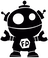
Приветствую! Далеко не все пользователи задумываются, как конкретно работает процессор и как ему удаётся работать с программами. И это, впрочем, и не нужно знать, так как видеть результат этой работы вполне достаточно. Но иногда возникает проблема, когда ЦП просто не может справиться с каким-нибудь ПО или что бывает даже чаще, игрой.
Причиной этого могут являться неподходящие характеристики ПК, а среди них иногда упоминается и недостаток инструкций процессора, само существование которых может вызывать озадаченность. А ведь инструкции процессора это именно то, что и позволяет ему работать с разными программами. Поэтому о них и поговорим далее.
Содержание
- Для чего нужны инструкции в процессорах
- Какие наборы инструкций существуют и чем отличаются
- Как узнать какие инструкции поддерживает процессор
Для чего нужны инструкции в процессорах
У термина «инструкция» здесь нет никакого особого значения, это всё так же некоторая последовательность действий, которую нужно выполнить для получения результата.
А так как обработка данных — это основная задача ЦП, они все используют наборы заложенных команд для выполнения различных операций с информацией. Здесь нужно учитывать, что любая программа, от ОС до игры — это тоже совокупность команд, и когда ЦП выполняет инструкции, которые нужны программе для работы, всё складывается, и вы получаете результаты.
Если команд нет или их набор в неподходящей версии, с выполнением программы будут трудности. Звучит просто, но на самом деле система сложнее, просто я делаю допущения для вашего удобства.
Пакет инструкций, поддерживаемых процессором, закладываются в него изначально, поэтому поменять вы его не сможете. Разве что купив новый, более мощный ЦП.
Какие наборы инструкций существуют и чем отличаются
Условно команды можно разделить на две большие группы — базовые и дополнительные. Базовые нужны для выполнения основных операций, которые и заставляют CPU работать, дополнительные — для особых задач и оптимизации работы ЦП.
Команды общего назначения выполняют универсальные арифметические, логические, информационные задачи, а также те, что связаны с переносом данных и т. д. То, какие инструкции может выполнять ваш ЦП, зависит от его архитектуры, чем она лучше, тем команд больше. А вот разрядность CPU, например, влияет на то, как много команд одновременно получится выполнить.
Базовые команды общие для всех процессоров, так что вам достаточно знать только архитектуру. А дополнительные различаются в зависимости от производителя CPU и версии, так как меняются чаще, чем фундаментальные.
Например, вы можете увидеть, что ваш ЦП поддерживает MMX. Это набор, который пригодится для ускоренной обработки фото, аудио и видео. Он был разработан Intel ещё в конце 90-х.
SSE обеспечивает устройствам от Intel быстродействие, когда одни и те же данные нужно использовать в разных вычислениях.
SSE2 необходима всему современному ПО, без этих команд у вас не будут работать ни версии Windows, начиная с 8, ни большинство программ. Например, даже браузеры от Яндекса и Google не получится запустить.
SSE3 пригодится для обработки графической, аудио и видеоинформации. Есть и другие версии SSE, каждая из которых имеет больше команд, чем предыдущая.
AES, которую также можно встретить в Intel, представляет собой расширение команд ЦП для ускорения работы программ и их большей защищённости. Название связано с алгоритмом шифрования Advanced Encryption Standard.
AVX, разработанный Intel в 2008, влияет как на вычислительные, так и мультимедийные возможности ЦП. А вот следующая версия, AVX 2, даёт прирост производительности при работе с фото, видео, аудио, программами распознавания голоса и т. д.
FMA ускоряет операции умножения и сложения с плавающей запятой, которые выполняются командами общего назначения.
А VT-x расширяет возможности работы ПК с виртуальными машинами.
Как вы могли заметить, инструкции, описанные выше, актуальны для Intel. А вот, например, для AMD есть свои:
- SenseMI — в первый раз использовался в Ryzen, прогнозирует программный код для лучшей производительности ЦП.
- AMD CoolCore — реализует временное отключение блоков процессора для снижения энергопотребления.
- AMD CoolSpeed — защищает ЦП от перегрева.
- AMD Enduro — ещё одна технология для энергосбережения.
Есть и универсальные технологии, вроде BMI или F16C.
Те наборы команд, которые я описал, лишь малая часть того, что вы можете встретить. Но я думаю и их достаточно, чтобы понять суть. Обращайте на них внимание в характеристиках программ, а в особенности игр, перед покупкой.
Как узнать какие инструкции поддерживает процессор
Вы наверняка уже задались вопросом, как узнать какие инструкции поддерживает процессор компьютера, и я могу на него ответить.
Для начала, вы можете найти список команд ЦП, просто сделав поисковый запрос. Зачастую нужная информация найдётся на официальных сайтах производителей ЦП. Если не получится, то на сайтах, посвящённых компьютерам, нередко есть целый раздел, где можно ввести название устройства в поиск и прочесть расширенные данные о нём. О наборах команд обязательно что-то будет.
Если не хотите искать, есть и другой способ, как посмотреть количество инструкций ЦП. Например, вы можете воспользоваться CPU-Z или другими подобными программами. В CPU-Z нужная информация будет в блоке «Instructions» прямо в первом окне. Скопируйте список и просто сравните его с требованиями для игр или ПО. Всё равно если вы не увидите подходящих версий, поможет только замена устройства.
На самом деле, инструкции процессора — не такая простая тема. Но описанного выше, думаю, вполне достаточно, чтобы иметь общее представление о том, что такое инструкции процессора и откуда их взять. Подробнее о других особенностях ЦП и остальных компонентах компьютеров поговорим в другой раз, и чтобы не пропустить новые публикации, нужно лишь подписаться на мои социальные сети, где новости всегда самые свежие. Увидимся!
С уважением, автор блога Андрей Андреев.
Процессор не поддерживает MMX
Однако такие исключения встречаются редко и в большинстве случав программа, взамен отсутствующих SIMD, будет использовать универсальные (genegic) х86 инструкции. При этом мы не получим никакого повышения быстродействия, но и снижения производительности (по сравнению с обычным кодом) также не будет.
Поскольку каждый производитель процессоров по-своему улучшал архитекутуру, развитие микропроцессоров сопровождалось появлением нескольких вариантов SIMD расширений. Основные из них мы рассмотрим ниже.
MMX-расширение появилось в Pentium MMX (P55, январь 1997) и включало в себя 57 новых команд, предназначенных для обработки звуковых и видеосигналов. Позднее их поддержка появилась в K6 (Little Foot) от AMD и в 6х86MX от Cyrix.
MMX-расширение микропроцессора Pentium предназначено для поддержки приложений, ориентированных на работу с большими массивами данных целого типа, над которыми выполняются одинаковые операции. С данными такого типа обычно работают мультимедийные, графические, коммуникационные программы. По этой причине данное расширение архитектуры микропроцессоров Intel и названо
MultiMedia eXtensions (MMX), что переводится как мультимедиа расширения.
Основа программной компоненты – система команд MMX-расширения (те самые 57 новых команд) и четыре новых типа данных. MMX-команды являются естественным дополнением основной системы команд микропроцессора. Основным принципом их работы является одновременная обработка нескольких единиц однотипных данных одной командой. Основа аппаратной компоненты – 8 MMX регистров, каждый размером в 64 бит = 8 байт. MMX работает только с целыми числами; поддерживаются данные размером в 1, 2, 4 или 8 байт. То есть, один MMX регистр может содержать 8, 4, 2 или 1 операнд соответственно.
Формат регистра ММХ
На самом деле эти регистры не являются новыми, а MMX-расширение использует регистры сопроцессора (FPU). Как известно, регистры сопроцессора стека имеют размерность 80 бит, что касается MMX регистров, то их разрядность только 64 бита. Поэтому, когда регистры сопроцессора играют роль MMX-регистров, то доступными являются лишь их младшие 64 бита. К тому же, при работе стека сопроцессора в режиме MMX-расширения, он рассматривается не как стек, а как обычный регистровый массив с произвольным доступом. Таким образом, можно сказать, что расширения MMX реализованы в виде дополнительного pежима, в который процессор может переключаться из обычного pежима работы. Регистровый стек сопроцессора не может одновременно использоваться и по своему прямому назначению и как MMX-расширение, поэтому необходимо заботиться о его разделении и корректной работе с ним. Такое совмещение может снизить эффективность работы в случае попеременного использования обычных вычислений с плавающей точкой и работы в режиме MMX.
Данные, содержащиеся в MMX-регистрах, можно покомпонентно складывать, умножать, вычитать, выполнять разнообразные специфические, необходимые для мультимедиа приложений, операции, вроде сложения без переполнения, вычисления среднего арифметического и производить логические операции с битами (побитовый and, or, xor). Делить, правда, нельзя, есть ещё ограничения. Но многие операции можно делать на порядок быстрее, даже больше. Однако, применение MMX в особенности требует специальной ручной оптимизации, никакой компилятор тут существенно не поможет. Под MMX, например, оптимизируются разнообразные кодеки аудио файлов, алгоритмы работы которых хорошо сочетаются с MMX. Причём, не вся программа целиком, а небольшая часть, выполняющая основную работу, и это обстоятельство упрощает оптимизацию.
SSE
Данное расширение появилось в Pentium III (ядро Katmai, сентябрь 1999) и насчитывало 70 новых команд. Позднее в Athlon XP (начиная с Palomino) его стали поддерживать и процессоры AMD. Аббревиатура SSE расшифровывается как
Streaming SIMD Extensions (потоковые SIMD расширения).
SSE интересно прежде всего тем, что оперирует с данными вещественного типа, которые используются в геометрических расчётах, то есть, приложениях трёхмерной графики, компьютерных играх, редакторах вроде 3DStudioMax, и многих других. С тех пор как в компьютерных играх вроде Quake текстурирование треугольников стало производиться при помощи видеоускорителей, большая надобность в целочисленных вычислениях отпала. На первое место вышла скорость операций с плавающей точкой, вроде перемножения вещественного вектора на вещественную матрицу.
При внедрении SSE процессор получил в дополнение к стандартным регистрам архитектуры x87 8 новых больших регистров размером по 128 бит, в каждом из которых содержится 4 32-битных вещественных числа. С четвёрками операндов можно покомпонентно производить следующие операции: сложить две четвёрки чисел, вычесть, перемножить, разделить. Вычислить одновременно 4 (обратных) квадратных корня, точно или приближённо. Ещё можно тасовать содержимое регистров, перекладывать данные из одних частей регистра в другие и производить некоторые другие аналогичные операции. Однако перемещение данных происходит не быстрее их сложения, так что эффективное использование SSE возможно только на подготовленных правильно упакованных данных.
Если посчитать, что SSE-операция заменяет 4 аналогичных обыкновенных, то при оптимизации можно получить прирост производительности в 4 раза. Если быть более точным, то даже несколько больше, за счёт использования новых больших регистров. Однако, далеко не все вычисления можно эффективно оптимизировать под SSE. Как пример «хорошей» задачи следует привести умножение четырёхмерной матрицы на четырёхмерный вектор. Ускорение четырёхкратное без особых затрат.
В первую очередь использование SSE позволяет современным процессорам при выполнении трансформации вершин треугольников, составляющих трёхмерную сцену, успешно соревноваться с видеоускорителями. Другое дело, что у процессора много других задач, и лучше его по возможности разгрузить, чтобы он работал параллельно с видеоускорителем, и каждый выполнял свою задачу.
SSE2
Следующее расширение, являющееся логическим продолжением MMX и SSE появилось в Pentium 4 (начиная с Willamette). В Athlon 64 появилось начиная с Clawhammer.
В данное расширение включены 144 команды SSE2, ориентированные, в первую очередь, на работу с потоковыми данными. Подобно Pentium III, они также оперируют со 128-битными регистрами, но уже не только с четверками чисел одинарной точности, но и с любыми другими типами данных, которые умещаются в 128 бит. Это пары вещественных чисел двойной точности, шестнадцать однобайтовых целых, восьмерки двухбайтовых целых, пары восьмибайтовых целых etc. В результате получился некий симбиоз MMX и SSE.
Теперь те же 8 больших 128-битных регистров уже можно интерпретировать как содержащие не четыре 32-битных вещественных числа, а два 64-битных вещественных числа повышенной точности. Числа с повышенной точностью используются в тех случаях, когда вычисления с обычной точностью приводят к большим погрешностям. Все операции перенеслись с SSE, только работают не с четвёркой пар операндов, а с двойкой пар операндов.
В SSE2 регистры по сравнению с MMX удвоились, то есть, там стало помещаться не, например, 8 чисел, а 16. Поскольку скорость выполнения инструкций не изменилась, при оптимизации под SSE2 программа запросто получала двукратный прирост производительности. Надо отметить ещё следующее обстоятельство. Если программа уже была оптимизирована под MMX, то оптимизация под SSE2 даётся сравнительно легко в силу сходности системы команд.
SSE3
Следующий набор появился в Pentium 4 начиная с Prescott и Athlon 64 начиная с Venice. Это расширение, имевшее поначалу имело рабочее название
Prescott New Instruction, но получившее в итоге не совсем верное с технической точки зрения название SSE3, призвано облегчить оптимизацию программ под SSE и SSE2. Причём, в первую очередь, сделать более легкой полностью автоматическую оптимизацию программ средствами компилятора. То есть, для оптимизации необходимо будет просто перекомпилировать программу.
Некорректность названия SSE3 объясняется тем, что в отличие от других SIMD инструкций, где операции (например сложение) выполняются вертикально, здесь появилась возможность горизонтального выполнения операций.
Вертикальное сложение
Горизонтальное сложение
Таким образом в SSE3 появились удобные команды горизонтального последовательного сложения и вычитания операндов, а также другие разнообразные вспомогательные команды, облегчающие работу с данными.
SSE4 *
Данный набор появился в новейших процессорах Intel Core 2. Конкретная информация по этим инструкциям пока отсутствует.
Кстати стоит отметить, что в новых интеловских процессорах появилась технология Intel Advanced Digital Media Boost, суть которой в ускорении выполнения SIMD инструкций. Если раньше каждая инструкция выполнялась за два такта (один такт для обработки старших 64 бит, а второй такт для младших), то теперь выполнение этой инструкции занимает один такт. Налицо двукратное ускорение, что должно сказываться на работе программ, оптимизированных под этот набор инструкций.
*Обновлено: информация о наборе инструкций SSE4 оказалась преждевременной, на самом деле SSE4 появится в процессорах поколения Penryn, которые предположительно должны появиться в четвертом квартале 2007 года.
3DNow!
Различают три поколения этого расширения инструкций: 3DNow!, Enhanced 3DNow! и 3DNow! Professional, однако очень часто их все называют просто 3DNow!
Набор инструкций 3DNow! появился в AMD K6-2 (Chomper). Данный набор, состоящий из 21 команды, был оптимизирован для еще более узкой области, нежели «универсально-мультимедийный» Intel MMX, а именно: для наиболее ресурсоемких расчетов, связанных с 3D-графикой. Даже в самом названии этого набора (3DNow!) отразилась область его применения. Это расширение во многом сходно с SSE, но так же имеет и значительные отличия. Регистров так же 8, но они размером не 128 бит, а 64. Соответственно, в них помещается не 4 числа, а только 2. Имеется аналогичный SSE набор арифметических операций с регистрами. Сложить-умножить-разделить две пары операндов и т.п. Есть и операции нахождения (обратного) квадратного корня, точные и более быстрые приближённые. Однако, есть ещё одно важное отличие расширения 3DNow! Можно складывать между собой содержимое одного регистра. То есть, так же как и в SSE3, производить не только вертикальные операции, но и горизонтальные.
Другое важное обстоятельство, говорящее в пользу 3DNow!, это возможность достаточно эффективной автоматической оптимизации средствами компилятора. SSE слишком громоздко — размеры регистров большие — для автоматической организации данных. На коде, наполненном вычислениями с плавающей точкой, можно было бы бесплатно получить примерно полуторный прирост производительности.
В дальнейшем изменения блока 3DNow! произошли в К7. Он, как и раньше, работал с 64-битными регистрами, в которых находились пары вещественных чисел одинарной точности, зато его набор команд расширился еще на 24 инструкции (Enhanced 3DNow!). Последнее расширение этого набора до 3DNow! Professional появилось в ядре Thoroughbred.
На развитие набора 3DNow! негативно повлияло то, что у AMD первое время отсутствовал оптимизирующий компилятор, к тому же разработчики программ не торопились оптимизировать свои программы под эти инструкции.
Оценка прироста производительности.
Для того, чтобы определить, какой прирост быстродействия дают SIMD-инструкции было решено провести тестирование. Мы должны сравнить быстродействие программы в двух режимах (или двух программ): с оптимизацией под SIMD-инструкции и без нее. Это возможно в двух случаях: при использовании двух версий одной и той же программы (одна версия оптимизирована, а другая нет) или при наличии в программе функции отключения оптимизации. Однако здесь я столкнулся с проблемой – программ, имеющих такую фичу крайне мало
. В случае с различными версиями одной программы, просматривая Changelog было обнаружено, что практически всегда наряду с включением поддержки SIMD-инструкций, в новой версии появлялись какие-либо дополнительные оптимизации. В таком случае сравнение программ разных версий представляется некорректным с точки зрения поставленной цели.
После продолжительного поиска необходимые бенчмарки были найдены. Все они имеют возможность включать/отключать оптимизацию под определнные виды инструкций. Итак, тесты условно были поделены на четыре группы:
1.Видео: кодек XviD 1.1.0, MSU Deblocking Filter v2.2 (фильтр для VirtualDub)
2.Аудио: Lame 3.97 b2.
3.Синтетика: Sandra 2007, CPU RightMark 2003B.
4.Игры: Doom 3 ,Quake 4.
Тестовая конфигурация:
Материнская плата: Gigabyte GA-8I945P-G, BIOS v.F10
Процессор: Intel Pentium 4 630@3.600 MHz
Система охлаждения: TT Big Typhoon
Оперативная память: 512 Mb DDR2–667@638 Samsung Original (5-5-4-14), 512 Mb DDR2–667@638 Hynix (5-5-4-14)
Видеокарта: PCI-E Palit GeForce 6600GT@585/551 MHz
Дисковая подсистема: 160Gb SATA-II SAMSUNG HD160JJ, 40Gb Ultra-ATA/100 Seagate Barracuda ST340014A
Software: Windows XP SP2, ForceWare 91.28
Видео
XviD 1.1.0
MSU Deblocking Filter v2.2
Кодеком Xvid кодировался 160 MB файл из формата mpeg2. Перед фильтром MSU Deblocking стояла задача обработки 80 MB файла без последующего сжатия. Оба теста проводились в VirtualDub 1.6.15. Измерялось время выполнения в секундах. Как видно из результатов, использование оптимизации дает более чем двукратный прирост производительности
. Особенно впечатляет ускорение c MMX и SSE. Малый прирост у SSE2 можно списать под плохую оптимизацию кодека.
Аудио
Lame 3.97 b2
Данный аудиокодек хоть и не обладает графическим интерфейсом, но имеет большое число настраиваемых параметров через командную строку. Для отключения оптимизации используется флаг —noasm xxx (где xxx – отключаемый набор инструкций). В формат mp3 преобразовывался 400 MB wav файл. Прирост не такой большой, как в случае с видео, но все же ускорение в 1,5 раза можно назвать успехом. Особенно сильна ”заточка” под MMX, что не удивительно ведь данное расширение создавалось специально для мультимедиа.
Синтетические тесты
Sandra 2007, Whetstone
Sandra 2007, Dhrystone
CPU RightMark 2003B, Math
CPU RightMark 2003B, Rendering
C Сандрой все понятно: при прогоне арифметического теста, прирост в тесте с FPU объясняется увеличением объема обрабатываемых данных (за счет увеличенного размера SIMD-регистров), а его отсутствие в тесте АЛУ тем, что SSE2 и SSE3 предназначены для операций с плавающей запятой.
Тест CPU RightMark достаточно редко встречается в обзорах, и я не удивлюсь если о нем слышали немногие (я сам только недавно его ”выловил”). Тест моделирует поведение притягивающихся и отталкивающих шаров в пространстве. Сам он представляет собой, по сути, два теста, объединенных в один. Модуль решателя (solver) рассчитывает физику взаимодействия тел, а модуль рендеринга (render) отображает это взаимодействие на экране. Нагрузку можно изменять и на модуль решателя (увеличивая количество рассчитываемых объектов), и на модуль рендеринга (изменяя количество источников света и качество текстур). В обоих модулях можно настраивать то, какие инструкции будут использованы при решении задачи. Тест больше оптимизирован под SSE/SSE3, поскольку требуется рассчитывать координаты объектов и силы их взаимодействия.
Игры
Doom3, Low Quality
Doom 3, Ultra Quality 2xAA, 4xAF
Quake 4, Low Quality
Quake 4, Ultra Quality 2xAA, 4xAF
Из игр только последние версии Doom и Quake позволяют отключать оптимизацию под SIMD-инструкции. Делается это в консольной командой com_ForceGenericSimd. Тесты проводились при разрешении 1024*768, при минимальном и максимальном (с 2xAA и 4xAF) качестве. При этом настройки антиалиасинга и анизотропной фильтрации принудительно выставлялись в настройках драйвера видеокарты. Для тестирования Doom 3 использовалось стандартное demo1, для Q4 была записана демка на уровне Air Defence Trenches. Демо прогонялись четыре раза, вычислялось среднее арифметическое последних трех прогонов.
Как и ожидалось прирост от использования SIMD-инструкций в играх мал, и он тем меньше, чем лучше настройки графики.
Заключение
Как видно оптимизация приложений под SIMD-инструкции приносит свои плоды в виде повышения производительности. Прирост состоит от нескольких процентов играх, до полутора-двух раз при обработке видео и звука. Насколько же хороша оптимизация и во сколько секунд/fps/попугаев она выльется зависит и от создателей процессоров, и от производителей программного обеспечения. При их тесном сотрудничестве производительность компьютеров будет повышаться, а это именно то, что нам и надо
.
Напоследок хочу привести таблицу десктопных ядер от Intel и AMD с указанием поддерживаемых наборов инструкций.
| Ядро | MMX | SSE | SSE2 | SSE3 | SSE4 | 3DNow! |
|---|---|---|---|---|---|---|
| P54 | — | — | — | — | — | — |
| P55 | + | — | — | — | — | — |
| Covington | + | — | — | — | — | — |
| Mendocino | + | — | — | — | — | — |
| Klamath | + | — | — | — | — | — |
| Deschutes | + | — | — | — | — | — |
| Katmai | + | + | — | — | — | — |
| Coppermine | + | + | — | — | — | — |
| Tualatin | + | + | — | — | — | — |
| Willamette | + | + | + | — | — | — |
| Northwood | + | + | + | — | — | — |
| Prescott | + | + | + | + | — | — |
| Prescott-2M | + | + | + | + | — | — |
| Smithfield | + | + | + | + | — | — |
| Presler | + | + | + | + | — | — |
| Core 2 | + | + | + | + | — | — |
| 5K86 | — | — | — | — | — | — |
| Little Foot | + | — | — | — | — | — |
| Chomper | + | — | — | — | — | + |
| Sharptooth | + | — | — | — | — | + |
| Pluto | + | — | — | — | — | + |
| Orion | + | — | — | — | — | + |
| Spitfire | + | — | — | — | — | + |
| Morgan | + | + | — | — | — | + |
| Thunderbird | + | — | — | — | — | + |
| Palomino | + | + | — | — | — | + |
| Thoroughbred | + | + | — | — | — | + |
| Barton | + | + | — | — | — | + |
| Thorton | + | + | — | — | — | + |
| Applebred | + | + | — | — | — | + |
| Sledgehammer | + | + | + | — | — | + |
| Clawhammer | + | + | + | — | — | + |
| Paris | + | + | + | — | — | + |
| Palermo | + | + | + | + | — | + |
| Newcastle | + | + | + | — | — | + |
| Venice | + | + | + | + | — | + |
| San Diego | + | + | + | + | — | + |
| Winchester | + | + | + | — | — | + |
| Manchester | + | + | + | + | — | + |
| Toledo | + | + | + | + | — | + |
| Manila | + | + | + | + | — | + |
| Orleans | + | + | + | + | — | + |
| Windsor | + | + | + | + | — | + |
При написании статьи использовались материалы с сайтов overclockers.ru, ferra.ru, fcenter.ru, thg.ru, ixbt.com, intel.com, 3dnews.ru.
С уважением, Таболин Юра aka olddanmer
Вопросы и предложения мылить на danmer@udm.ru
Вычислительное ядро (или процессор) является одной из ключевых компонентов компьютера. Оно выполняет множество задач, связанных с обработкой данных и выполнением команд. В этой статье мы рассмотрим основные характеристики и функции вычислительного ядра компьютера.
1. Архитектура процессора
Архитектура процессора определяет внутреннее устройство и организацию его работы. Существует два основных типа архитектур: CISC (Complex Instruction Set Computer) и RISC (Reduced Instruction Set Computer). CISC-процессоры имеют большой набор инструкций, в то время как RISC-процессоры имеют более простой и ограниченный набор инструкций, что делает их более эффективными в выполнении операций.
2. Частота процессора
Частота процессора измеряется в герцах (ГГц) и определяет скорость выполнения инструкций. Чем выше частота процессора, тем быстрее он способен обрабатывать данные. Однако частота не является единственным показателем производительности, так как эффективность зависит также от архитектуры и числа ядер процессора.
3. Количество ядер
Современные процессоры могут иметь одно или более ядер, что позволяет выполнять несколько задач одновременно. Это увеличивает производительность и позволяет обрабатывать многозадачность более эффективно. Процессоры с множеством ядер называются многоядерными.
4. Кэш-память
Кэш-память — это быстрая память, которая используется для временного хранения данных, к которым процессор имеет быстрый доступ. Она делится на уровни (L1, L2, L3), при этом L1 находится ближе всего к процессору и имеет самый быстрый доступ. Большой и быстрый кэш может существенно повысить производительность.
5. Поддержка набора инструкций
Процессоры могут поддерживать различные наборы инструкций, такие как x86, ARM и другие. Поддержка определенного набора инструкций определяет, какие программы и операционные системы могут быть выполнены на данном процессоре.
6. Виртуализация
Некоторые процессоры поддерживают технологии виртуализации, которые позволяют создавать виртуальные машины и изолировать их друг от друга. Это полезно для тестирования и разработки программ, а также для обеспечения безопасности и управления ресурсами в серверных средах.
7. Параллелизм и векторные инструкции
Современные процессоры могут выполнять операции параллельно и поддерживать векторные инструкции, что увеличивает производительность при выполнении определенных задач, таких как обработка мультимедийных данных.
8. Энергопотребление
Для
мобильных и встраиваемых устройств важно энергосбережение процессора. Низкое энергопотребление позволяет увеличить автономность устройства и снизить нагрев процессора.
Заключение
Вычислительное ядро компьютера является центральным элементом, который обеспечивает выполнение всех операций и задач. Понимание характеристик и функций процессора позволяет выбирать подходящий для конкретных задач компьютер и оптимизировать работу программ.
Вопрос: действительно ли программное обеспечение использует новые наборы инструкций?
Время на прочтение7 мин
Количество просмотров17K
Со временем вендоры добавляли новые и новые инструкции в процессоры, управляющие нашими ноутбуками, серверами, телефонами и многими другими устройствами. Добавление машинных инструкций, решающих конкретные вычислительные подзадачи, является хорошим способом улучшить производительность системы в целом, не усложняя конвейер и не пытаясь нарастить частоту до запредельных величин. Одна новая инструкция, выполняющая ту же операцию, что и несколько старых, позволяет неоднократно увеличить производительность решения заданной задачи.
Новые инструкций, такие как Intel Software Guard Extensions (Intel SGX) и Intel Control-flow Enforcement Technology (Intel CET), также способны предоставить абсолютно новую функциональность.

Хороший вопрос заключается в том, как скоро новые инструкции, добавленные в архитектуру, достигают конечного пользователя. Могут ли операционные системы и другие приложения воспользоваться новыми инструкциями, принимая во внимание, что они, как правило, обеспечивают обратную совместимость и способность исполняться независимо от модели установленного процессора? Много лет назад использование новых инструкций достигалось с помощью пересборки программы под новую архитектуру и добавления проверок, предотвращающих запуск на старой аппаратуре и печатающих что-то вроде “sorry, this program is not supported on this hardware”.
Я воспользовался полноплатформенным симулятором Wind River Simics, чтобы узнать, в какой степени современное программное обеспечение способно использовать новые инструкции, оставаясь при этом совместимым со старым оборудованием.
Экспериментальная установка
Чтобы выяснить, насколько программное обеспечение может динамически адаптироваться к различному оборудования, я воспользовался Simics моделью «generic PC» платформы и двумя различными моделями процессоров: Intel Core i7 первого поколения (кодовое имя Nehalem, выпущен в конце 2008 года) и Intel Core i7 шестого поколения (кодовое имя Skylake, выпущен в середине 2015).
Исследовались следующий сценарии загрузки ОС Linux, запускаемые на описанный выше конфигурациях:
- Ubuntu 16.04, версия ядра 4.4, год выпуска 2016,
- Yocto 1.8, версия ядра 3.14, год выпуска 2014,
- Busybox с ядром 2.6.39, год выпуска 2011.
Один и тот же образ диска использовался для тестирования, тем самым гарантируя, что программный стек останется неизменным. Отличалась только конфигурация процессора в виртуальной платформе. Ожидалось, что Linux, работающий на более новом оборудовании, будет использовать новые инструкции. Каждая конфигурация запускалась с подключенным механизмом инструментации, который считал, сколько раз выполнилась каждая инструкция. Существующий в Simics механизм для инструментации не изменяет поведения гостевых приложений и позволяет изучать загрузку BIOS и ядра операционной системы за счет того, что оперирует на уровне команд процессора. При этом исполняющиеся приложение не может определить, запущено оно с инструментацией или без. Каждая конфигурация исполнялась по 60 секунд виртуального времени. Этого достаточно, чтобы загрузить BIOS и операционную систему. После каждого запуска выбиралось по 100 наиболее часто используемых инструкций, которые использовались для дальнейшего анализа.
Изучение основ идентификации процессоров
В основе данной работы лежит предположение о том, что программное обеспечения может динамически адаптировать исполняемый код в зависимости от используемого оборудования. То есть одна и та же бинарная структура может использовать различные инструкции на разном оборудовании.
Для того, чтобы понять, как работает подобная динамическая адаптация нужно разобраться с тем, как работает железо. Далеко в прошлом, когда процессоров было мало и новые модели появлялись достаточно редко, программное обеспечение могло легко проверить, происходит ли исполнение на Intel 80386 или 80486, Motorola 68020 или 68030 и адаптировать свое поведение соответствующим образом. Сейчас же существует огромное количество разнообразных систем. Для решения задачи идентификации на IA-32 процессорах следует использовать инструкцию CPUID, которая сама по себе является сложной системой, описывающей различные аспекты оборудования.
Вы, наверняка, уже встречали информацию, полученную с помощью инструкции CPUID, даже не задумываясь о ее источнике. Например, Task Manager в Microsoft Windows 8.1 показывает информация о типе процессора и некоторых других его характеристиках, которые получены с помощью инструкции CPUID:

На Linux команда «cat /proc/cpuinfo» способна показать исчерпывающую информация о процессоре, включающую флаги расширений набора команд, которые доступны в текущей системе. Каждое расширение имеет свой флаг, наличие которое программное обеспечение должно проверить перед началом исполнения. Вот пример информации, собранной на процессоре Intel Core i5 четвертого поколения:
CPUID предоставляет информацию о различных расширениях набора команд, доступных в процессоре, но как программное обеспечение на самом деле использует эти флаги для того, чтобы выбрать соответствующий бинарный код в зависимости от аппаратуры? Не разумно было бы применять «if-then-else» конструкцию в каждом месте, которое собирается использовать «нестандартные» инструкции. Достаточно сделать проверку только один раз, так как эти характеристики не изменятся в течении сессии.
Linux обычно использует указатели на функции, использующие различные инструкции для реализации одной и той же функциональности. Хороший пример можно найти в файле arch/x86/crypto/sha1_ssse3_glue.c (источник elixir.free-electrons.com/linux/v4.13.5/source):

Эти функции проверяют наличие определенной функциональности и регистрирует соответствующую hash функцию. Порядок вызова гарантирует, что будет использована наиболее эффективная реализация. Конкретно в данном случае наилучшее решение основывается на инструкциях расширения SHA-NI, но, если они не доступны, используются AVX или SSE реализации.
Результаты
Приведенный ниже график содержит результаты запуска шести разных конфигураций (два процессора и три операционные системы). Он показывает все инструкции, количество которых превышает 1% от общего числа в каком-либо запуске. «v1» означает запуск на модели Core i7 первого поколения, «v6» — шестого.

Первый вывод, который напрашивается: большинство инструкций не очень то и новые. Они скорее относятся к базовым инструкциям, добавленным еще в Intel 8086: move, compare, jump и add. Для более новых инструкций в скобочках написано название расширения, в котором они были добавлены. Всего шесть более или менее новых инструкций в списке из 28 наиболее часто используемых.
Очевидно, что присутствует вариации между различными версиями Linux вдобавок к вариациям, вызванным использованием разных процессоров. Например, BusyBox, сконфигурированный со старым ядром, использует инструкцию LEAVE, которая не является популярной для других версий ядра, к тому же он значительно меньше использует инструкцию POP. Однако это не дает ответ на вопрос, как программное обеспечение использует новые инструкции, когда они доступны. Для нашей цели наиболее интересны вариации, вызванные сменой поколения процессора при запуске одного и того же программного стека.
Все исследуемые в рамках данной работы сценарии представляют собой загрузку операционной системы Linux с различными параметрами ядра. К тому же различные дистрибутивы могут быть собраны разными версиями компилятора с использованием различных флагов. Таким образом бинарный код, даже собранный с использованием одних и тех же исходников, может отличаться.
На примере Yocto, мы видим этот эффект. Yocto использует инструкции ADCX, ADOX и MULX (входящие в расширения ADX и BMI2). Этот пример также хорошо демонстрирует скорость, с которой новые инструкции могут появиться в программном обеспечении. Эти три инструкции были добавлены в процессоре Intel Core пятого поколения, который был выпущен примерно одновременно с Linux ядром, используемым в Yocto. То есть поддержка новых инструкций была добавлена к моменту появления процессора на рынке. И это не удивительно, так как спецификация к новым инструкциям зачастую публикуется раньше, чем их аппаратная реализация. То есть программное обеспечение может заранее адаптировать свое поведение (интересная статья на эту тему) под новую аппаратуру, зачастую используя виртуальные платформы для отладки и тестирования.
Однако Ubuntu 16.04 с более новым ядром не использует ADX и BMI2, что говорит о том, что оно было сконфигурировано по-другому. Возможно, это связано с версией или флагами компилятора, параметрами ядра или набором установленных пакетов.
Изменение потока управления
Еще одна вещь, на которую было интересно обратить вникание — какие инструкции используются для изменения потока управления. Классическое правило, описанное в не менее классической книге Хеннесси и Паттерсона гласит, что каждая шестая инструкция — Jump. Однако проведенные измерения показали, что примерно одна инструкция из пяти является инструкцией, изменяющей поток управления. Ближе к одной из шести для Yocto.

Векторные инструкции
Пожалуй, наиболее известные общественности расширения набора команд — это Single Instruction Multiple Data (SIMD) или, иначе говоря, векторные инструкции. Векторные инструкции присутствуют в IA-32 процессорах, начиная с расширения MMX, добавленного в Intel Pentium в 1997 году. Сейчас наличие MMX инструкций фактически гарантировано. Можно заметить, что некоторые из них присутствуют на графике самых популярных инструкций. Далее было добавлено множество различных Streaming SIMD Extensions (SSE) инструкций и наиболее новые AVX, AVX2 и AVX512.
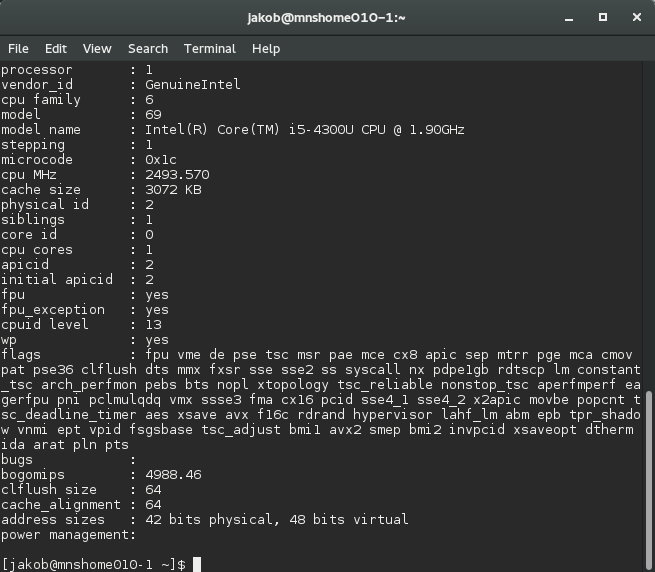
Я не ожидал большого количества векторных инструкций, учитывая, что изучалась загрузка операционной системы и BIOS. Однако примерно 5-6% исполненных инструкций оказались векторными. Количество исполненных векторных инструкций, измеренное как процент от общего количества выполненных инструкций и сгруппированное по расширениям:
Первое, что бросается в глаза — Busybox фактически не использует векторные инструкции. Следующее интересное наблюдение заключается в том, что, при смене процессора первого поколения на процессор шестого, количество более старых инструкций уменьшается, а количество новых растет. В частности, прослеживается замена старых SSE инструкций, на более новые AVX и AVX2.
Simics
Как было сказано в самом начале, провести данное исследование с помощью Simics было не сложно. Очевидным образом, Simics имеет доступ ко всем инструкциям, исполняющимся на всех процессорах в моделируемой системе (данные эксперименты проводились на двухъядерной системе, однако второе ядро не выполняло никаких инструкций во время загрузки). Сценарии были полностью автоматизированы, включаю выбор устройства, на котором установлена ОС, ввод имени пользователя и пароля в конце загрузки. Каждый сценарий запускался один раз, так как повторные запуски покажут точно такие же результаты (мы исследуем повторяющиеся сценарии, начинающиеся с одного и того же места).
Заключение
Было поучительно узнать, как программные стеки адаптируются и используют новые инструкции на более новых процессорах. Современные программы адаптивны и будут исполнять различный код в зависимости от используемой аппаратуры без перекомпиляции. Во всех изученных сценариях один и тот же программный стек использовался на разных моделируемых системах, при этом используя разные инструкции в зависимости от их доступности. Исследование представляет собой отличный пример данных, которые с легкостью могут быть получены с помощью моделирования, но едва ли могут быть собраны на реальной аппаратуре.
Содержание
- Что такое наборы инструкций SSE и что они делают?
- Что такое набор инструкций?
- Что делает набор инструкций SSE3?
- Что насчет SSE4?
- закрытие
- Технология расширений набора команд Intel®
- Технологии и инструкции, используемые в процессорах
- 3DNow!
- SSSE 3
- SSE 4.1
- SSE 4.2
- SSE4A (SSE128)
- AVX 2
- NX (XD), EVP
- AMD64, Intel64
- HT, SMT
- Аппаратная виртуализация (VT-x, VT-d, AMD-V)
- Turbo Boost, Turbo Core
- SpeedStep, PowerNow!, Cool’n’Quiet
- Intel SHA
- SenseMI
- AMD CoolCore
- AMD CoolSpeed
- AMD Enduro
- BMI, TBM, ABM
- DPM, DDPM
- SMEP, SMAP
- Что такое наборы инструкций SSE и что они делают?
- Что такое набор инструкций?
- Что делает набор инструкций SSE3?
- Что насчет SSE4?
- закрытие
Что такое наборы инструкций SSE и что они делают?

Мы довольно много слышим о наборах инструкций, причем набор инструкций x86 является одним из самых распространенных; однако наборов инструкций намного больше, чем просто x86. На самом деле существует множество наборов инструкций, специфичных для производителя, таких как набор инструкций Intel SSE3. Мы собираемся рассмотреть SSE3 специально в этом обзоре, поэтому следуйте ниже, чтобы узнать все об этом.
Что такое набор инструкций?
Чтобы понять SSE3, важно понять, что такое набор инструкций и что он делает. Набор команд, который часто называют архитектурой набора инструкций (ISA), по сути является машинным языком — языком программирования, на который компьютер может реагировать напрямую (например, двоичные или шестнадцатеричные инструкции). Тем не менее, набор инструкций в основном предоставляет инструкции или команды для процессора. Эти команды в основном говорят процессору переключаться на определенные транзисторы. Инструкции могут быть такими же простыми, как команды чтения, записи и перемещения, но они становятся гораздо более техническими, поскольку они являются основной частью компьютерной архитектуры, помогая обрабатывать типы данных, архитектуру памяти, регистры, обработку исключений, внешний ввод-вывод. О и многое другое.
Что делает набор инструкций SSE3?
Итак, что конкретно делает SSE3? SSE3 означает Потоковые SIMD-расширения 3, где «3» означает, что это третье поколение или итерация набора команд Steaming SIMD Extensions (SSE).
На более старых процессорах только один элемент данных мог быть обработан для каждой инструкции. Но с введением SSE этот набор инструкций позволяет командам обрабатывать и управлять несколькими элементами данных, что в конечном итоге значительно ускоряет обработку в определенных приложениях. В первую очередь, SSE действительно помогает, когда дело доходит до более интенсивных приложений, особенно там, где требуется трехмерная графика. Хорошим примером могут служить видеоигры, программы для редактирования видео, программное обеспечение для 3D-моделирования и множество других приложений.
Третье поколение — SSE3 — вносит одно важное изменение: способность работать горизонтально в регистре процессора. В прошлом мы были способны только на вертикальные операции. С введением этой возможности мы можем обрабатывать операции цифровой обработки сигналов (DSP) и 3D намного быстрее.
SSE3 вносит еще одно аккуратное изменение — новую инструкцию для преобразования чисел с плавающей запятой в целые числа без необходимости связываться с режимом глобального округления. Делая этот процесс более эффективным с SSE3, конвейер команд намного меньше забивается и, таким образом, избегает останова конвейера, что является задержкой в обработке инструкций, чтобы избежать опасности.
Что насчет SSE4?

SSE4 — четвертая итерация набора инструкций потокового SIMD. Этот набор инструкций содержит 54 инструкции, хотя доступно подмножество — SSE4.1, которое содержит 47 инструкций, но вы найдете его только в Penryn. Аналогичное подмножество — SSE4.2 — с остальными 7 инструкциями находится в процессоре Core i7 на базе Nehalem.
Как мы уже знаем, SSE3 (и предыдущие версии) представляют собой специальные инструкции для приложений, основанных на «мультимедиа». Вы можете смотреть на SSE4 как на новую и улучшенную версию этого, по сути, еще более оптимизированного программирования, которое позволяет выполнять задачи намного быстрее.
закрытие
Следуя этой статье, мы надеялись, что помогли вам понять некоторые технические аспекты наборов инструкций SSE3 и SSE4. Есть вопросы? Обязательно присоединяйтесь к нам в разделе комментариев ниже или позже на форумах PCMech!
Источник
Технология расширений набора команд Intel®
Тип материала Информация о продукции и документация
Идентификатор статьи 000005779
Последняя редакция 02.11.2020
Расширения набора инструкций Intel® — это дополнительные инструкции, которые могут увеличить производительность при выполнении одних и тех же операций над несколькими объектами данных.
Расширения наборов команд могут включать:
- Единая Инструкция для множественных данных (SIMD)
- Процессоры Intel® Streaming SIMD Extensions (Intel® SSE, Intel® SSE2, Intel® SSE3 и Intel® SSE4)
- Intel® Advanced Vector Extensions (Intel® AVX, Intel® AVX2 и Intel® AVX-512)
Нажмите или в теме, чтобы получить подробную информацию
Как узнать, какое расширение набора команд поддерживается в моем процессоре Intel?
- Найдите номер процессора Intel®.
- Перейдите на страницу спецификации продукции и введите номер процессоров Intel в поле поиска.
- На вкладке Advanced Technologies найдите расширения набора команд.
Как узнать, какие расширения набора команд Intel моей системы имеют? Есть ли какое бы то ни было средство, которое отображает эту информацию?
Вы можете использовать программу Intel для идентификации, нажмите на вкладку » технологии ЦП » и найдите расширения набора инструкций Intel®. См. Следующий пример:
Потоковые SIMD-расширения (SSE)
SSE — это процессорная технология, которая обеспечивает единую инструкцию для нескольких данных. Более старые процессоры обрабатывают только один элемент данных на каждой инструкции. SSE позволяет выполнять инструкции для обработки нескольких элементов данных. Она используется в ресурсоемких приложениях, таких как 3D-графика, для ускорения обработки.
SSE предназначен для замены технологии MMX™. Она расширяется по поколениям процессоров Intel®, включая SSE2, SSE3/SSE3S и SSE4. Каждая итерация привела новые инструкции и повышенную производительность.
Потоковые SIMD-расширения 2 (SSE2)
SSE2 расширяет технологии MMX и SSE Благодаря дополнению 144 инструкций, обеспечивающих повышенную производительность для широкого спектра приложений. Инструкции SIMD Integer, представленные с помощью технологии MMX, расширены с 64 на 128 бит. Это удваивает эффективную скорость выполнения операций с типом SIMD Integer.
Удвоенная точность с плавающей запятой позволяет одновременно выполнять две операции с плавающей запятой в формате SIMD. Эта поддержка для операций удвоенной точности помогает ускорить процесс создания контента, составления финансовых, инженерных и научных заявлений.
Первоначальные инструкции SSE усовершенствованы для поддержки гибкого и более высокого динамического диапазона вычислительной мощности. Это делается за счет поддержки арифметических операций над несколькими типами данных. Примерами могут служить двухбайтовые слова и четыре слова. Инструкции SSE2 позволяют разработчикам программного обеспечения обеспечить максимальную гибкость. Они могут реализовывать алгоритмы и обеспечивать повышение производительности при выполнении программного обеспечения, такого как MPEG-2, MP3 и 3D Graphics.
Потоковые SIMD-расширения 3 (SSE3)
В процессоре Intel® Pentium® 4 на базе процессоров Intel-нанометровая тактовая частота представляет собой набор потоковых SIMD-расширений 3 (SSE3), который включает 13 более команд SIMD по сравнению с SSE2.90 13 новых инструкций в основном предназначены для улучшения синхронизации потоков и определенных областей приложения, например для мультимедиа и игр.
Потоковые SIMD-расширения 4 (SSE4)
SSE4 состоит из 54 инструкций. Набор, состоящий из 47 инструкций, который называется SSE 4.1 в документации Intel, доступен в Penryn. SSE 4.2, второй набор, состоящий из семи оставшихся инструкций, впервые доступен в Nehalem-процессоре Intel® Core™ i7. Корпорация Intel имеет обратную информацию от разработчиков при разработке набора инструкций.
Intel® Advanced Vector Extensions (Intel® AVX)
Intel® AVX — это 256-разрядное расширение набора команд Intel® SSE, предназначенное для приложений с интенсивной обработкой плавающих точек (FP). Intel AVX повышает производительность из-за более широкого спектра векторов, нового расширяемого синтаксиса и обширных функциональных возможностей. Intel AVX2 был выпущен в 2013, расширяя возможности обработки векторных изображений в доменах с плавающей запятой и целочисленными данными. Это приводит к более высокой производительности и более эффективному управлению данными в широком диапазоне различных приложений. Примерами могут быть обработка изображений и аудио/видео, инженерные симуляции, финансовая аналитика, 3D-моделирование и анализ.
Intel® Advanced Vector Extensions 512 (Intel® AVX-512)
Intel® AVX-512 позволяет обрабатывать два раза больше элементов данных, которые Intel AVX/AVX2 может обрабатывать с помощью одной инструкции и в четыре раза больше возможностей Intel SSE. Инструкции Intel AVX-512 имеют важное значение, так как они открывают более высокую производительность для самых ресурсоемких вычислительных задач. Инструкции Intel AVX-512 предлагают наивысший уровень поддержки компилятора в конструкции возможностей.
Как я могу получить набор процессоров с поддержкой каждого расширения набора команд?
- Перейдите на страницу спецификации продукции.
- Нажмите кнопку Поиск продукции по компонентам, расположенным на нижнем правом краю страницы.
- В разделе выберите фильтрвыберите добавочный набор команд.
- В раскрывающемся меню отобразятся все поддерживаемые инструкции в правом поле.
- Выберите один и список процессоров, поддерживающих выбранную инструкцию ниже.
Источник
Технологии и инструкции,
используемые в процессорах
Люди обычно оценивают процессор по количеству ядер, тактовой частоте, объему кэша и других показателях, редко обращая внимание на поддерживаемые им технологии.
Отдельные из этих технологий нужны только для решения специфических заданий и в «домашнем» компьютере вряд ли когда-нибудь понадобятся. Наличие же других является непременным условием работы программ, необходимых для повседневного использования.
Так, полюбившийся многим браузер Google Chrome не работает без поддержки процессором SSE2. Инструкции AVX могут в разы ускорить обработку фото- и видеоконтента. А недавно один мой знакомый на достаточно быстром Phenom II (6 ядер) не смог запустить игру Mafia 3, поскольку его процессор не поддерживает инструкции SSE4.2.
Если аббревиатуры SSE, MMX, AVX, SIMD вам ни о чем не говорят и вы хотели бы разобраться в этом вопросе, изложенная здесь информация станет неплохим подспорьем.
В кратких описаниях ниже упор сделан только на практическую ценность технологий. Пройдя по приведенным ссылкам, можно получить более подробные сведения о каждой из них.
Аббревиатура образована от MultiMedia eXtensions (мультимедийные расширения). Это набор инструкций процессора, предназначенных для ускорения обработки фото-, аудио- и видеоданных. Разработан компанией Intel, используется в процессорах с 1997 года и на момент внедрения обеспечивал до 70% прироста производительности. Сегодня вам вряд ли удастся встретить процессор без поддержки этой технологии. Подробнее.
3DNow!
Технология впервые была использована в 1998 году в процессорах AMD и стала развитием технологии MMX, значительно расширив возможности процессора в области обработи мультимедийных данных. Ее презентацию совместили с выходом игры Quake 2, в которой 3DNow! обеспечивала до 30% прироста быстродействия. Но широкого распространения 3DNow! не получила. Сейчас она заменена другими технологиями и в новых процессорах не используется. Подробнее.
Аббревиатура от от Streaming SIMD Extensions. SIMD расшифровывается как Single Instruction Multiple Data, что значит «одна инструкция — множество данных».
SSE впервые использована в 1999 году в процессорах Pentium ІІІ и стала своеобразным ответом компании Intel на разработанную компанией AMD технологию 3DNow!, устранив некоторые ее недостатки. SSE применяется процессором, когда нужно совершить одни и те же действия над разными данными и обеспечивает осуществление до 4 таких вычислений за 1 такт, чем обеспечивает существенный прирост быстродействия.
SSE используется огромным числом приложений. Процессоров без ее поддержки сегодня уже не встретишь. Подробнее.
Этот набор инструкций был разработан компанией Intel и впервые интегрирован в процессоры Pentium 4 (2000 — 2001 гг.).
Поддержка инструкций SSE2 является обязательным условием использования современного программного обеспечения. В частности, без этого набора команд не будут работать популярные браузеры Google Chrome и Яндекс-браузер. На компьютере без SSE2 также невозможно использовать Windows 8, Windows 10, Microsoft Office 2013 и др. Подробнее.
Набор из 13 инструкций, разработанный компанией Intel и впервые использованный ею в 2004 г. в процессорах с ядром Prescott. Позволяет процессору более эффективно использовать 128-битные регистры SSE.
Инструкции SSE3 заметно упростили ряд DSP- и 3D-операций. Практическая польза от них больше всего ощущается в приложениях, связанных с обработкой потоков графической информации, аудио- и видеосигналов. Подробнее.
SSSE 3
Сокращение от «Supplemental SSE3», что значит «Дополнительный SSE3». Это набор дополнительных инструкций процессора, внедренных компанией Intel в 2006 году в продолжение развития предыдущих наборов команд SSE. По сути, это был четвертый по счету набор инструкций SSE. Но в Intel решили иначе, возможно, посчитав его лишь незначительным дополнением к предыдущему пакету.
Инструкции SSSE3 необходимы для нормальной работы многих современных приложений, в частности программ распознавания речи, используемых алгоритм DNN (Deep Neural Network). Подробнее.
SSE 4.1
Набор инструкций, разработанный компанией Intel. Используется в процессорах с 2006 года.
SSE 4.1 в значительной степени повышает эффективность процессора при компиляторной векторизации обработки данных, работе с трехмерной графикой и в играх, обработке изображений, видеоинформации и другого мультимедийного контента. Подробнее.
SSE 4.2
Набор инструкций процессора, включающий 7 команд обработки строк, подсчета CRC32 и популяции единичных бит, а также работы с векторными примитивами. Впервые использован компанией Intel в 2008 году.
На практике инструкции SSE 4.2 повышают производительность при сканировании вирусов, поиска текста, строковой обработки библиотек (ZLIB, базы данных и др.), обработки 3D информации. Подробнее.
SSE4A (SSE128)
Набор инструкций, используемый в процессорах AMD с 2007 года. Включает всего 4 команды (инструкции, ускоряющие подсчет числа нулевых/единичных битов, комбинированные инструкции маскирования и сдвига, а также скалярные инструкции потоковой записи).
Аналогичные инструкций есть также в наборе SSE 4 (4.1, 4.2.) от Intel, который является значительно более эффективным (в общей сложности 54 инструкции), см. выше. Подробнее.
Расширение системы команд процессора, разработанное в 2008 году компанией Intel с целью ускорения работы и повышения уровня защищенности программ, использующих алгоритм шифрования AES (Advanced Encryption Standard).
В США и некоторых других странах AES является официальным стандартом шифрования. Используется операционной системой Windows и многими популярными программами для защиты конфиденциальной информации (The Bat!, TrueCrypt и др.). Если процессор поддерживает инструкции AES, прирост производительности приложений, использующих этот алгоритм, может достигать 1200 %. Подробнее.
Аббревиатура образована от Advanced Vector Extensions. Это расширение системы команд процессора, разработанное компанией Intel в 2008 году. Оказывает большое влияние на мультимедийные и вычислительные возможности процессора.
Кроме набора новых инструкций, эта технология предусматривает двукратное увеличение размеров SIMD-регистров процессора, благодаря чему в интенсивных вычислениях за каждый такт он может обрабатывать до 2 раз больше информации.
Значительный прирост производительности наблюдается при работе с фото-, видеоконтентом, решении научных задач и др.). Но для этого требуется также использование соответствующей операционной системы и адаптированного программного обеспечения. В Windows поддержка AVX появилась, только начиная с Windows 7 SP1. Подробнее.
AVX 2
Набор инструкций, ставший развитием технологии AVX. Впервые использован в 2013 г. в процессорах Intel на ядре Haswell.
Практическая польза для рядового пользователя — прирост производительности при работе с видео, фотографиями, звуком, а также с программами, использующими алгоритмы распознавания голоса, лиц, жестов (при условии использования соответствующего программного обеспечения). Подробнее.
Набор инструкций процессора, ускоряющий операции умножения-сложения чисел с плавающей запятой. Аббревиатура FMA образована от англ. Fused Multiply-Add, что переводится как умножение-сложение с однократным округлением.
Операции умножения-сложения очень распространены и играют важную роль в работе вычислительной техники. Особенно, когда речь идет о цифровой обработке аналоговых сигналов (двоичное кодирование видео, звука и другие подобные операции). В связи с этим, поддержка инструкций FMA внедрена не только в центральные процессоры, но и в графические процессоры многих современных видеокарт. Подробнее.
NX (XD), EVP
Технологии NX (XD) и EVP, не смотря на разные названия, являются одним и тем же — важным компонентом любого современного процессора, обеспечивающим повышенную защиту компьютера от вирусов и хакерских атак, основанных на механизме переполнения буфера.
Названия NX (No Xecute) и XD (eXecute Disable) характерны для процессоров Intel. EVP (Enhanced Virus Protection) — для процессоров AMD. Подробнее.
AMD64, Intel64
AMD64, Intel64, EM64T, x86-64, x64, Hammer Architecture — все эти термины обозначают одно и то же — 64-битную архитектуру центрального процессора, разработанную и внедренную в 2003 году компанией AMD. До этого процессоры были 32-битными.
Для обычного пользователя главным преимуществом 64-битного процессора является возможность использования в компьютере 64-битного программного обеспечения и большого объема оперативной памяти (теоретически, до 16777216 терабайт). Максимальное количество оперативной памяти, которое может адресовать 32-битный процессор — 4 ГБ. Подробнее.
XOP (от англ. eXtended operation — «расширенная операция») — это набор инструкций микропроцессора, повышающих его быстродействие при работе с мультимедиа, а также при решении научных задач.
Инструкции XOP впервые использованы в 2011 году в процессорах AMD архитектуры Bulldozer. В этот набор входит несколько различных типов векторных инструкций, большинство из которых являются целочисленными. Однако, есть среди них также инструкции для перестановки чисел с плавающей запятой и инструкции экстракции дробной части. Подробнее.
HT, SMT
В процессорах Intel технология многопоточности называется Hyper-Threading (HT), в процессорах AMD — Simultaneous MultiThreading (SMT).
Кроме названий, эти технологии отличаются еще и многими аспектами реализации. Однако, суть их одинакова. HT и SMT повышают эффективность использования вычислительных возможностей процессора (в среднем, на 20 — 30 %) за счет параллельного выполнения каждым его ядром двух потоков вычислений. Подробнее.
Аппаратная виртуализация (VT-x, VT-d, AMD-V)
Аппаратная виртуализация значительно расширяет возможности работы компьютера с виртуальными машинами, позволяя использовать гостевые операционные системы изолировано от основной (хостовой) системы.
Кроме того, появляется возможность «проброса» в гостевую систему устройств ввода-вывода, подключаемых к компьютеру через шину PCI и некоторые другие шины (видеокарты, звуковые карты, сетевые адаптеры и др.). Подробнее.
Turbo Boost, Turbo Core
Turbo Boost и Turbo Core — похожие по своей сути технологии, автоматически повышающие тактовую частоту процессора выше номинальной, когда в этом есть необходимость. Turbo Boost используется в процессорах Intel, Turbo Core — в процессорах AMD. В целом, они обеспечивают значительный прирост быстродействия в большинстве приложений.
Несмотря на одинаковое предназначение, Turbo Boost и Turbo Core существенно отличаются. Подробнее.
TXT (англ. Trusted eXecution Technology — технология доверенного выполнения) — разработанная компанией Intel и используемая в ее процессорах технология, обеспечивающая аппаратную защиту компьютера от вредоносных программ.
Это абсолютно новая концепция безопасности. В ее основе лежит эксклюзивное использование части ресурсов компьютера каждым конкретным приложением. Она охватывает практически все подсистемы компьютера: выделение памяти, мониторинг системных событий, связь чипсета и памяти, хранение данных, устройства ввода (клавиатура и мышь), вывод графической информации. Подробнее.
TSX (Transactional Synchronization eXtensions) — набор инструкций многоядерного процессора, разработанный компанией Intel, который повышает эффективность взаимодействия ядер между собой при осуществлении общего доступа к одним и тем же данным и, в конечном счете, увеличивает общую производительность компьютера. Подробнее.
SpeedStep, PowerNow!, Cool’n’Quiet
Принцип действия этих технологий состоит в автоматическом снижении частоты процессора, а вследствие — потребляемой им энергии и выделяемого тепла, в периоды, когда компьютер не выполняет никаких задач или когда сложность этих задач является незначительной.
Это особенно важно для мобильных устройств, расход заряда аккумулятора которых существенно уменьшается. В настольных системах самым ощутимым моментом является снижение шума системы охлаждения процессора. Подробнее.
Memory Protection Extensions — технология, обеспечивающая повышенную защиту компьютера от вирусных и других угроз, использующих механизм переполнения буфера.
Процессор получает возможность дополнительно проверять границы буферов стека и буферов кучи перед доступом к памяти, чтобы приложение, обращающееся к памяти, имело доступ лишь к той ее области, которая ему назначена. Вследствие этого хакеру или вредоносной программе становится значительно сложнее через память «подставлять» процессору свой код. Подробнее.
Software Guard Extensions (SGX) — набор инструкций, разработанный компанией Intel и используемый в ее процессорах, начиная с архитектуры Skylake.
SGX позволяет организовать защищённые участки кода и данных (так называемые «анклавы»), обеспечивающие высокий уровень защиты работающих с ними программ от вредоносных приложений и хакерских атак. Подробнее.
Intel SHA
Intel Secure Hash Algorithm extensions (SHA) — набор инструкций процессора, разработанных компанией Intel для ускорения работы приложений, используемых алгоритмы шифрования SHA. Включает 7 инструкций, 4 из которых ускоряют работу SHA-1, остальные 3 — SHA-256. Ускорение может составлять 150-200 % и более (в зависимости конкретного приложения).
Эти алгоритмы используются в системах контроля версий и электронных подписей, а также для построения кодов аутентификации. SHA-1 является более распространённым и применяется в самых разнообразных криптографических программах. Подробнее.
Advanced Configuration and Power Interface (ACPI) — стандарт, разработанный компаниями HP, Intel, Microsoft, Phoenix и Toshiba. Используется в компьютерной технике с 1996 года, постепенно дополняясь и совершенствуясь. Определяет общий подход к управлению питанием и обеспечивает взаимодействие между устройствами компьютера, его операционной системой и BIOS/UEFI в целях снижения уровня энергопотребления.
Стандарт ACPI предусматривает несколько режимов работы процессора. В зависимости от модели, они могут поддерживаться процессором в полном объеме или только какая-то их часть. Подробнее.
System Management Mode (SMM) — режим, при котором процессор приостанавливает исполнение любого кода (в том числе и операционной системы) и запускает специальную программу, хранящуюся в зарезервированной области оперативной памяти.
Процессор переводится в режим SMM не программным обеспечением, а после поступления сигнала, генерируемого при наступлении определенных событий специальными схемами материнской платы. Нужен для решения некоторых важных задач, таких как обработка ошибок памяти и чипсета материнской платы, защита процессора от перегрева путем выключения компьютера и др. Подробнее.
Dynamic Front Side Bus Frequency Switching (DFFS) — одна из технологий снижения энергопотребления компьютерных систем. Она позволяет операционной системе компьютера, в зависимости от нагрузки, которую он испытывает, понижать частоту системной шины FSB, что влечет за собой также и снижение частоты процессора. Подробнее.
SenseMI
SenseMI — технология, разработанная компанией AMD и впервые использованная в процессорах серии Ryzen. Она представляет собой комплекс из нескольких взаимосвязанных компонентов, обеспечивающих оптимальную производительность и энергоэффективность путем прогнозирования программного кода, а также динамического изменения частоты процессора в соответствии с решаемыми задачами в каждый конкретный момент времени (Smart Prefetch, Neural Net Prediction, Pure Power, Precision Boost, Extended Frequency Range).
Некоторые из упомянутых компонентов, по сути, являются усовершенствованными вариантами технологий, используемых в предыдущих моделях процессоров AMD. Подробнее.
AMD CoolCore
AMD CoolCore — технология, осуществляющая временное отключение неиспользуемых блоков процессора в целях снижения энергопотребления и выделяемого им тепла. Впервые использована в процессорах Phenom. Подробнее.
AMD CoolSpeed
AMD CoolSpeed — технология, разработанная компанией AMD для защиты процессора от перегрева путем понижения частоты и напряжение питания. Подробнее.
AMD Enduro
AMD Enduro — технология, позволяющая переключать компьютер, оснащенный двумя графическими решениями, с одного устройства на другое, в зависимости от решаемых в конкретный момент времени задач. Поддерживается видеокартами AMD, а также гибридными (имеющими встроенное графическое ядро) процессорами этой компании.
Ценной Enduro является для мобильных компьютеров, поскольку позволяет существенно экономить заряд аккумулятора. Подробнее.
BMI, TBM, ABM
Bit Manipulation Instructions (BMI) — наборы инструкций, используемые в процессорах Intel и AMD для ускорения операций, связанных с манипулированием битами.
Операции манипулирования битами чаще всего используется приложениями, предназначенными для низкоуровневого управления устройствами, обнаружения и исправления ошибок, оптимизации, сжатия и шифрования данных. Использование BMI программами значительно ускоряет эти операции (иногда в несколько раз), однако, код программ становится более сложным для написания программистами. Подробнее.
DPM, DDPM
Dynamic Power Management и Dual Dynamic Power Management- технологии автоматического динамического изменения питания процессора. В совокупности с другими энергосберегающими технологиями, они значительно повышают его энергоэффективность, снижая уровень питания в периоды простоя или незначительных загрузок и повышая его, когда это необходимо. Подробнее.
SMEP, SMAP
Supervisor Mode Execution Prevention и Supervisor Mode Access Prevention — технологии, разработанные компанией Intel для защиты компьютера от хакерских атак и других угроз, использующих так называемый «режим супервизора». Подробнее.
F16C — набор инструкций, используемый в процессорах архитектуры x86 для ускорения преобразований между двоичными числами половинной точности (16 bit) и стандартными двоичными числами с плавающей запятой одинарной точности (32 bit).
F16C используется как в процессорах AMD, так и в процессорах Intel, значительно расширяя их возможности в плане работы с мультимедийными данными, а также данными других типов. Подробнее.
НАПИСАТЬ АВТОРУ
Источник
Что такое наборы инструкций SSE и что они делают?
Мы довольно много слышим о наборах инструкций, причем набор инструкций x86 является одним из самых распространенных; однако наборов инструкций намного больше, чем просто x86. На самом деле существует множество наборов инструкций, специфичных для производителя, таких как набор инструкций Intel SSE3. Мы собираемся рассмотреть SSE3 специально в этом обзоре, поэтому следуйте ниже, чтобы узнать все об этом.
Что такое набор инструкций?
Чтобы понять SSE3, важно понять, что такое набор инструкций и что он делает. Набор команд, который часто называют архитектурой набора инструкций (ISA), по сути является машинным языком — языком программирования, на который компьютер может реагировать напрямую (например, двоичные или шестнадцатеричные инструкции). Тем не менее, набор инструкций в основном предоставляет инструкции или команды для процессора. Эти команды в основном говорят процессору переключаться на определенные транзисторы. Инструкции могут быть такими же простыми, как команды чтения, записи и перемещения, но они становятся гораздо более техническими, поскольку они являются основной частью компьютерной архитектуры, помогая обрабатывать типы данных, архитектуру памяти, регистры, обработку исключений, внешний ввод-вывод. О и многое другое.
Что делает набор инструкций SSE3?
Итак, что конкретно делает SSE3? SSE3 означает Потоковые SIMD-расширения 3, где «3» означает, что это третье поколение или итерация набора команд Steaming SIMD Extensions (SSE).
На более старых процессорах только один элемент данных мог быть обработан для каждой инструкции. Но с введением SSE этот набор инструкций позволяет командам обрабатывать и управлять несколькими элементами данных, что в конечном итоге значительно ускоряет обработку в определенных приложениях. В первую очередь, SSE действительно помогает, когда дело доходит до более интенсивных приложений, особенно там, где требуется трехмерная графика. Хорошим примером могут служить видеоигры, программы для редактирования видео, программное обеспечение для 3D-моделирования и множество других приложений.
Третье поколение — SSE3 — вносит одно важное изменение: способность работать горизонтально в регистре процессора. В прошлом мы были способны только на вертикальные операции. С введением этой возможности мы можем обрабатывать операции цифровой обработки сигналов (DSP) и 3D намного быстрее.
SSE3 вносит еще одно аккуратное изменение — новую инструкцию для преобразования чисел с плавающей запятой в целые числа без необходимости связываться с режимом глобального округления. Делая этот процесс более эффективным с SSE3, конвейер команд намного меньше забивается и, таким образом, избегает останова конвейера, что является задержкой в обработке инструкций, чтобы избежать опасности.
Что насчет SSE4?
SSE4 — четвертая итерация набора инструкций потокового SIMD. Этот набор инструкций содержит 54 инструкции, хотя доступно подмножество — SSE4.1, которое содержит 47 инструкций, но вы найдете его только в Penryn. Аналогичное подмножество — SSE4.2 — с остальными 7 инструкциями находится в процессоре Core i7 на базе Nehalem.
Как мы уже знаем, SSE3 (и предыдущие версии) представляют собой специальные инструкции для приложений, основанных на «мультимедиа». Вы можете смотреть на SSE4 как на новую и улучшенную версию этого, по сути, еще более оптимизированного программирования, которое позволяет выполнять задачи намного быстрее.
закрытие
Следуя этой статье, мы надеялись, что помогли вам понять некоторые технические аспекты наборов инструкций SSE3 и SSE4. Есть вопросы? Обязательно присоединяйтесь к нам в разделе комментариев ниже или позже на форумах PCMech!
Источник