные. Благодаря помощи ИТ-шников, детали по добыванию DepartmentName и PositionName остались для вас в черном ящике. Т.е. представление для вас выглядит так же, как и обычная таблица, считайте, что это расширенная версия таблицы Employees.
Давайте для примера еще сформируем ведомость, чтобы вы убедились, что все действительно так как я и говорил (что вся выборка идет из одного представления):
SELECT
ID,
Name,
Salary
FROM ViewEmployeesInfo
WHERE Salary IS NOT NULL
AND Salary>0
ORDER BY Name
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1000 | Иванов И.И. | 5000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1002 | Сидоров С.С. | 2500 |
Надеюсь, что данный запрос вам понятен.
Использование представлений в некоторых случаях, дает возможность значительно расширить границы пользователей, владеющих написанием базовых SELECT-запросов. В данном случае представление, представляет собой плоскую таблицу со всеми необходимыми пользователю данными (для тех, кто разбирается в OLAP, это можно сравнить с приближенным подобием OLAP-куба с фактами и измерениями).
Вырезка с википедии. Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста.
Как видите, уважаемые пользователи, язык SQL изначально задумывался, как инструмент для вас. Так что, все в ваших руках и желании, не отпускайте руки.
HAVING – наложение условия выборки к сгруппированным данным
Собственно, если вы поняли, что такое группировка, то с HAVING ничего сложного нет. HAVING – чем-то подобен WHERE, только если WHERE-условие применяется к детальным данным, то HAVING-условие применяется к уже сгруппированным данным. По этой причине в условиях блока HAVING мы можем использовать либо выражения с полями, входящими в группировку, либо выражения, заключенные в агрегатные функции.
Рассмотрим пример:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
| DepartmentID | SalaryAmount |
|---|---|
| 1 | 5000 |
| 3 | 5000 |
Т.е. данный запрос вернул нам сгруппированные данные только по тем отделам, у которых сумма ЗП всех сотрудников превышает 3000, т.е. «SUM(Salary)>3000».
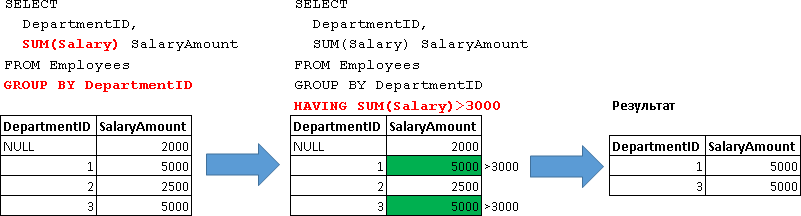
Т.е. здесь в первую очередь происходит группировка и вычисляются данные по всем отделам:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам
А уже к этим данным применяется условие указанно в блоке HAVING:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам
HAVING SUM(Salary)>3000 -- 2. условие для фильтрации сгруппированных данных
В HAVING-условии так же можно строить сложные условия используя операторы AND, OR и NOT:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
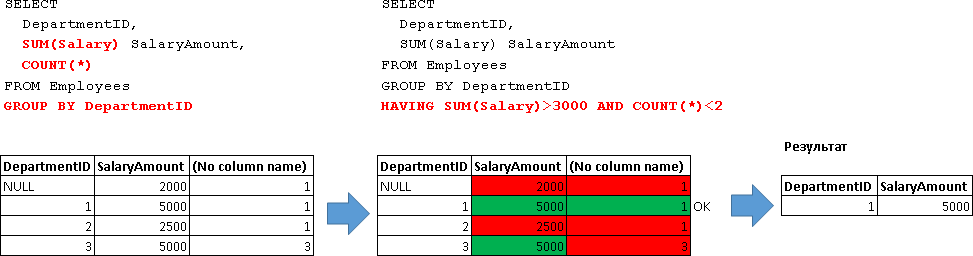
Как можно здесь заметить агрегатная функция (см. «COUNT(*)») может быть указана только в блоке HAVING.
Соответственно мы можем отобразить только номер отдела, подпадающего под HAVING-условие:
SELECT
DepartmentID
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Пример использования HAVING-условия по полю включенного в GROUP BY:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID -- 1. сделать группировку
HAVING DepartmentID=3 -- 2. наложить фильтр на результат группировки
Это только пример, т.к. в данном случае проверку логичнее было бы сделать через WHERE-условие:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- 1. провести фильтрацию детальных данных
GROUP BY DepartmentID -- 2. сделать группировку только по отобранным записям
Т.е. сначала отфильтровать сотрудников по отделу 3, и только потом сделать расчет.
Примечание. На самом деле, несмотря на то, что эти два запроса выглядят по-разному оптимизатор СУБД может выполнить их одинаково.
Думаю, на этом рассказ о HAVING-условиях можно окончить.
Подведем итоги
Сведем данные полученные во второй и третьей части и рассмотрим конкретное месторасположение каждой изученной нами конструкции и укажем порядок их выполнения:
| Конструкция/Блок | Порядок выполнения | Выполняемая функция |
|---|---|---|
| SELECT возвращаемые выражения | 4 | Возврат данных полученных запросом |
| FROM источник | 0 | В нашем случае это пока все строки таблицы |
| WHERE условие выборки из источника | 1 | Отбираются только строки, проходящие по условию |
| GROUP BY выражения группировки | 2 | Создание групп по указанному выражению группировки. Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках |
| HAVING фильтр по сгруппированным данным | 3 | Фильтрация, накладываемая на сгруппированные данные |
| ORDER BY выражение сортировки результата | 5 | Сортировка данных по указанному выражению |
Конечно же, вы так же можете применить к сгруппированным данным предложения DISTINCT и TOP, изученные во второй части.
Эти предложения в данном случае применятся к окончательному результату:
SELECT
TOP 1 -- 6. применится в последнюю очередь
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
ORDER BY DepartmentID -- 5. сортировка результата
| SalaryAmount |
|---|
| 5000 |
SELECT
DISTINCT -- показать только уникальные значения SalaryAmount
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
| SalaryAmount |
|---|
| 2000 |
| 2500 |
| 5000 |
Как получились данные результаты проанализируйте самостоятельно.
Заключение
Основная цель которую я ставил в данной части – раскрыть для вас суть агрегатных функций и группировок.
Если базовая конструкция позволяла нам получить необходимые детальные данные, то применение агрегатных функций и группировок к этим детальным данным, дало нам возможность получить по ним сводные данные. Так что, как видите здесь все важно, т.к. одно опирается на другое – без знания базовой конструкции мы не сможем, например, правильно отобрать данные, по которым нам нужно просчитать итоги.
Здесь я намеренно стараюсь показывать только основы, чтобы сосредоточить внимание начинающих на самых главных конструкциях и не перегружать их лишней информацией. Твердое понимание основных конструкций (о которых я еще продолжу рассказ в последующих частях) даст вам возможность решить практически любую задачу по выборке данных из РБД. Основные конструкции оператора SELECT применимы в таком же виде практически во всех СУБД (отличия в основном состоят в деталях, например, в реализации функций – для работы со строками, временем, и т.д.).
В последующем, твердое знание базы даст вам возможность самостоятельно легко изучить разные расширения языка SQL, такие как:
- GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), …
- PIVOT, UNPIVOT
- и т.п.
В рамках данного учебника я решил не рассказывать об этих расширениях, т.к. и без их знания, владея только базовыми конструкциями языка SQL, вы сможете решать очень большой спектр задач. Расширения языка SQL по сути служат для решения какого-то определенного круга задач, т.е. позволяют решить задачу определенного класса более изящно (но не всегда эффективней в плане скорости или затраченных ресурсов).
Если вы делаете первые шаги в SQL, то сосредоточьтесь в первую очередь, именно на изучении базовых конструкций, т.к. владея базой, все остальное вам понять будет гораздо легче, и к тому же самостоятельно. Вам в первую очередь, как бы нужно объемно понять возможности языка SQL, т.е. какого рода операции он вообще позволяет совершить над данными. Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции.
Удачи вам в изучении и понимании языка SQL.
Часть четвертая — habrahabr.ru/post/256045
Если эта публикация вас вдохновила и вы хотите поддержать автора — не стесняйтесь нажать на кнопку
Изучая операторы в Си, нужно учитывать, что их очень много. Все они имеют одну цель – управление операндами (объектами, которыми можно управлять в процессе обработки имеющегося кода). При работе с потоками и крупными приложениями нужно использовать конструкцию типа case. Чаще встречается связка «switch-case». Именно о ней зайдет речь далее. Информация будет одинаково полезна и новичкам, и опытным разработчикам.
Определение
Оператор switch case в C работает подобно if…else. Это – своеобразная конструкция выбора. Используется как механизм потока управления, определяющий дальнейшее исполнение кода, отталкиваясь от значений переменных или выражений.
Switch дает возможность организации тестирования нескольких прописанных условий. Тот или иной блок будет выполняться, если значение, полученное на «выходе» является истиной. Работает как if…else, хотя имеет более простой синтаксис. Switch Case – конструкция, которая обладает более простой системой управления. Используется в СИ-семействе достаточно часто.
Инструкция – общий вид
If else и switch c – операторы, схожие между собой по действию. Это – своеобразный цикл, который будет проверять достоверность условия, выполняя заданную операцию. Структура Switch Case в Си будет такой:
Switch (желаемое выражение) {
case 1 контекст: операторы
case 2 контекст: операторы
case 3 контекст: операторы
default: инструкции
}
Структура состоит из двух элементов:
- заголовка switch;
- тела инструкции, которое записано в составном операторе (после фигурных скобок, внутри).
В зависимости от значения соответствующего выражения будет меняться выполняемая ветка кода. Выражение должно содержать только целочисленные параметры (число) или символьные данные. Это – единственное ограничение, накладываемое на оператор switch case c.
Принцип работы
Рассматриваемое выражение базируется на простой логике оценки каждого блока case. Начинается процесс с вычисления выражения, прописанного внутри блока переключателя. Далее сравнивается значение из имеющегося блока с каждым case.
При обнаружении совпадений происходит реализация кода, написанного в «кейсе». Происходит это до тех пор, пока система не встретит ключевое слово. Это – оператор break.
Если совпадений в конструкции switch-case нет, код переходит к оператору по умолчанию, выполняя условия, предусмотренные им. Компонент изначально не является обязательным. Его можно исключить, если нет определенных инструкций для несоответствующего сценария.
Чтобы использование «множественного выбора» (рассматриваемой конструкции) функционировало нормально, внутри каждого case прописывают break. Это поможет избежать выполнения всех инструкций после соответствующего «истинного» блока.
Далее – примеры записи switch case default c, которые являются правильными и неправильными. Эта информация поможет избежать ошибок, when новичок осваивает соответствующий функционал языка:
int c, a;
char s;
double g;
switch (c) – правильно;
switch (g) – неправильно, речь идет о вещественной переменной;
switch (s) – неправильно, символьная переменная;
switch ((a+c)+2) – правильно, выражение целочисленного характера.
В фигурных скобках можно записывать несколько блоков. Там может быть далеко не одна функция (или две), а значительно больше. Каждая такая команда – это определенный выбор. Из-за этого соответствующая запись носит название «множественного».
При составлении case существует одно ограничение – константы ветки должны отличаться. When в коде встречаются сходства, он выдает ошибку. Поэтому перед запуском программы проводят проверку значений case.
Вложенность
In Switch выражении структура предусматривает вложенность. Это – переключение внутри конструкции. Функция работает, если switch-запись будет привязываться к значениям of внешнего переключателя.
Вот – example of множественного выбора, где можно использовать вложенность:
Здесь:
- Реализовываются конструкторы. Интересующий «множественный» цикл нужно использовать два раза.
- Предложенный синтаксис первой записью в functions проводит проверку равенства dept 1.
- Если выражение имеет «истину», следуют переходы ко второму блоку. Там происходит проверка of действительности кода доступа.
- When dept имеет значение false, код будет пользоваться function default (условием по умолчанию).
Использование записи switch case int даже с вложениями – несколько условий в одном, легко реализуемых. Особенно если изучить конструкцию if else и наглядные примеры множественной выборки.
Пример с отделами доступа
Ниже – examples использования рассмотренного ранее примера с правильным и неправильным кодом отдела доступа:
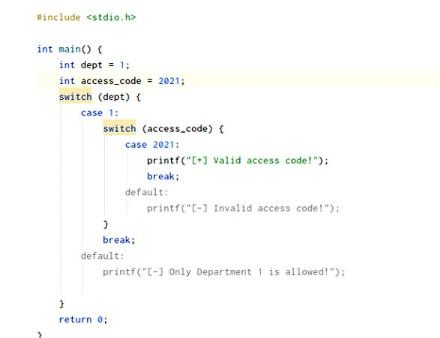
Первый цикл – в нем верен и отдел, и код доступа. Выполнение приложение никогда не достигнет cases по умолчанию. Всегда будет обрабатываться команда. Применение ключа Break здесь помогает остановить приложение при необходимости.
Второй пример – ситуация, при которых и код доступа, и отдел неверные. Цикл switch case break c перейдет к первому блоку по умолчанию.
Рекомендации – как лучше использовать
Для того, чтобы не запутаться в записи оператора, рекомендуется:
- Разобраться in syntax конструкции switch c. Он прост.
- Присваивать «кейсам» уникальные значения. Иначе цикл не будет обработан in codes.
- Каждый блок заканчивать ключевым словом break. Этот прием позволит избежать образования петель.
- Использовать int и иные целочисленные параметры (включая zero) в процессе. Также допускаются символы. Остальные типы данных не поддерживаются.
Для сокращения объема кода подходит оператор switch в Си с вложениями. Поддерживается многоуровневая вложенность. Образцом послужит пример выше.
А еще программист должен подумать, что делать, если ни одно условие цикла не истинно. В данном случае рекомендуется предусмотреть оператор по умолчанию.
Быстрое изучение
Switch Case d c – запись, которая известна не всем новичкам. Чтобы лучше разобраться в ней, можно посмотреть туториалы. Пример – тут.
Быстро разобраться в switch case int и иных операторах помогут специализированные компьютерные курсы. Организовываются дистанционно. Подойдут новичкам и опытным программистам. В конце программы выдается электронный сертификат.
Интересует разработка на C? Обратите внимание на курс «Программист C» в Otus.
Сейчас мы с вами посмотрим на управляющие инструкции, Т.е инструкции которые управляют ходом выполнения вашей программы. Что я имею ввиду?
Вы можете представить программу как последовательность некоторых инструкций(первая схема на изображении), но зачастую вы хотите чтобы какие-то инструкции выполнялись при выполнении каких-то условий(вторая схема на изображении) или чтобы инструкции повторялись пока какое-то условие выполняется(третья схема на изображении).
Ветвление (условная инструкция) — это конструкция языка программирования, обеспечивающая выполнение определённой команды или набора команд только при условии истинности некоторого логического выражения, либо выполнение одной из нескольких команд (наборов команд) в зависимости от значения некоторого выражения.
Цикл — это разновидность управляющей конструкции, предназначенная для организации многократного исполнения набора инструкций.
Конструкция if/else
Это конструкция ветвления, прочитывается она достаточно естественно.
Если (какое-то условие выполняется) {
выполнить следующее
} иначе {
выполнить что-то другое
}
А теперь уже более корректный пример:
if () {
do_something();
} else {
console.error(«Все плохо =(«);
do_something_else();
}
Вы можете опускать ветку else… ну уж если вы ничего не хотите делать если условие не выполняется.
if (true) {
do_something();
}
Для того чтобы делать множественные проверки, вы можете добавить дополнительное условие в ветке else.
var name = «Bob»;
if (name === «John») {
console.log(«Гость любит чай»);
} else if (name === «Mia») {
console.log(«Гость любит кофе»);
} else {
console.log(«Неизвестный гость»);
}
Конструкция switch/case
Конструкция switch заменяет собой сразу несколько if.
Она представляет собой более наглядный способ сравнить выражение сразу с несколькими вариантами.
var command = «camel»;
switch (
command
) {
case «up»:
alert(«Перевести строку в верхний регистр»);
break;
case «down»:
alert(«Перевести строку в нижний регистр»);
break;
case «camel»:
alert(«Перевести строку в вид: ‘CaMeLcAsE'»);
break;
case «turn»:
alert(«Поменять регист для каждой буквы на противоположный»);
break;
default:
alert(«Неизвестная команда! Вы ошиблись!»);
}
В примере выше мы инициализировали переменную содержащую строку «up». Конструкция switch case позволяет сделать множественные сравнения переданного ей значения с значениями, которые мы указали в case. Если значения совпали, то код указанный в этом кейсе будет выполнен.
В результате выполнения кода выше в диалоговом окне мы увидим сообщение «Перевести строку в верхний регистр»
Обратите внимание на инструкцию break. Она обязательна… если мы пропустим ее в одном из «кейсов», то исполнения пойдет по следующим case до ближайшего break или до конца инструкций в «кейсах».
Циклы
Циклы – простой способ сделать какое-то действие несколько раз.
Итерация (лат. iteratio — повторяю) – повторение какого-либо действия.
info
Слово Итерация так же обозначет каждое выполнение тела цикла. Т.е «перейти на слудующую итерацию» обозначает запустить следующее выполнение тела цикла.. перейти на новый круг.
В Javascript у нас есть 3 основных типа циклов:
whiledo whilefor
Как уже сказано, циклы нужны для того чтобы повторять какие-то инструкции пока выполняется условие. И в действительности, мы могли бы жить только с циклом ну например while, но для удобства, нам предоставляют несколько их видов.
Зачем нам нужны циклы?
Ну тут все просто.. если вам надо отправить 5 сообщений в телеграм, то вам надо повторить некоторые инструкции 5 раз. Для этого нам пригодятся циклы.
Обратите внимание
Помните я рассказывал вам, как выполняются инструкции на CPU, и что из себя представляют ассемблерные инструкции? Так вот, циклы которые нам предоставляют языки программирования являются — синтаксическим сахаром.
Ваш CPU ничего не знает про циклы, а разворачиваются они в последовательность каких-то инструкций. Для того чтобы инструкции выполнялись повторно, происходит выполнение инструкции jmp.
Для наглядности вот вам интересная ссылочка. Советую ознакомиться.
Интересный факт
Существуют языки в которых циклы как таковые отсутствуют, это популярно в функциональных языках программирования, а повтор каких-то действий осуществляется через рекурсию.
Итерирование по последовательностям
Существует еще 2 инструкции for of и for in для интерирования по последовательностям. Более детально про них мы посмотрим когда начнем знакомиться с массивами.
while
Выглядит как:
Более наглядный пример:
var i = 1;
var sum = 0;
while (i <= 100) {
sum += i;
i++;
}
console.log(sum);
do while
То же самое, что и while за исключением того, что сначала выполняется код в теле цикла, а только потом делается проверка стоит ли исполнять тело еще раз
do {
i += 1;
console.log(i);
} while (i < 5);
Цикл do while гарантирует хотя бы одно срабатывание кода.
for
Не сильно отличается от обычного while. В основном используют именно этот цикл, потому, что он позволяет в более элегантной форме создавать счетчик и инкрементировать его.
for ([начало]; [условие]; [шаг]) {
}
*Квадратные скобочки в описании синтаксиса инструкции говорит о том, что это выражение(параметр) не является обязательным.
Похожие квадратные скобочки мы будем видеть, когда будем читать описание функций*
Перепишем пример цикла который был приведен в описании инструкции while использую инструкцию for:
var sum = 0;
for (var i = 0; i <= 0; i++) {
sum += i;
}
console.log(sum);
Экономия только в 2 строчки кода, но зато мы аккуратно инициализировали счетчик и не забудем инкрементировать(тело цикла бывает очень объемное) его после каждой итерации. Цикл for более предпочтителен чем while
Управление циклом break/countinue
Мы посмотрели как пользоваться циклами, но сейчас у нас нет возможности управления ими.
break
Давайте представим что нам надо прервать выполнение цикла в определенной ситуации. Ну например у вас есть последовательность чисел:
let NUM_SEQ = [5, 17, 40, 22, 17];
Мы хотим итерироваться по этому списку, но как только мы нашли число больше чем 20 мы хотим прервать итерирование для этого мы можем воспользоваться инструкцией break.
let i = 0;
let first_greater_then = null;
while (i < NUM_SEQ.length) {
if (NUM_SEQ[i] > 20) {
first_greater_then = NUM_SEQ[i];
break;
}
}
break — инструкция которая приводит к прекращению выполнения текущего цикла вне зависимости от того, выполняется ли тест-условие или нет.
Вопрос на засыпку
У вас есть идеи как реализовать подобное поведение без использования инструкции break?
continue
Мы вроде как знаем каким образом можно прекратить выполнение цикла, но как прекратить выполнение текущей итерации и перейти сразу к проверке и следующему кругу выполнения? Для этого у нас есть инструкция continue.
Давайте какой-нибудь выдуманный пример. Допустим мы проходимся по числам от 0 и до 10, и суммируем только те, что нечетны двум.
let acc = 0;
for (let i = 0; i < 10; i++) {
if (i % 2 == 0) continue;
acc += i;
}
break — инструкция которая приводит к прекращению выполнения текущей итерации и сразу же выполняется следующая проверка условия.